

Best Practices für die Bereitstellung des Hadoop -Servers auf CentOS/RHEL 7 - Teil 1

- 2894
- 426
- Susanne Stoutjesdijk
In dieser Artikelserie werden wir das gesamte behandeln Cloudera Hadoop Cluster Building Bau mit Verkäufer Und Industriell Empfohlene Best Practices.
Teil 1: Best Practices für die Bereitstellung des Hadoop -Servers auf CentOS/RHEL 7 Teil 2: Einrichten von Hadoop-Voraussetzungen und Sicherheitshärten Teil 3: So installieren und konfigurieren Sie den Cloudera -Manager auf CentOS/RHEL 7 Teil 4: So installieren Sie CDH und konfigurieren Sie Serviceplatzierungen auf CentOS/RHEL 7 Teil 5: So richten Sie eine hohe Verfügbarkeit für Namenode ein Teil 6: So richten Sie eine hohe Verfügbarkeit für Ressourcenmanager ein Teil 7: So installieren und konfigurieren Sie Hive mit hoher Verfügbarkeit und Konfiguration Teil 8: So installieren und konfigurieren Sie Sentry (Autorisierungstool) Teil 9: So installieren Sie Kerberos (Kerberising the Cluster) zur Hadoop -Authentifizierung Teil 10: Wie man Cluster (Garnsteuer) auf CentOS/RHEL 7 stimmtBetriebssystem Installation und Tun Betriebssystem Level-Voraussetzungen sind die ersten Schritte, um a zu bauen Hadoop -Cluster. Hadoop kann auf dem verschiedenen Geschmack der Linux -Plattform laufen: Centos, Roter Hut, Ubuntu, Debian, Suse usw., In Echtzeitproduktion die meisten der Hadoop -Cluster sind oben aufgebaut Rhel/Centos, wir werden verwenden Centos 7 zur Demonstration in dieser Reihe von Tutorials.
In einer Organisation kann die Betriebssysteminstallation verwendet werden Kickstart. Wenn es sich um einen 3 bis 4 Knotencluster handelt, ist eine manuelle Installation möglich, aber wenn wir einen großen Cluster mit mehr als 10 Knoten erstellen, ist es mühsam, OS einzeln zu installieren. In diesem Szenario kommt die KickStart -Methode ins Bild. Wir können mit der Masseninstallation mit Kickstart fortfahren.
Gute Leistung von a erzielen Hadoop -Umgebung hängt von der Bereitstellung der richtigen Hardware und Software ab. Also, eine Produktion aufbauen Hadoop -Cluster beinhaltet eine große Überlegung in Bezug auf Hardware und Software.
In diesem Artikel werden wir verschiedene Benchmarks über die Betriebssysteminstallation und einige Best Practices für die Bereitstellung durchlaufen Cloudera Hadoop Cluster Server An CentOS/Rhel 7.
Wichtige Überlegungen und Best Practices für die Bereitstellung des Hadoop -Servers
Im Folgenden finden Sie die besten Verfahren für die Einrichtung der Bereitstellung Cloudera Hadoop Cluster Server An CentOS/Rhel 7.
- Hadoop -Server benötigen keine Unternehmens -Standardserver, um einen Cluster zu erstellen, sondern erfordert Warenhardware.
- Im Produktionscluster werden 8 bis 12 Datenplatten empfohlen. Nach der Art der Arbeitsbelastung müssen wir uns dafür entscheiden. Wenn der Cluster für rechenintensive Anwendungen bestimmt ist, ist 4 bis 6 Laufwerke bewährt, um E/A-Probleme zu vermeiden.
- Datenantriebe sollten zum Beispiel einzeln partitioniert werden - beginnend von ab /Data01 Zu /Data10.
- RAID. So Jbod ist am besten für Arbeiterknoten.
- Für Master -Server, Überfall 1 ist die beste Praxis.
- Das Standard -Dateisystem auf CentOS/Rhel 7.X Ist Xfs. Hadoop unterstützt XFS, EXT3 und EXT4. Das empfohlene Dateisystem ist ext3, da es auf eine gute Leistung getestet wird.
- Alle Server sollten dieselbe Betriebssystemversion haben, mindestens die gleiche kleine Veröffentlichung.
- Es ist die beste Praxis, homogene Hardware zu haben (alle Arbeiterknoten sollten die gleichen Hardware -Eigenschaften haben (RAM, Speicherplatz & Kern usw.).
- Gemäß der Cluster -Arbeitsbelastung (ausgewogene Workload, Berechnung intensiv, I/A -Intensiv) und Größe, Ressourcen (RAM, CPU) -Planierung pro Server wird unterschiedlich sein.
Suchen Sie das folgende Beispiel für die Festplattenpartitionierung der Server von 24 TB Speicherplatz.
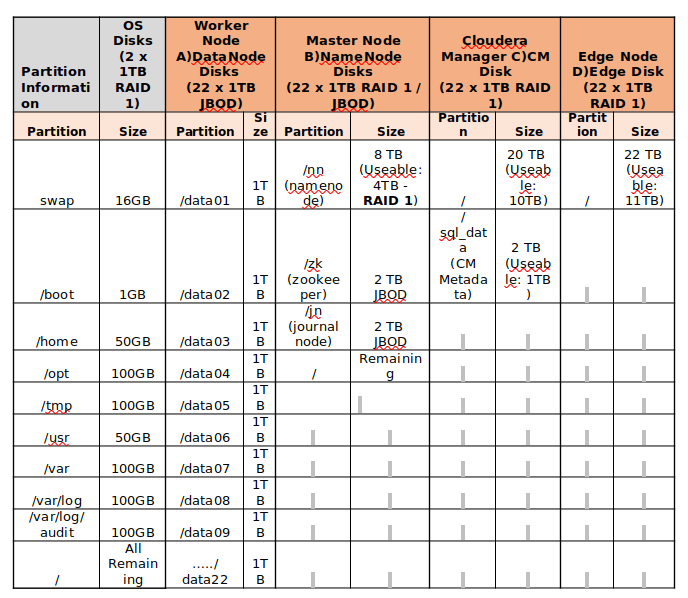 Festplattenpartitionierung
Festplattenpartitionierung Installieren von CentOS 7 für die Hadoop -Server -Bereitstellung
Dinge, die Sie vor der Installation wissen müssen Centos 7 Server für Hadoop -Server.
- Die minimale Installation reicht für Hadoop -Server (Arbeiterknoten) In einigen Fällen kann GUI nur für Master -Server oder Verwaltungsserver installiert werden, bei denen wir Browser für Web -UIs von Management -Tools verwenden können.
- Konfigurieren von Netzwerken, Hostnamen und anderen Betriebssystemeinstellungen können nach der Betriebssysteminstallation durchgeführt werden.
- In Echtzeit haben Serveranbieter eine eigene Konsole, um die Server zu interagieren und zu verwalten, z. Mit dieser IDRAC -Schnittstelle können wir das Betriebssystem mit einem Betriebssystem -Bild in unserem lokalen System installieren.
In diesem Artikel haben wir das Betriebssystem installiert (Centos 7) In VMware Virtual Machine. Hier haben wir nicht mehrere Festplatten, um Partitionen durchzuführen. CentOS ist ähnlich wie Rhel (gleiche Funktionalität), sodass wir die zu installierenden Schritte sehen Centos.
1. Beginnen Sie mit dem Herunterladen der CentOS 7.X ISO -Bild in Ihrem lokalen Windows -System und wählen Sie es beim Booten der virtuellen Maschine aus. Wählen 'Installieren Sie CentOs 7' wie gezeigt.
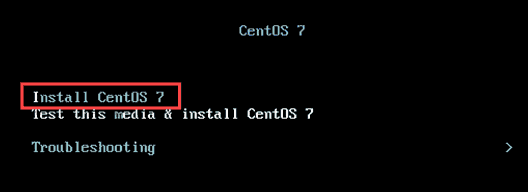 Installieren Sie das CentOS 7 -Boot -Menü
Installieren Sie das CentOS 7 -Boot -Menü 2. Wähle aus Sprache, Standard wird sein Englisch, und klicken Sie weitermachen.
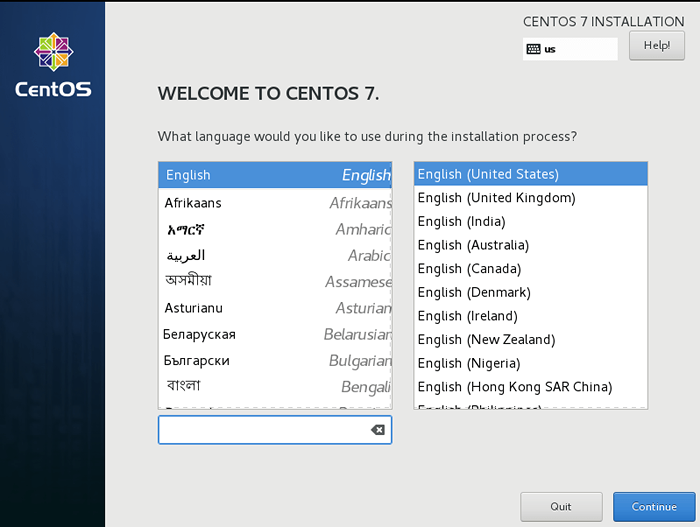 Wählen Sie CentOS 7 Sprache
Wählen Sie CentOS 7 Sprache 3. Softwareauswahl - Wähle aus 'Minimale Installation"Und klicken Sie"Erledigt''.
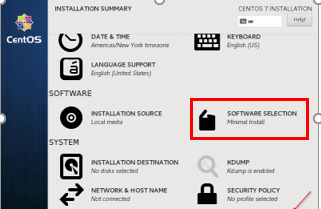 CentOS -Softwareauswahl
CentOS -Softwareauswahl 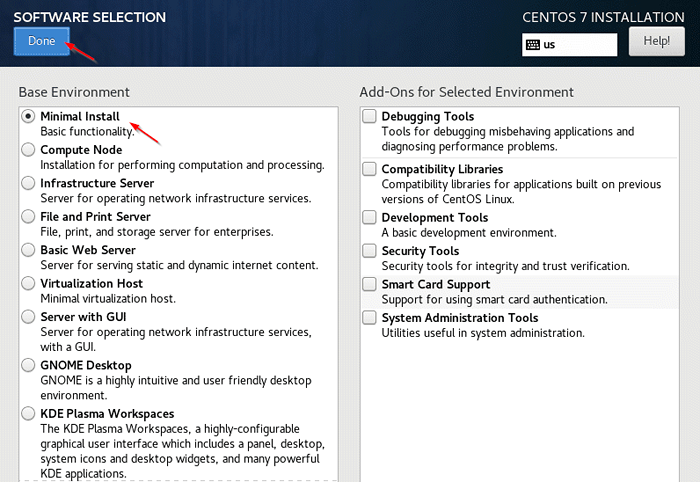 CentOS 7 minimale Installation
CentOS 7 minimale Installation 4. Setzen Sie die Root Passwort wie es uns zum Setzen veranlasst.
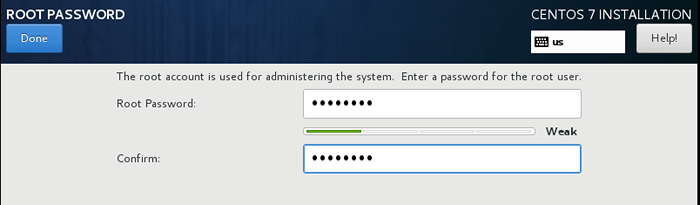 Stellen Sie das Root -Passwort fest
Stellen Sie das Root -Passwort fest 5. Installationsziel - Dies ist der wichtige Schritt, um vorsichtig zu sein. Wir müssen die Festplatte auswählen, auf der das Betriebssystem installiert werden muss, dedizierte Scheibe sollte für das Betriebssystem ausgewählt werden. Drücke den 'Installationsziel"Und wählen Sie die Festplatte aus, in Echtzeit werden mehrere Festplatten vorhanden sein. Wir müssen auswählen, vorzuziehen."SDA''.
 Wählen Sie das Installationsziel
Wählen Sie das Installationsziel 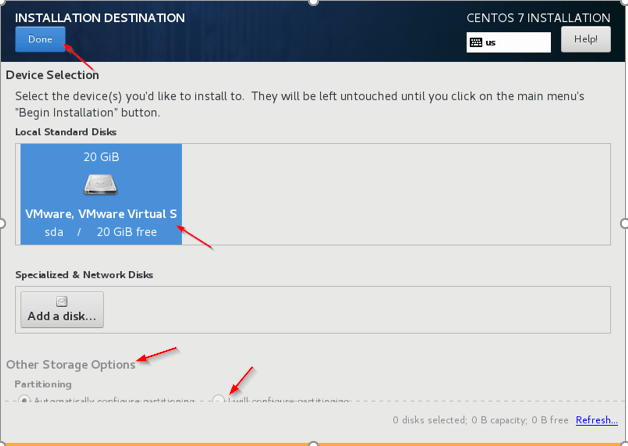 Wählen Sie die Festplatte für die CentOS -Installation aus
Wählen Sie die Festplatte für die CentOS -Installation aus 6. Andere Speicheroptionen - Wählen Sie die zweite Option (ich werde die Partitionierung konfigurieren) für die Konfiguration von OS -verwandten Partitionierung /var, /var/log, /heim, /tmp, /opt, /Tausch.
 Handbuch Centos Partitioning
Handbuch Centos Partitioning 7. Beginnen Sie nach Abschluss mit der Installation.
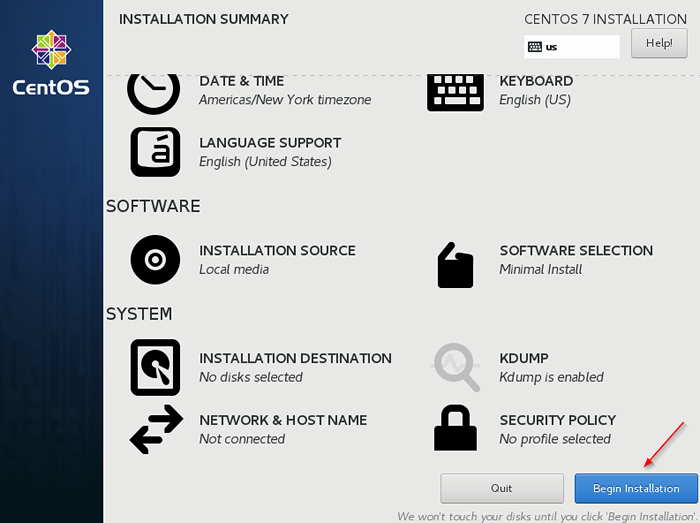 Beginnen Sie die CentOS -Installation
Beginnen Sie die CentOS -Installation 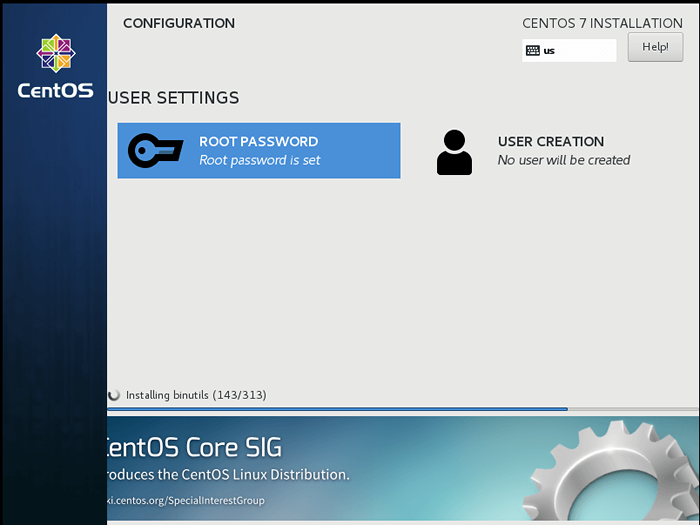 CentOS 7 Installation
CentOS 7 Installation 8. Sobald die Installation abgeschlossen ist, starten Sie den Server neu.
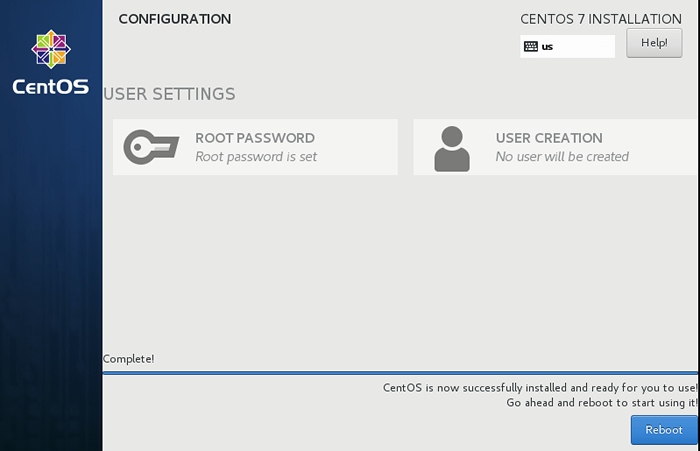 CentOS 7 Installation vollständig
CentOS 7 Installation vollständig 9. Melden Sie sich in den Server an und setzen Sie den Hostnamen fest.
# Hostnamectl Status # hostnamectl set-hostname tecmint # hostnamectl Status
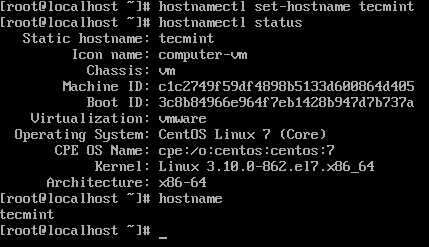 Hostname auf CentOS festlegen
Hostname auf CentOS festlegen Zusammenfassung
In diesem Artikel haben wir die Installationsschritte und Best Practices für die Dateisystem -Partitionierung durchlaufen. Dies sind alle allgemeine Richtlinien, je nach Art der Arbeitsbelastung müssen wir uns möglicherweise auf mehr Nuancen konzentrieren, um die beste Leistung des Clusters zu erzielen. Clusterplanung ist Kunst für die Hadoop Administrator. Wir werden im nächsten Artikel einen tiefen Eintauchen in die Voraussetzungen der OS-Ebene und die Sicherheitshärtung haben.
- « So teilen Sie den VIM -Bildschirm horizontal und vertikal unter Linux auf
- 10 Open -Source -API -Gateways und Management -Tools »