

GNU/Linux Allgemeiner Fehlerbehebungsleitfaden für Anfänger

- 1219
- 324
- Susanne Stoutjesdijk
In diesem Leitfaden ist es unser Ziel, die Tools und die Umgebung eines typischen GNU/Linux -Systems zu erfahren, um die Fehlerbehebung selbst auf einer unbekannten Maschine zu starten zu können.
In diesem Tutorial lernen Sie:
- So überprüfen Sie den Speicherplatz
- So überprüfen Sie die Speichergröße
- So überprüfen Sie die Systemlast
- So finden und töten Sie Systemprozesse
- So werden Sie Benutzer anmelden, um relevante System -Fehlerbehebungsinformationen zu finden
GNU/Linux Allgemeiner Fehlerbehebungsleitfaden für Anfänger Softwareanforderungen und Konventionen verwendet
| Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Ubuntu 20.04, Fedora 31 |
| Software | N / A |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
Einführung
Während GNU/Linux für seine Stabilität und Robustheit bekannt ist, gibt es Fälle, in denen etwas schief gehen kann. Die Quelle des Problems kann sowohl intern als auch extern sein. Zum Beispiel kann es einen fehlerhaften Prozess geben, der auf dem System ausgeführt wird, das Ressourcen auffrischt, oder eine alte Festplatte kann fehlerhaft sein, was zu gemeldeten I/A -Fehlern führt.
In jedem Fall müssen wir wissen, wo wir suchen und was zu tun ist, um Informationen über die Situation zu erhalten. Die Lösung eines Problems beginnt damit, das Problem zu kennen, die Details zu finden, die Grundursache zu finden und es zu lösen. Wie bei jeder Aufgabe bietet GNU/Linux unzählige Tools, um den Fortschritt zu unterstützen, dies ist auch bei der Fehlerbehebung der Fall. Die folgenden Tipps und Methoden sind nur einige häufige, die bei vielen Verteilungen und Versionen verwendet werden können.
Symptome
Angenommen, wir haben einen schönen Laptop, an dem wir arbeiten. Es führt die neuesten Ubuntu-, CentOS- oder Red Hat Linux mit, wobei die Updates immer vorhanden sind, um alles frisch zu halten. Der Laptop dient für den alltäglichen allgemeinen Gebrauch: Wir verarbeiten E -Mails, chatten, durchsuchen im Internet, produzieren vielleicht einige Tabellenkalkulationen usw. Nichts Besonderes ist installiert, eine Office -Suite, ein Browser, ein E -Mail -Client usw. Von einem Tag zum anderen wird die Maschine plötzlich extrem langsam. Wir arbeiten bereits ungefähr eine Stunde daran, daher ist es kein Problem nach dem Start. Was ist los… ?
Systemressourcen überprüfen
GNU/Linux wird ohne Grund nicht langsam. Und wird uns höchstwahrscheinlich sagen, wo es weh tut, solange es antworten kann. Wie bei jedem Programm, das auf einem Computer ausgeführt wird, verwendet das Betriebssystem Systemressourcen, und bei den Dicken müssen die Vorgänge warten, bis genug von ihnen vorhanden ist, um fortzufahren, um fortzufahren. Dies führt in der Tat zu Antworten, um immer langsamer und langsamer zu werden. Wenn also ein Problem besteht. Im Allgemeinen bestehen unsere (lokalen) Systemressourcen aus Festplatte, Speicher und CPU. Lassen Sie uns alle überprüfen.
Festplattenplatz
Wenn das laufende Betriebssystem keinen Speicherplatz mehr hat, sind das schlechte Nachrichten. Wenn Dienste, die ausgeführt werden. Abgesehen von Protokolldateien müssen Sockets und PID -Dateien (Process Identifier) auf der Festplatte geschrieben werden, und obwohl diese gering sind, können diese, wenn es absolut keinen Platz mehr gibt, nicht erstellt werden.
Um den verfügbaren Speicherplatz zu überprüfen, können wir nutzen df im Terminal und hinzufügen -H Argument, um die Ergebnisse auf Megabyte und Gigabyte abgerundet zu sehen. Für uns wären die Zinseinträge Volumina, die% von 100% verwendet haben. Das würde bedeuten, dass der fragliche Volumen voll ist. Das folgende Beispielausgang zeigt, dass wir in Bezug auf den Speicherplatz in Ordnung sind:
$ df -h Dateisystemgröße verwendet UVE VERWENDEN SIE VER UNTERGRÜNDE.8g 0 1.8g 0% /dev tmpfs 1.8g 0 1.8G 0% /Dev /SHM TMPFS 1.8g 1.3m 1.8G 1% /Run /Dev /Mapper /LV-Root 49G 11G 36G 24% /TMPFS 1.8g 0 1.8G 0% /TMP /Dev /SDA2 976m 261m 649 m 29% /Boot /Dev /Mapper /LV-Home 173G 18G 147G 11% /Home TMPFS 361M 4.0k 361m 1%/run/user/1000Wir haben also Platz auf Scheiben (en). Beachte. Wenn die Festplatten voll sind, stürzen die Programme ab oder beginnen überhaupt nicht. Im extremen Fall schlägt sogar Anmeldung nach dem Start fehl.
Speicher
Speicher ist auch eine wichtige Ressource, und wenn wir es nicht haben Es ist zurück, wenn der Prozess, der den ausgetauschten Inhalt besitzt. Diese ganze Methode, die als Austausch namen.
Um den Speicherverbrauch zu überprüfen, haben wir das Handy frei Befehl, dass wir Argumente anhängen können, um die Ergebnisse in Megabyte zu sehen (-M) oder Gigabyte (-G):
$ kostenlos -m Gesamt gebrauchter kostenloser freigegebener Buff/Cache verfügbar MEM: 7886 3509 1547 1231 2829 2852 Swap: 8015 0 8015Im obigen Beispiel haben wir 8 GB Speicher, 1,5 GB frei und etwa 3 GB in Caches. Der frei Der Befehl liefert auch den Zustand der Tausch: In diesem Fall ist es vollkommen leer, was bedeutet. Dies bedeutet normalerweise, dass wir mehr Speicher haben, den wir tatsächlich verwenden. In Bezug auf die Erinnerung sind wir mehr als nützlich, wir haben viel davon.
Systemlast
Da die Prozessoren die tatsächlichen Berechnungen durchführen, kann es erneut zu einer Verlangsamung des Systems führen. Die erforderlichen Berechnungen müssen warten, bis ein Prozessor die Freizeit hat, um sie zu berechnen. Der einfachste Weg, die Ladung unserer Prozessoren zu sehen, ist die Betriebszeit Befehl:
$ UPTIME 12:18:24 UP 4:19, 8 Benutzer, Lastdurchschnitt: 4,33, 2.28, 1,37Die drei Zahlen nach dem Lastdurchschnitt bedeutet durchschnittlich in den letzten 1, 5 und 15 Minuten. In diesem Beispiel hat die Maschine 4 CPU -Kerne, daher versuchen wir, mehr als unsere tatsächliche Kapazität zu verwenden. Beachten Sie auch, dass die historischen Werte zeigen, dass die Last in den letzten Minuten erheblich steigt. Vielleicht haben wir den Täter gefunden?
Top -Verbraucherprozesse
Lassen Sie uns das gesamte Bild von CPU und Speicherkonsum sehen, wobei die Top -Prozesse diese Ressourcen verwenden. Wir können die ausführen Spitze Befehl zur Sichtweise des Systems (in der Nähe) in Echtzeit:
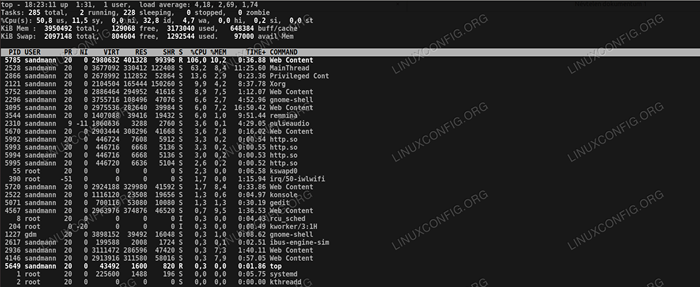 Überprüfung der Top -Verbraucherprozesse.
Überprüfung der Top -Verbraucherprozesse. Die erste Oberseite ist identisch mit der Ausgabe von Betriebszeit, Als nächstes können wir die Nummer sehen, wenn Aufgaben laufen, schlafen usw. Beachten Sie die Anzahl der Zombie -Prozesse (fehlerhafte) Prozesse; In diesem Fall ist es 0, aber wenn es im Zombie -Staat einige Prozesse geben würde, sollten sie untersucht werden. Die nächste Zeile zeigt die Last des CPUs in Prozent und die angesammelten Prozentsätze von genau Was Die Prozessoren sind mit beschäftigt mit. Hier können wir sehen, dass die Prozessoren damit beschäftigt sind, Benutzerspace -Programme zu bedienen.
Als nächstes kommen zwei Zeilen, die aus dem vertraut sein können frei Ausgabe, Speicherverbrauch, wenn das System. Darunter finden Sie die Top -Prozesse, die nach der CPU -Verwendung sortiert werden. Jetzt können wir sehen, was unsere Prozessoren isst, es ist in unserem Fall Firefox.
Überprüfungsprozesse
Woher weiß ich das, da der Top -Konsumprozess in meinem als „Webinhalt“ angezeigt wird Spitze Ausgang? Durch die Nutzung ps Um die Prozesstabelle abzufragen, unter Verwendung der PID neben dem Top -Prozess, was in diesem Fall vorliegt 5785:
$ ps -f | Grep 5785 | grep -v "grep" sandmann 5785 2528 19 18:18 tty2 00:00:54/usr/lib/Firefox/Firefox -ContentProc -Childid 13 -Forbrowser -prefslen 9825 -prefmapsize 226230 -Parentbuildid (2020072019393547 -uIntbuildid (2020072. Firefox/Browser 2528 True Tab
Mit diesem Schritt fanden wir die Hauptursache unserer Situation. Firefox isst unsere CPU -Zeit bis zu dem Punkt, an dem unser System auf unsere Handlungen langsamer antwortet. Dies ist nicht unbedingt die Schuld des Browsers,
Da Firefox Seiten aus dem World Wide Web angezeigt hat: Um ein CPU -Problem zum Zwecke der Demonstration zu erstellen Oberflächen. Ich muss also meinen Browser nicht verantwortlich machen, sondern ich selbst, dass ich ressourcenhungrige Seiten eröffnet und sie parallel laufen lassen kann. Durch Schließen einige, meine CPU
Die Verwendung kehrt wieder normal.
Prozesse zerstören
Das Problem und die Lösung sind oben aufgedeckt, aber was ist, wenn ich nicht auf den Browser zugreifen kann, um einige Registerkarten zu schließen? Nehmen wir an, meine grafische Sitzung ist gesperrt und ich kann mich nicht wieder anmelden oder ein General
Prozess, dass Gone Wild nicht einmal eine Schnittstelle hat, an der wir das Verhalten ändern können? In diesem Fall können wir die Abschaltung des Prozesses durch das Betriebssystem ausstellen. Wir kennen bereits die PID der
Schurkenprozess, mit dem wir uns bekamen ps, Und wir können das verwenden töten Befehl, es zu schließen:
$ Kill 5785
Wohlbefindensprozesse beenden, einige können möglicherweise nicht. Wenn ja, das Hinzufügen der -9 Die Flagge erzwingt die Prozessabschluss:
$ Kill -9 5785
Beachten Sie jedoch, dass dies einen Datenverlust verursachen kann, da der Prozess keine Zeit hat, geöffnete Dateien zu schließen oder seine Ergebnisse zu verenden. Bei einer wiederholbaren Aufgabe kann die Systemstabilität jedoch Vorrang haben, einige unserer Ergebnisse zu verlieren.
Verwandte Informationen finden
Die Interaktion mit Prozessen mit einer Art von Schnittstelle ist nicht immer der Fall, und viele Anwendungen haben nur grundlegende Befehle, die ihr Verhalten steuern - nämlich Starten, Stoppen, Nachladen und dergleichen, da ihre internen Arbeiten durch ihre Konfiguration bereitgestellt werden. Das obige Beispiel war eher ein Desktop. Sehen wir uns ein serverseitiges Beispiel an, bei dem wir ein Problem mit einem Webserver haben.
Angenommen, wir haben einen Webserver, der einige Inhalte für die Welt dient. Es ist beliebt, also sind es keine gute Nachrichten, wenn wir einen Anruf erhalten, dass unser Service nicht verfügbar ist. Wir können die Webseite in einem Browser nur überprüfen, um eine Fehlermeldung zu erhalten, in der es sich um die Aufschrift „Eine Verbindung kann nicht verbinden kann“ abgerufen wird. Lassen Sie uns den Maschine sehen, der den Webserver ausführt!
Überprüfung von Protokolldateien
Unser Maschinenhosting the Webserver ist eine Fedora -Box. Dies ist wichtig, weil die Dateisystempfade, denen wir folgen müssen. Fedora und alle anderen Red Hat -Varianten speichern die Protokolldatmen des Apache -Webservers auf dem Pfad /var/log/httpd. Hier können wir das überprüfen Fehlerprotokoll Verwendung Sicht, Finden Sie jedoch keine verwandten Informationen darüber, was das Problem sein könnte. Die Überprüfung der Zugriffsprotokolle zeigt auch auf den ersten Blick keine Probleme, aber das zweimalige Denken gibt uns einen Hinweis: Auf einem Webserver mit gut genug Verkehr sollten die letzten Einträge des Zugriffsprotokolls sehr neu sein, aber der letzte Eintrag ist bereits eine Stunde alt. Wir wissen durch Erfahrung, dass die Website Besucher jede Minute bekommt.
Systemd
Unsere Fedora -Installation verwendet systemd als Init -System. Fragen wir nach Informationen zum Webserver:
# Systemctl Status httpd ● httpd.Service - Der Apache HTTP -Server geladen: geladen (/usr/lib/systemd/system/httpd.Service; Behinderte; Anbieter Voreinstellung: Deaktiviert) Drop-In:/usr/lib/systemd/system/httpd.Service.d └─php-fpm.Conf Active: Fehlgeschlagen (Ergebnis: Signal) seit der Sonne 2020-08-02 19:03:21 CEST; 3 Minuten vor 5s Docs: Mann: Httpd.Service (8) Prozess: 29457 execstart =/usr/sbin/httpd $ option -Dortround (Code = getötet, Signal = Kill) HauptpID: 29457 (Code = getötet, Signal = Kill) Status: "Gesamtanforderungen: 0; /Beschäftigte Arbeiter 100/0; Anfragen/Sekunden: 0; Bytes Serviert/Sek.: 0 B/Sek. "CPU: 74ms Aug 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29665 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29666 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29667 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29668 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29669 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29670 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29671 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29672 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Tötungsprozess 29673 (N/A) mit Signal Sigkill. August 02 19:03:21 MyWebserver1.foobar systemd [1]: httpd.Service: Mit Ergebnis 'Signal' fehlgeschlagen.Das obige Beispiel ist wieder einfach, das, das httpd Hauptprozess nach unten, weil es ein Kill -Signal erhielt. Möglicherweise gibt es ein weiteres Sysadminal
Angemeldet (oder war zum Zeitpunkt der kraftvollen Schließung des Webservers) und sie/ihn nach dem Problem fragen (ein hoch entwickelter Service -Stopp wäre weniger brutal gewesen, daher muss es einen Grund dafür geben
Fall). Wenn wir die einzigen Administratoren auf dem Server sind, können wir überprüfen. In beiden Fällen können wir die verwenden
Die Protokolldateien des Servers, weil ssh Anmeldungen werden an den Sicherheitsprotokollen protokolliert (/var/log/sicher in Fedoras Fall), und es gibt auch Prüfungseinträge im Hauptprotokoll (das ist/var/log/messages in diesem Fall). Es gibt einen Eintrag, der uns sagt, was im letzteren passiert ist:
2. August 19:03:21 MyWebserver1.Foobar Audit [1]: service_stop pid = 1 uid = 0 AUID = 4294967295 SES = 4294967295 msg = "Einheit = httpd comm =" systemd "exe ="/usr/lib/systemd/systemd "Hostname =" Hostname = "? addr =? terminal =? res = fehlgeschlagen "
Abschluss
Zu Demonstrationszwecken habe ich in diesem Beispiel meinen eigenen Labor -Webserver -Hauptprozess getötet. In einem serverbezogenen Problem können wir die beste Hilfe schnell erreichen, indem wir die Protokolldateien überprüfen und das System zum Ausführen von Prozessen (oder deren Abwesenheit) und der Überprüfung ihres gemeldeten Zustands abfragen, um näher an das Problem zu kommen. Um dies effektiv zu tun, müssen wir die Dienste wissen, die wir ausführen: Wo schreiben sie ihre Protokolldateien, wie
Wir können Informationen über ihren Zustand erhalten und zu wissen, was zu normalen Betriebszeiten angemeldet ist.
Es gibt viele Tools, die uns helfen, die meisten dieser Dinge wie ein Überwachungssubsystem zu automatisieren und Aggregationslösungen zu protokollieren, aber alle beginnen mit uns, die Admins, die wissen, wie die Dienste wir ausführen
Arbeit, wo und was zu überprüfen, um zu wissen, ob sie gesund sind. Die obigen nachgewiesenen einfachen Tools sind in jeder Verteilung zugänglich, und mit ihrer Hilfe können wir helfen, Probleme mit Systemen zu lösen, die wir nicht sind
sogar vertraut mit. Das ist ein fortgeschrittenes Maß an Fehlerbehebung, aber die hier gezeigten Werkzeuge und deren Verwendung sind einige der Steine.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- Linux -Download
- Dinge zu tun nach der Installation Ubuntu 22.04 Jammy Quallen…
- Liste der besten Kali -Linux -Tools für Penetrationstests und…
- Installieren Sie Arch Linux in VMware Workstation
- Beste Linux -Distribution für Entwickler
- Linux -Konfigurationsdateien: Top 30 am wichtigsten
- Linux -Befehle: Top 20 wichtigste Befehle, die Sie benötigen, um…
- « Grundlegende Ubuntu 20.04 OpenVPN -Client/Server -Verbindungsanschluss -Setup
- Sugarcrm CE -Installation auf Debian 7 Wheezy Linux »