

Hadoop - Ausführen eines WordCount MapReduce -Beispiels
- 1263
- 341
- Marleen Weight
Dieses Tutorial hilft Ihnen dabei, ein WordCount MapReduce -Beispiel in Hadoop mit der Befehlszeile auszuführen. Dies kann auch ein erster Test für Ihren Hadoop -Setup -Test sein.
1. Voraussetzungen
Sie müssen auf Ihrem System ausgeführtes Hadoop -Setup haben. Wenn Sie nicht Hadoop installiert haben, besuchen Sie die Hadoop -Installation im Linux -Tutorial.
2. Kopieren Sie Dateien in das Dateisystem von namenode
Nach erfolgreichem Formatieren von Namenode müssen Sie alle Hadoop -Dienste ordnungsgemäß gestartet haben. Erstellen Sie nun ein Verzeichnis im Hadoop -Dateisystem.
$ HDFS DFS -MKDIR -P/Benutzer/Hadoop/Eingabe
Kopieren Sie eine Textdatei in das Hadoop -Dateisystem im Eingabeverzeichnis. Hier kopiere ich Lizenz.txt dazu. Sie können mehr als eine Datei kopieren.
$ HDFS DFS -PUT -Lizenz.txt/user/hadoop/input/
3. WordCount -Befehl ausführen
Führen Sie nun das Beispiel für WordCount MapReduce mit dem folgenden Befehl aus. Unter dem folgenden Befehl werden alle Dateien aus dem Eingaberordner gelesen und mit MapReduce JAR -Datei verarbeitet. Nach dem erfolgreichen Abschluss der Aufgabenergebnisse werden im Ausgabeverzeichnis platziert.
US.6.0.Jar WordCount -Eingabeausgabe
4. Zeige Ergebnisse
Überprüfen Sie zunächst die Namen der Ergebnisdatei, die unter [E -Mail geschützt]/Benutzer/Hadoop/Ausgabedateisystem erstellt wurden, mithilfe der folgenden Befehl.
$ HDFS DFS -LS/Benutzer/Hadoop/Ausgabe
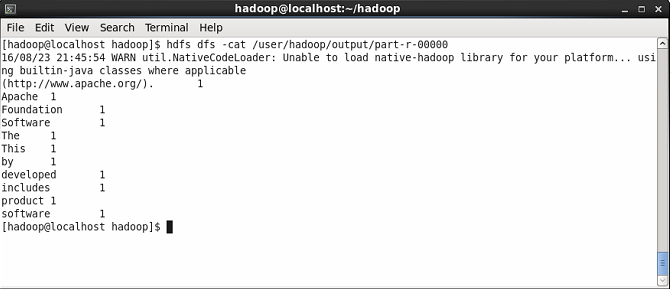
Zeigen Sie nun den Inhalt der Ergebnisdatei an, in dem Sie das Ergebnis von WordCount sehen werden. Sie werden die Anzahl jedes Wortes sehen.
$ HDFS DFS -CAT/Benutzer/Hadoop/Output/Part-R-00000
- « So installieren Sie Go 1.19 auf Fedora 36/35 & Centos/Rhel 8/7
- So installieren Sie Apache Maven auf CentOS/Rhel 8/7 »