

So konfigurieren und pflegen Sie hohe Verfügbarkeit/Clustering unter Linux
- 4470
- 1121
- Madleen Vater
Hohe Verfügbarkeit (HA) bezieht sich einfach auf eine Qualität eines Systems, das über einen längeren Zeitraum kontinuierlich ohne Fehler arbeitet. HA -Lösungen können mit Hardware und/oder Software implementiert werden, und eine der gängigen Lösungen für die Implementierung von HA ist das Clustering.
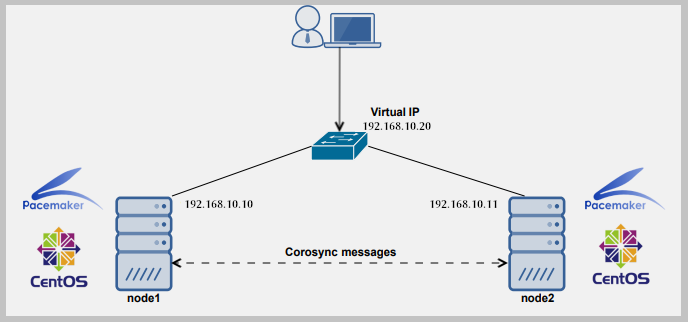
Beim Computer besteht ein Cluster aus zwei oder mehr Computern (allgemein bekannt als Knoten oder Mitglieder) Das arbeitet zusammen, um eine Aufgabe auszuführen. In einem solchen Setup bietet nur ein Knoten den Dienst mit den sekundären Knoten (n), wenn er fehlschlägt.
Cluster fallen in vier Haupttypen:
- Lagerung: Geben Sie ein konsistentes Dateisystembild über die Server in einem Cluster hin.
- Hohe Verfügbarkeit: Beseitigen Sie einzelne Ausfallpunkte und durch Ausfall der Dienste von einem Clusterknoten zum anderen, falls ein Knoten inoperativ wird.
- Lastverteilung: Versand -Netzwerkdienstanforderungen an mehrere Clusterknoten, um die Anforderungslast zwischen den Clusterknoten auszugleichen.
- Hochleistung: Führen Sie eine parallele oder gleichzeitige Verarbeitung durch, wodurch die Leistung von Anwendungen verbessert wird.
Eine weitere weit verbreitete Lösung für die Bereitstellung HA ist Replikation (speziell Datenreplikationen). Die Replikation ist der Prozess, mit dem eine oder mehrere (sekundäre) Datenbanken mit einer einzelnen primären (oder Master-) Datenbank synchronisiert werden können.
Um einen Cluster einzurichten, brauchen wir mindestens zwei Server. Für diesen Leitfaden verwenden wir zwei Linux -Server:
- Node1: 192.168.10.10
- Node2: 192.168.10.11
In diesem Artikel werden wir die Grundlagen des Bereitstellens, Konfigurierens und Aufrechterhaltens von hoher Verfügbarkeit/Clusterbildung in Ubuntu 16 demonstrieren.04/18.04 und Centos 7. Wir werden demonstrieren.
Konfigurieren lokaler DNS -Einstellungen auf jedem Server
Damit die beiden Server miteinander kommunizieren können, müssen wir die entsprechenden lokalen DNS -Einstellungen in der Konfiguration konfigurieren /etc/hosts Datei auf beiden Servern.
Öffnen und bearbeiten Sie die Datei mit Ihrem bevorzugten Befehlszeileneditor.
$ sudo vim /etc /hosts
Fügen Sie die folgenden Einträge mit den tatsächlichen IP -Adressen Ihrer Server hinzu.
192.168.10.10 Node1.Beispiel.com 192.168.10.11 Node2.Beispiel.com
Speichern Sie die Änderungen und schließen Sie die Datei.
Installieren von NGINX -Webserver
Installieren Sie nun den NGINX -Webserver mit den folgenden Befehlen.
$ sudo apt install nginx [auf ubuntu] $ sudo yum install epel-release && sudo yum install nginx [auf CentOS 7]
Starten Sie nach Abschluss der Installation den Nginx-Dienst vorerst und aktivieren Sie ihn zum Auto-Start zum Startzeit und prüfen.
Auf Ubuntu sollte der Dienst automatisch nach Abschluss der Paketvorkonfiguration automatisch gestartet werden. Sie können ihn einfach aktivieren.
$ sudo systemctl aktivieren
Nach dem Start des NGINX -Dienstes müssen wir benutzerdefinierte Webseiten erstellen, um Vorgänge auf beiden Servern zu identifizieren und zu testen. Wir werden den Inhalt der Standard -Nginx -Indexseite wie gezeigt ändern.
$ echo "Dies ist die Standardseite für Node1.Beispiel.com "| sudo tee/usr/share/nginx/html/index.HTML #vps1 $ echo "Dies ist die Standardseite für Node2.Beispiel.com "| sudo tee/usr/share/nginx/html/index.HTML #vps2
Installieren und Konfigurieren von Corosync und Herzschrittmacher
Als nächstes müssen wir installieren Schrittmacher, Corosync, Und Stck auf jedem Knoten wie folgt.
$ sudo apt installieren corosync pacemaker pcs #ubuntu $ sudo yum installieren corosync pacemaker pcs #centos
Sobald die Installation abgeschlossen ist, stellen Sie sicher, dass dies sichergestellt ist Stck Daemon läuft auf beiden Servern.
$ sudo systemCTL aktivieren PCSD $ sudo systemctl starten pcsd $ sudo systemctl Status PCSD
Erstellen des Clusters
Während der Installation rief ein Systembenutzer an "Hacluster" geschaffen. Wir müssen also die Authentifizierung einrichten, die benötigt wird Stck. Beginnen wir zunächst ein neues Passwort für die "Hacluster" Benutzer müssen das gleiche Passwort auf allen Servern verwenden:
$ sudo passwd hacluster
 Cluster -Benutzerkennwort erstellen
Cluster -Benutzerkennwort erstellen Führen Sie als nächstes auf einem der Server (NODE1) den folgenden Befehl aus, um die für benötigte Authentifizierung einzurichten Stck.
$ sudo pcs cluster auth node1.Beispiel.com node2.Beispiel.com -u hacluster -p password_here -Force
 Setup -Authentifizierung für PCs einrichten
Setup -Authentifizierung für PCs einrichten Erstellen Sie nun einen Cluster und bevölkern Sie ihn mit einigen Knoten (der Clustername darf 15 Zeichen nicht überschreiten. In diesem Beispiel haben wir verwendet BeispielPleCluster) auf dem NODE1 -Server.
$ sudo pcs cluster setup -name examplecluster node1.Beispiel.com node2.Beispiel.com
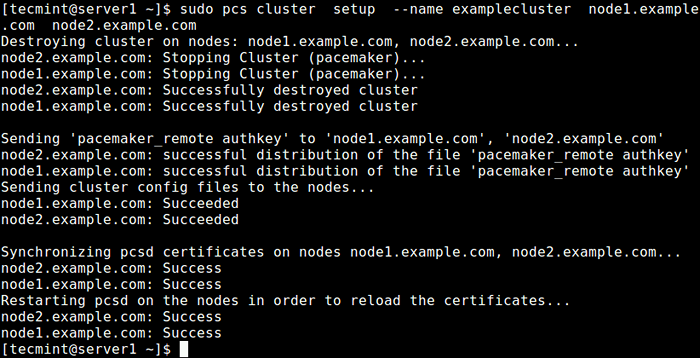 Erstellen Sie Cluster auf Node1
Erstellen Sie Cluster auf Node1 Aktivieren Sie nun den Cluster im Boot und starten Sie den Dienst.
$ sudo pcs cluster aktivieren -alle $ sudo pcs cluster starten -alle
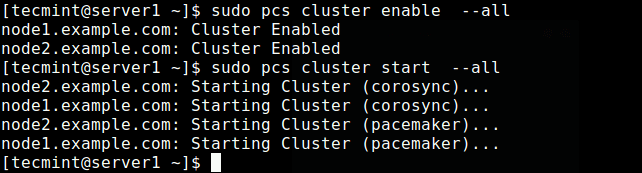 Aktivieren und starten Sie den Cluster
Aktivieren und starten Sie den Cluster Überprüfen Sie nun, ob der Cluster -Dienst mit dem folgenden Befehl ausgeführt wird.
$ sudo pcs Status oder $ sudo crm_mon -1
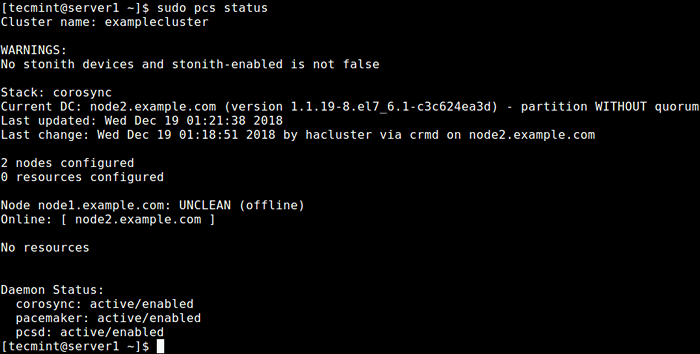 Überprüfen Sie den Clusterstatus
Überprüfen Sie den Clusterstatus Aus der Ausgabe des obigen Befehls können Sie erkennen, dass es eine Warnung vor nein gibt Stonith Geräte noch die Stonith ist im Cluster noch aktiviert. Darüber hinaus wurden keine Cluster -Ressourcen/-dienste konfiguriert.
Konfigurieren von Clusteroptionen
Die erste Möglichkeit besteht darin, zu deaktivieren Stonith (oder Schießen Sie den anderen Knoten in den Kopf) die Umsetzung der Zäune auf Schrittmacher.
Diese Komponente hilft, Ihre Daten vor dem gleichzeitigen Zugriff vor dem gleichzeitigen Zugriff zu schützen. Für diesen Leitfaden werden wir es deaktivieren, da wir keine Geräte konfiguriert haben.
Ausschalten Stonith, Führen Sie den folgenden Befehl aus:
$ sudo pcs Eigenschaft Set stonith-fähig = false
Als nächstes ignorieren Sie auch die Quorum Richtlinien durch Ausführen des folgenden Befehls:
$ sudo pcs Eigenschaft Set no-quorum-policy = ignorieren
Führen Sie nach der Einstellung der oben genannten Optionen den folgenden Befehl aus, um die Eigenschaftsliste anzuzeigen und sicherzustellen, dass die oben genannten Optionen, Stonith und das Quorum -Richtlinie Sind deaktiviert.
$ sudo pcs Eigenschaftsliste
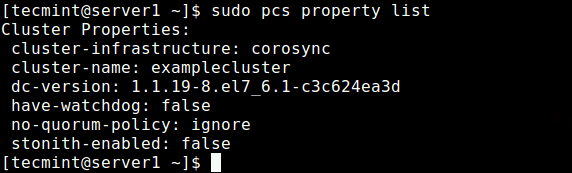 Clustereigenschaften anzeigen
Clustereigenschaften anzeigen Hinzufügen eines Ressourcen-/Cluster -Dienstes
In diesem Abschnitt werden wir uns ansehen, wie Sie eine Cluster -Ressource hinzufügen können. Wir konfigurieren eine schwebende IP, die die IP. Kurz gesagt, eine schwebende IP ist ein technischer gemeinsamer Begriff, der für IPs verwendet wird, die nicht ausschließlich an eine einzige Schnittstelle gebunden sind.
In diesem Fall wird es verwendet, um Failover in einem Cluster mit hoher Verfügbarkeit zu unterstützen. Denken Sie daran, dass schwimmende IPs nicht nur für Failover -Situationen nicht nur ein paar andere Anwendungsfälle haben. Wir müssen den Cluster so konfigurieren, dass nur das aktive Mitglied des Clusters zu einem bestimmten Zeitpunkt „besitzt“ oder auf die schwebende IP reagiert.
Wir werden zwei Cluster -Ressourcen hinzufügen: die schwimmende IP -Adressressource namens “Floating_ip"Und eine Ressource für den Nginx -Webserver mit dem Namen"http_server”.
Beginnen Sie zunächst mit dem Floating_ip wie folgt hinzu. In diesem Beispiel lautet unsere schwimmende IP -Adresse 192.168.10.20.
$ sudo pcs ressource erstellen floating_ip OCF: Herzschlag: iPadDR2 IP = 192.168.10.20 cidr_netmask = 24 op monitor intervall = 60s
Wo:
- Floating_ip: Ist der Name des Dienstes.
- "OCF: Herzschlag: iPaddr2": teilt Pacemaker an, in welchem Skript iPadDR2 in diesem Fall verwendet werden soll, in welchem Namespace es sich befindet (Schrittmacher) und in welchem Standard es sich an die OCF entspricht.
- “OP -Monitor -Intervall = 60s”: Weisen Sie den Schrittmacher an, die Gesundheit dieses Service alle Minuten zu überprüfen, indem Sie die Überwachungsaktion des Agenten anrufen.
Fügen Sie dann die zweite Ressource hinzu, benannt http_server. Hier ist der Ressourcenagent des Dienstes OCF: Herzschlag: nginx.
$ sudo pcs ressource erstellen http_server ocf: Heartbeat: nginx configfile = "/etc/nginx/nginx.conf "op monitor timeout =" 20s "Interval =" 60s "
Wenn Sie die Clusterdienste hinzugefügt haben, geben Sie den folgenden Befehl aus, um den Status der Ressourcen zu überprüfen.
$ sudo PCS Statusressourcen
 Überprüfen Sie die Clusterressourcen
Überprüfen Sie die Clusterressourcen Wenn man sich die Ausgabe des Befehls ansieht, wurden die beiden hinzugefügten Ressourcen hinzugefügt: "Floating_ip" Und "Http_server" wurden aufgeführt. Der Floating_IP -Dienst ist ausgeschaltet, da der primäre Knoten in Betrieb ist.
Wenn Sie Firewall in Ihrem System aktiviert haben, müssen Sie den gesamten Datenverkehr zulassen Nginx und alle hohen Verfügbarkeitsdienste über die Firewall, um eine ordnungsgemäße Kommunikation zwischen Knoten zu erhalten:
-------------- CentOS 7 -------------- $ sudo firewall-cmd --permanent --add-service = http $ sudo Firewall-cmd --permanent --add-service = hohe verfügbare $ sudo Firewall-CMD-Reload -------------- Ubuntu -------------- $ sudo ufw erlauben http $ sudo ufw Erlauben Sie Hochverfügbarkeit $ sudo ufw neu laden
Testen hoher Verfügbarkeit/Clusterbildung
Der letzte und wichtige Schritt besteht darin, zu testen, ob unsere Hochverfügbarkeits -Setup funktioniert. Öffnen Sie einen Webbrowser und navigieren Sie zur Adresse 192.168.10.20 Sie sollten die Standard -Nginx -Seite von der sehen Node2.Beispiel.com Wie im Screenshot gezeigt.
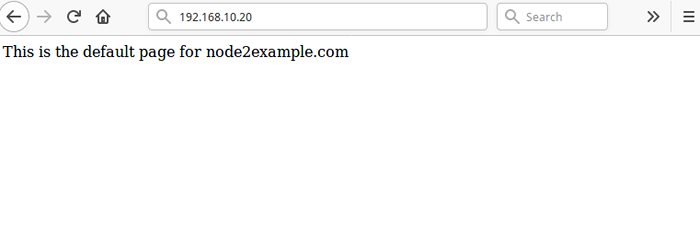 Testen Sie Cluster vor dem Ausfall
Testen Sie Cluster vor dem Ausfall Führen Sie den folgenden Befehl aus, um den Cluster auf dem zu stoppen, um einen Fehler zu simulieren Node2.Beispiel.com.
$ sudo pcs cluster stoppen http_server
Laden Sie dann die Seite um 192.168.10.20, Sie sollten nun auf die Standard -Nginx -Webseite aus der Seite zugreifen Node1.Beispiel.com.
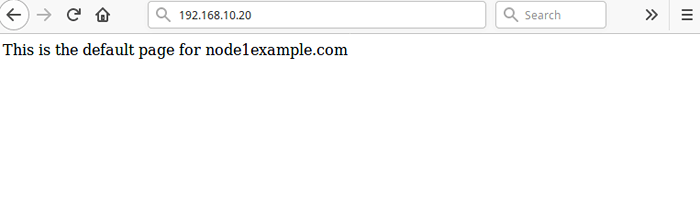 Testcluster nach dem Fehler
Testcluster nach dem Fehler Alternativ können Sie einen Fehler simulieren, indem Sie den Dienst anweisen, direkt anzuhalten, ohne den Cluster auf einem beliebigen Knoten zu stoppen, wobei der folgende Befehl auf einem der Knoten verwendet wird:
$ sudo crm_resource-resource http_server-Force-Stop
Dann musst du rennen crm_mon Im interaktiven Modus (standardmäßig) sollten Sie innerhalb des Monitorintervalls von 2 Minuten in der Lage sein, den Cluster -Hinweis zu sehen, dass http_server fehlgeschlagen und bewegen Sie es auf einen anderen Knoten.
Damit Ihre Cluster -Dienste effizient ausgeführt werden können, müssen Sie möglicherweise einige Einschränkungen festlegen. Du kannst das ... sehen Stck Mann Seite (Man PCs) für eine Liste aller Verwendungsbefehle.
Weitere Informationen zu Corosync und Herzschrittmacher finden Sie unter: https: // clusterlabs.org/
Zusammenfassung
In diesem Handbuch haben wir die Grundlagen zum Bereitstellen, Konfigurieren und Verwalten von hoher Verfügbarkeit/Clusterbildung/Replikation in Ubuntu 16 gezeigt,.04/18.04 und Centos 7. Wir haben gezeigt, wie man einem Cluster den Nginx -HTTP -Dienst hinzufügt. Wenn Sie Gedanken zum Teilen oder Fragen haben, verwenden Sie das Feedback -Formular unten.
- « Wie man eine Partition oder Festplatte unter Linux klont
- So konfigurieren Sie den LDAP -Client zur Verbindung der externen Authentifizierung »