

So erstellen Sie einen heißen Standby mit Postgresql
- 2766
- 735
- Janin Pletsch
Zielsetzung
Unser Ziel ist es, eine Kopie einer PostgreSQL-Datenbank zu erstellen, die ständig mit dem Original synchronisiert wird und schreibgeschützte Abfragen akzeptiert.
Betriebssystem- und Softwareversionen
- Betriebssystem: Red Hat Enterprise Linux 7.5
- Software: PostgreSQL Server 9.2
Anforderungen
Privilegierter Zugriff auf Master- und Sklavensysteme
Konventionen
- # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können
sudoBefehl - $ - Angegebene Linux-Befehle, die als regelmäßiger nicht privilegierter Benutzer ausgeführt werden sollen
Einführung
PostgreSQL ist ein Open -Source -RDBMS (relationales Datenbankverwaltungssystem), und mit allen Datenbanken kann die Notwendigkeit entstehen, HA zu skalieren und bereitzustellen (hohe Verfügbarkeit). Ein einzelnes System, das einen Dienst anbietet, ist immer ein möglicher einziger Fehlerpunkt - und selbst bei virtuellen Systemen kann es eine Zeit geben, in der Sie einer einzelnen Maschine nicht mehr Ressourcen hinzufügen können, um mit der immer größeren Last fertig zu werden. Möglicherweise muss auch eine andere Kopie des Datenbankinhalts, die für langjährige Analysen abgefragt werden können. Diese Kopie könnte eine einfache Wiederherstellung von der neuesten Sicherung auf einer anderen Maschine sein, aber die Daten wären veraltet, sobald sie wiederhergestellt wird.
Durch das Erstellen einer Kopie der Datenbank, die ständig ihren Inhalt mit dem ursprünglichen (als Master oder Primary bezeichnet) repliziert, akzeptieren und geben Sie dabei jedoch die Ergebnisse an nur schreibgeschützte Abfragen an und können Sie eine erstellen, um eine zu erstellen, Hot-Standby die eng den gleichen Inhalt haben.
Im Falle eines Master -Fehlers kann die Standby -Datenbank (oder Slave) die Rolle der Primärübernahme übernehmen, die Synchronisation stoppen und Lese- und Schreibanforderungen akzeptieren, damit die Operationen fortgesetzt werden können, und der fehlgeschlagene Meister kann wieder zum Leben erwidert werden (möglicherweise als Standby, indem der Weg der Synchronisation gewechselt wird). Wenn sowohl Primär- als auch Standby ausgeführt werden, können Abfragen, die nicht versuchen, den Datenbankinhalt zu ändern. Beachten Sie jedoch, dass es eine Verzögerung geben wird - der Standby wird hinter dem Meister und bis zu der Zeit der Zeit stehen, um Änderungen zu synchronisieren. Diese Verzögerung kann je nach Setup vorsichtig sein.
Es gibt viele Möglichkeiten, eine Master-Sklaven-Synchronisation (oder sogar eine Master-Master) mit PostgreSQL zu erstellen. In diesem Tutorial werden wir jedoch die Replikation der Streaming mit dem neuesten PostgreSQL-Server einrichten, der in Red Hat Repositories verfügbar ist. Der gleiche Prozess gilt im Allgemeinen für andere Verteilungen und RDMBS.
Installation der erforderlichen Software
Lassen Sie uns PostgreSQL mit installieren Yum zu beiden Systemen:
yum install postgresql-server
Nach erfolgreicher Installation müssen wir beide Datenbankcluster initialisieren:
# postgresql-setup initdb initialisierungsdatenbank… . OK Um ein automatisches Start für die Datenbanken auf dem BOOT bereitzustellen, können wir den Service in aktivieren systemd:
SystemCTL aktivieren postgresql
Wir werden verwenden 10.10.10.100 als primär und 10.10.10.101 Als IP -Adresse des Standby -Geräts.
Richten Sie den Master ein
Es ist im Allgemeinen eine gute Idee, Konfigurationsdateien zu sichern, bevor wir Änderungen vornehmen. Sie nehmen nicht erwähnenswert und wenn etwas schief geht, kann die Sicherung einer Arbeitskonfigurationsdatei ein Lebensretter sein.
Wir müssen die bearbeiten PG_HBA.Conf mit einem Textdatei -Editor wie vi oder Nano. Wir müssen eine Regel hinzufügen, die es dem Datenbankbenutzer aus dem Standby ermöglicht, auf die Primärin zuzugreifen. Dies ist die serverseitige Einstellung. Der Benutzer existiert noch nicht in der Datenbank. Sie können Beispiele am Ende der kommentierten Datei finden, die sich mit dem beziehen Reproduzieren Datenbank:
# Replikationsverbindungen von Localhost zulassen, von einem Benutzer mit der # Replication -Berechtigung. #Lokale Replikation Postgres Peer #Host Replication Postgres 127.0.0.1/32 Identifizierung #Host Replication Postgres :: 1/128 Ident
Fügen wir zum Ende der Datei eine weitere Zeile hinzu und markieren Sie sie mit einem Kommentar, damit leicht zu sehen ist, was sich aus den Standardeinstellungen geändert hat:
## MyConf: Replikation Host Replikation Repusser 10.10.10.101/32 MD5
Bei Red Hat -Aromen befindet sich die Datei standardmäßig unter dem /var/lib/pgsql/data/ Verzeichnis.
Wir müssen auch Änderungen an der Hauptkonfigurationsdatei des Datenbankservers vornehmen, PostgreSQL.Conf, Das befindet sich im selben Verzeichnis, das wir gefunden haben PG_HBA.Conf.
Suchen Sie die Einstellungen in der folgenden Tabelle und ändern Sie sie wie folgt:
| Abschnitt | Standardeinstellung | Modifizierte Einstellung |
|---|---|---|
| Verbindungen und Authentifizierung | #Listen_addresses = 'localhost' | listen_addresses = '*' |
| Schreiben Sie im Voraus Protokoll | #wal_level = minimal | wal_level = 'hot_standby' ' |
| Schreiben Sie im Voraus Protokoll | #Archive_mode = off | archive_mode = on |
| Schreiben Sie im Voraus Protokoll | #Archive_command = ” | archive_command = 'true' ' |
| REPRODUZIEREN | #max_wal_senders = 0 | max_wal_senders = 3 |
| REPRODUZIEREN | #hot_standby = off | HOT_STANDBY = ON |
Beachten Sie, dass die obigen Einstellungen standardmäßig ausgezeichnet werden. Sie müssen sich anwenden Und ihre Werte ändern.
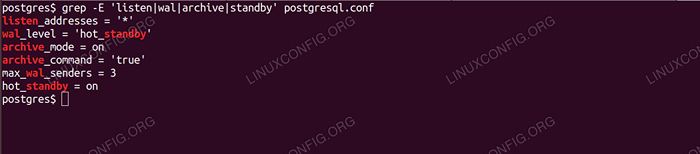
Du kannst Grep die geänderten Werte zur Überprüfung. Sie sollten so etwas wie Folgendes bekommen:
Änderungen mit Grep überprüfen Nachdem die Einstellungen in Ordnung sind, starten wir den primären Server:
# SystemCTL Start PostgreSQL
Und benutzen PSQL So erstellen Sie den Datenbankbenutzer, der die Replikation behandelt:
# Su -Postgres -bash -4.2 $ PSQL PSQL (9.2.23) Geben Sie "Hilfe" für Hilfe ein. postgres =# Benutzer Repusser Replikation Anmeldung verschlüsseltes Passwort 'SecretPassword' Verbindungslimit -1; Rolle erstellen
Beachten Sie das Passwort, das Sie dem geben Repussierer, Wir brauchen es auf der Standby -Seite.
Den Sklaven einrichten
Wir haben den Standby mit dem verlassen initdb Schritt. Wir werden als die arbeiten Postgres Benutzer, der im Kontext der Datenbank Superuser ist. Wir benötigen eine erste Kopie der primären Datenbank, und das bekommen wir mit pg_baseBackup Befehl. Zuerst löschen wir das Datenverzeichnis in Standby (erstellen Sie vorher eine Kopie, wenn Sie möchten, aber es handelt sich nur um eine leere Datenbank):
$ rm -rf/var/lib/pgsql/data/*
Jetzt sind wir bereit, eine konsistente Kopie des primären Standby -Zeits zu erstellen:
$ pg_baseBackup -h 10.10.10.100 -U Repuser -d/var/lib/pgsql/data/password: Hinweis: pg_stop_backup vollständig, alle erforderlichen Wal -Segmente wurden archiviert Wir müssen die IP -Adresse des Masters nach -H und den Benutzer angeben, den wir zur Replikation erstellt haben, in diesem Fall Repussierer. Da die primäre leer neben diesem Benutzer ist, den wir erstellt haben, die pg_baseBackup sollte in Sekunden abgeschlossen werden (abhängig von der Netzwerkbandbreite). Wenn etwas schief geht, überprüfen Sie die HBA -Regel in der Primäranlage, die Richtigkeit der IP -Adresse, die dem gegeben wurde pg_baseBackup Befehl und dieser Port 5432 für die Primäranlage ist von Standby aus erreichbar (zum Beispiel mit Telnet).
Wenn das Backup beendet ist, werden Sie feststellen, dass das Datenverzeichnis auf dem Slave gefüllt ist, einschließlich Konfigurationsdateien (denken Sie daran, wir haben alles aus diesem Verzeichnis gelöscht):
# ls/var/lib/pgsql/data/backup_label.Old PG_CLOG PG_LOG PG_SERIAL PG_SUBTRANS PG_VERSION POSTMASTER.OPTS BASE PG_HBA.conf pg_multixact pg_snapshots pg_tblspc pg_xlog postmaster.PID Global pg_ident.conf pg_notify pg_stat_tmp pg_twophase postgresql.Conf Genesung.Conf Jetzt müssen wir einige Anpassungen an der Konfiguration des Standby vornehmen. Die IP PG_HBA.Conf:
# Tail -n2/var/lib/pgsql/data/pg_hba.conf ## MyConf: Replikation Host Replikation Repusser 10.10.10.100/32 MD5 Die Änderungen in der PostgreSQL.Conf sind die gleichen wie beim Master, da wir diese Datei auch mit der Sicherung kopiert haben. Auf diese Weise können beide Systeme die Rolle von Master oder Standby in Bezug auf diese Konfigurationsdateien übernehmen.
Im selben Verzeichnis müssen wir eine Textdatei erstellen Erholung.Conf, und fügen Sie die folgenden Einstellungen hinzu:
# Cat/var/lib/PGSQL/Daten/Wiederherstellung.Conf Standby_Mode = 'auf' primär_conninfo = 'Host = 10.10.10.100 port = 5432 user = repuser password = secryPassword 'trigger_file ='/var/lib/pgsql/Trigger_file '' Beachten Sie das für die primär_conninfo Einstellung Wir haben die IP -Adresse des primär und das Passwort, das wir gegeben haben Repussierer in der Master -Datenbank. Die Triggerdatei könnte praktisch überall von der gelesen werden Postgres Benutzer des Betriebssystems mit einem gültigen Dateinamen - nach dem Ereignis eines primären Absturzes kann die Datei erstellt werden (mit berühren zum Beispiel), der ein Failover im Standby auslöst, was bedeutet, dass die Datenbank auch Schreibvorgänge akzeptiert.
Wenn diese Datei Erholung.Conf ist vorhanden, der Server wird beim Start des Wiederherstellungsmodus eingetragen. Wir haben alles an Ort und Stelle, damit wir den Standby -Unternehmen starten und sehen können, ob alle so gut wie es sein sollten:
# SystemCTL Start PostgreSQL
Es sollte etwas mehr Zeit als sonst dauern, um die Eingabeaufforderung zurückzubekommen. Der Grund dafür ist, dass die Datenbank die Wiederherstellung zu einem konsistenten Zustand im Hintergrund ausführt. Sie können den Fortschritt in der Hauptprotokolldatei der Datenbank sehen (Ihr Dateiname unterscheidet sich je nach Wochentag):
$ tailf/var/lib/pgsql/data/pg_log/postgresql-thu.Protokollprotokoll: Standby -Modus -Protokoll eingeben: Streaming -Replikation erfolgreich mit primärem Protokoll verbunden Überprüfen des Setups
Testen wir das Setup nun, da beide Datenbanken in Betrieb sind, indem wir einige Objekte für die Grundschule erstellen. Wenn alles gut geht, sollten diese Objekte irgendwann im Standby -Unternehmen erscheinen.
Wir können einige einfache Objekte für Primary erstellen (mit denen ich vertraut aussieht) mit PSQL. Wir können das folgende einfache SQL -Skript namens erstellen Probe.sql:
-- Erstellen Sie eine Sequenz, die als PK der Tabelle der Mitarbeiter dient. Erstellen Sie Sequence -Mitarbeiter. - Erstellen Sie die Tabelle der Mitarbeiter erstellen Tabellen Mitarbeiter (EMP_ID Numeric Primary Key Standard-Standard-NextVal ('powers_seq': ; - Fügen Sie einige Daten in die Tabelle ein, die in Mitarbeiter einfügen (First_Name, last_name, birth_year, birth_month, birth_dayofmonth) Werte ('Emily', 'James', 1983,03,20); Einfügen in Mitarbeiter (First_Name, last_name, birth_year, birth_month, birth_dayofmonth) Werte ('John', 'Smith', 1990,08,12); Es ist eine gute Praxis, Datenbankstrukturveränderungen in Skripten (optional in ein Codebetremsory) zu führen, um eine spätere Referenz zu erhalten. Zahlt sich aus, wenn Sie wissen müssen, was Sie geändert haben und wann. Wir können das Skript jetzt in die Datenbank laden:
$ psql < sample.sql CREATE SEQUENCE NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "employees_pkey" for table "employees" CREATE TABLE INSERT 0 1 INSERT 0 1 Und wir können die von uns erstellte Tabelle mit den beiden eingefügten Datensätzen abfragen:
postgres =# select * von Mitarbeitern; emp_id | First_Name | last_name | birth_year | BURTY_MONTH | birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 Zeilen) Lassen Sie uns den Standby nach Daten abfragen, von denen wir erwarten. Im Standby können wir die obige Abfrage ausführen:
postgres =# select * von Mitarbeitern; emp_id | First_Name | last_name | birth_year | BURTY_MONTH | birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 Zeilen) Und damit sind wir fertig, wir haben eine ausgeführte Hot-Standby.
Abschluss
Es gibt viele Möglichkeiten, Replikation mit PostgreSQL zu erstellen, und es gibt viele Tuneables in Bezug auf die Streaming -Replikation, die wir eingerichtet haben. Dieses Tutorial gilt nicht für ein Produktionssystem - es soll einige allgemeine Richtlinien darüber zeigen, was an einem solchen Setup beteiligt ist.
Denken Sie daran, dass das Werkzeug pg_baseBackup ist nur bei Postgresql Version 9 erhältlich.1+. Sie können auch in Betracht ziehen, der Konfiguration eine gültige Walarchivierung hinzuzufügen, aber wir haben dies in diesem Tutorial übersprungen, um die Dinge minimal zu machen und gleichzeitig ein funktionierendes Synchronisationspaar von Systemen zu erreichen. Und schließlich noch eine Sache zu beachten: Standby ist nicht Backup. Haben Sie jederzeit eine gültige Sicherung.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- Ubuntu 20.04 Postgresql Installation
- Ubuntu 22.04 Postgresql Installation
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Linux -Konfigurationsdateien: Top 30 am wichtigsten
- Linux -Download
- Kann Linux Viren bekommen?? Erforschung der Verwundbarkeit von Linux…
- Mint 20: Besser als Ubuntu und Microsoft Windows?
- Dinge zu installieren auf Ubuntu 22.04