

So installieren und konfigurieren Sie Apache Hadoop auf einem einzelnen Knoten in CentOS 7

- 4442
- 347
- Marleen Weight
Apache Hadoop ist ein Open -Source -Framework -Build für verteilte Big -Data -Speicher- und Verarbeitungsdaten über Computercluster hinweg. Das Projekt basiert auf den folgenden Komponenten:
- Hadoop Common - Es enthält die Java -Bibliotheken und -versorgungsunternehmen, die von anderen Hadoop -Modulen benötigt werden.
- HDFS - Hadoop Distributed Dateisystem - Ein java -basierendes skalierbares Dateisystem, das über mehrere Knoten verteilt ist.
- Karte verkleinern - Garn -Framework für die parallele Big -Data -Verarbeitung.
- Hadoop -Garn: Ein Framework für das Cluster -Ressourcenmanagement.
Installieren Sie Hadoop in CentOS 7 In diesem Artikel wird Sie darüber geleitet, wie Sie Apache Hadoop in einem einzelnen Knotencluster in installieren können Centos 7 (funktioniert auch für Rhel 7 Und Fedora 23+ Versionen). Diese Art der Konfiguration wird auch als bezeichnet als Hadoop Pseudo-verteilter Modus.
Schritt 1: Installieren Sie Java auf CentOS 7
1. Melden Sie sich zuerst mit dem Root -Benutzer oder einem Benutzer mit Root -Berechtigungen an, bevor Sie mit der Java -Installation fortfahren.
# Hostnamectl Set-Hostname Master
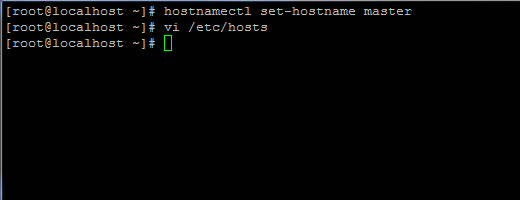 Setzen Sie Hostname in CentOS 7
Setzen Sie Hostname in CentOS 7 Fügen Sie außerdem einen neuen Datensatz in der Hosts -Datei mit Ihrem eigenen Computer FQDN hinzu, um auf Ihre System -IP -Adresse zu verweisen.
# vi /etc /hosts
Fügen Sie die folgende Zeile hinzu:
192.168.1.41 Meister.Hadoop.Lan
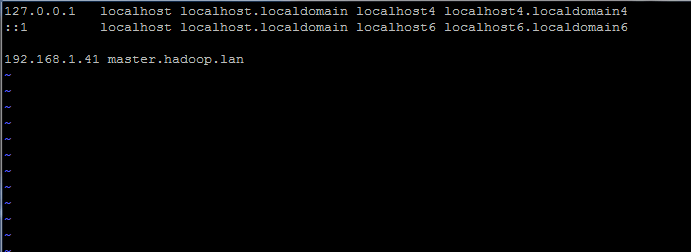 Stellen Sie die Hostname in /etc /hosts Datei fest
Stellen Sie die Hostname in /etc /hosts Datei fest Ersetzen Sie die oben genannten Hostnamen- und FQDN -Datensätze durch Ihre eigenen Einstellungen.
2. Gehen Sie als Nächst Java SE Development Kit 8 auf Ihrem System mit Hilfe von Locken Befehl:
# curl -lo -h "Cookie: Oraclelicense = Accept -SecureBackup -Cookie" "http: // download.Orakel.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.Drehzahl ”
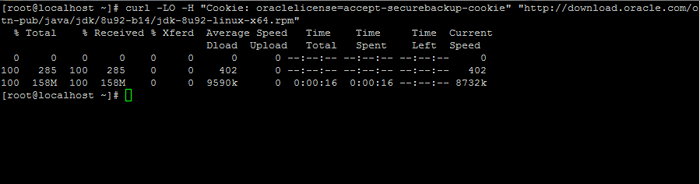 Download Java SE Development Kit 8
Download Java SE Development Kit 8 3. Installieren Sie das Paket, indem Sie den folgenden Befehl unten ausgeben:
# rpm -uvh jdk-8u92-linux-x64.Drehzahl
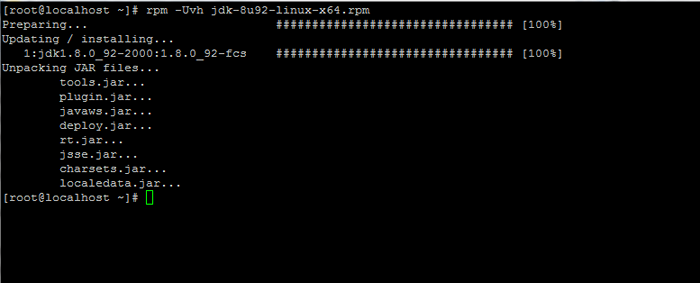 Installieren Sie Java in CentOS 7
Installieren Sie Java in CentOS 7 Schritt 2: Installieren Sie das Hadoop -Framework in CentOS 7
4. Erstellen Sie als Nächst. Das neue Account Home Directory wird in der /opt/hadoop Verzeichnis.
# UserAdd -d /opt /hadoop hadoop # Passwd Hadoop
5. Besuchen Sie auf dem nächsten Schritt Apache Hadoop -Seite, um den Link für die neueste stabile Version zu erhalten und das Archiv auf Ihrem System herunterzuladen.
# curl -o http: // Apache.Javapipe.com/Hadoop/Common/Hadoop-2.7.2/Hadoop-2.7.2.Teer.gz
 Laden Sie das Hadoop -Paket herunter
Laden Sie das Hadoop -Paket herunter 6. Extrahieren Sie das Archiv der Kopie des Verzeichnisinhalts in Hadoop Account Home Path. Stellen Sie außerdem sicher, dass Sie die Berechtigungen der kopierten Dateien entsprechend ändern.
# tar xfz hadoop-2.7.2.Teer.GZ # cp -rf hadoop -2.7.2/*/opt/hadoop/ # chown -r hadoop: hadoop/opt/hadoop/
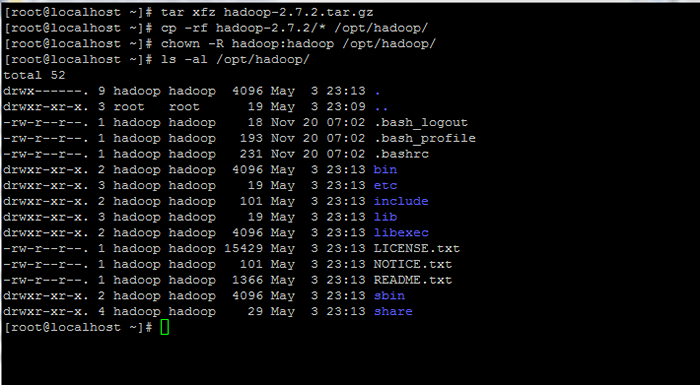 Berechtigungen auf Hadoop extrahieren und festlegen
Berechtigungen auf Hadoop extrahieren und festlegen 7. Als nächstes melden Sie sich bei Hadoop Benutzer und konfigurieren Hadoop Und Java -Umgebungsvariablen auf Ihrem System durch Bearbeiten der .bash_profile Datei.
# Su - Hadoop $ vi .bash_profile
Gehen Sie die folgenden Zeilen am Ende der Datei an:
## Java Env Variablen Exportieren Sie java_home =/usr/java/default export path = $ path: $ java_home/bin export classPath =.: $ Java_home/jre/lib: $ java_home/lib: $ java_home/lib/tools.Krug ## Hadoop Env Variablen Export hadoop_home =/opt/hadoop export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_yarn_home = $ hadoop_home export hadoops.Bibliothek.path = $ hadoop_home/lib/native "Export hadoop_common_lib_native_dir = $ hadoop_home/lib/native Export Path = $ PATH: $ Hadoop_Home/SBIN: $ Hadoop_Home/Bin
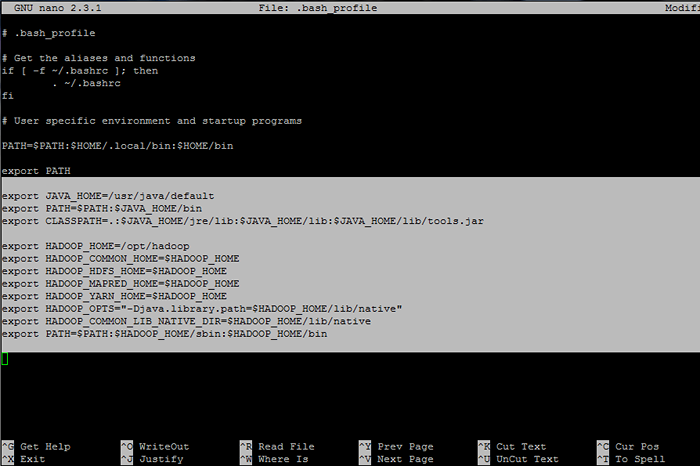 Konfigurieren Sie Hadoop- und Java -Umgebungsvariablen
Konfigurieren Sie Hadoop- und Java -Umgebungsvariablen 8. Initialisieren Sie nun die Umgebungsvariablen und überprüfen Sie ihren Status, indem Sie die folgenden Befehle ausgeben:
$ Quelle .bash_profile $ echo $ hadoop_home $ echo $ java_home
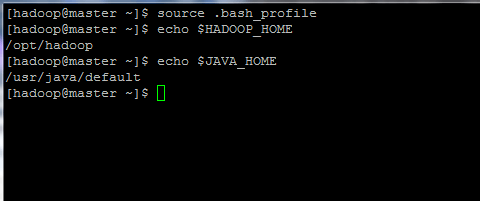 Initialisieren Sie Linux -Umgebungsvariablen
Initialisieren Sie Linux -Umgebungsvariablen 9. Konfigurieren Sie schließlich die basierte Authentifizierung von SSH -Schlüssel für Hadoop Konto durch Ausführen der folgenden Befehle (ersetzen Sie die Hostname oder Fqdn gegen das ssh-copy-id Befehl entsprechend).
Lassen Sie auch die Passphrase leer abgelegt, um sich automatisch über SSH anzumelden.
$ ssh-keygen -t RSA $ ssh-copy-id Master.Hadoop.Lan
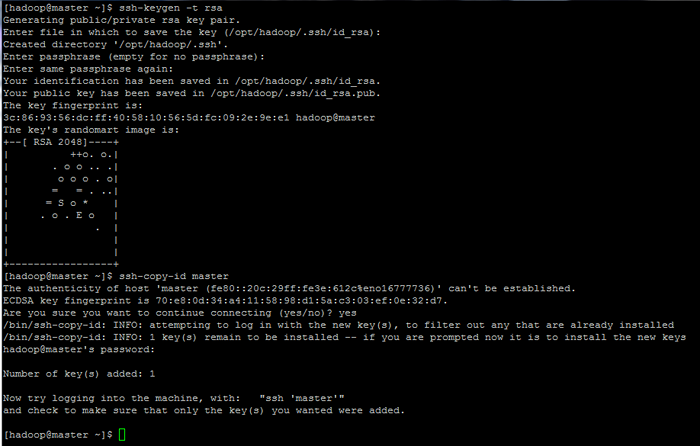 Konfigurieren von SSH -Basis -Authentifizierungsseiten: 1 2 3
Konfigurieren von SSH -Basis -Authentifizierungsseiten: 1 2 3
- « Suchen Sie die Top 10 IP -Adressen, die auf Ihren Apache -Webserver zugreifen
- 10 nützliche Interviewfragen zu Linux -Diensten und Dämonen »