

So installieren und konfigurieren Sie Apache Hadoop auf Centos & Fedora

- 3922
- 168
- Marleen Weight
Hadoop ist schon seit einiger Zeit da und ist zu einer der beliebtesten Open-Source-Big Data-Lösungen geworden. Es verarbeitet Daten in Chargen und ist berühmt für seine skalierbaren, kostengünstigen und verteilten Computerfunktionen. Es ist eines der beliebtesten Open-Source-Frameworks in der Datenanalyse und im Speicherplatz. Als Benutzer können Sie damit Ihre Daten verwalten, diese Daten analysieren und sie erneut speichern - alles auf automatisierte Weise. Wenn Hadoop in Ihrem Fedora -System installiert ist, können Sie mühelos auf wichtige Analysedienste zugreifen.
Dieser Artikel behandelt die Installation von Apache Hadoop auf CentOS- und Fedora -Systemen. In diesem Artikel zeigen wir Ihnen, wie Sie Apache Hadoop auf Fedora für die lokale Nutzung sowie einen Produktionsserver installieren können.
1. Voraussetzungen
Java ist die Hauptanforderung für das Ausführen von Hadoop auf jedem System. Stellen Sie daher sicher, dass Java auf Ihrem System mit dem folgenden Befehl installiert ist. Wenn Sie Java nicht auf Ihrem System installiert haben, verwenden Sie eine der folgenden Links, um es zuerst zu installieren.
- So installieren Sie Java 8 auf CentOS/RHEL 7/6/5
2. Hadoop -Benutzer erstellen
Wir empfehlen, ein normales (noch rootes) Konto für Hadoop -Arbeiten zu erstellen. So erstellen Sie ein Konto mit dem folgenden Befehl.
Adduser Hadoop Passwd Hadoop
Nach dem Erstellen des Konto. Um dies zu tun, verwenden Sie die folgenden Befehle aus, um die folgenden Befehle auszuführen.
Su -Hadoop ssh -keygen -t rsa -p "-f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keys chmod 0600 ~/.ssh/autorized_keys
Überprüfen Sie die wichtige Anmeldung. Der folgende Befehl sollte nicht nach dem Passwort fragen, aber das erste Mal, dass das Hinzufügen von RSA zu der Liste der bekannten Hosts auffordert.
SSH LOCALHOST -Ausgang
3. Laden Sie Hadoop 3 herunter.1 Archiv
Laden Sie in diesem Schritt Hadoop 3 herunter.1 Quellarchivdatei mit dem folgenden Befehl. Sie können auch einen alternativen Download Mirror auswählen, um die Download -Geschwindigkeit zu erhöhen.
CD ~ WGet http: // www-euu.Apache.org/dist/hadoop/Common/Hadoop-3.1.0/Hadoop-3.1.0.Teer.gz tar xzf hadoop-3.1.0.Teer.GZ MV Hadoop-3.1.0 Hadoop
4. Setup Hadoop Pseudo-verteiltem Modus
4.1. Setup Hadoop -Umgebungsvariablen einrichten
Zunächst müssen wir Umgebungsvariablen durch Hadoop einstellen. Bearbeiten ~/.bashrc Datei und Anhängen der folgenden Werte am Ende der Datei.
Export hadoop_home =/home/hadoop/hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop hadoop export hadoop hadoop_hdfs_home Hadoop_Home/sbin: $ hadoop_home/bin
Wenden Sie nun die Änderungen in der aktuellen laufenden Umgebung an
Quelle ~/.bashrc
Jetzt bearbeiten $ Hadoop_home/etc/hadoop/hadoop-env.Sch Datei und festgelegt Java_Home Umgebungsvariable. Ändern Sie den Java -Pfad gemäß der Installation Ihres Systems. Dieser Pfad kann je nach Ihrer Betriebssystemversion und der Installationsquelle variieren. Stellen Sie also sicher, dass Sie den richtigen Pfad verwenden.
Exportieren Sie java_home =/usr/lib/jvm/java-8-oracle
4.2. Setup Hadoop -Konfigurationsdateien einrichten
Hadoop hat viele Konfigurationsdateien, die gemäß den Anforderungen Ihrer Hadoop -Infrastruktur konfiguriert werden müssen. Beginnen wir mit der Konfiguration mit Basic Hadoop Single Knode Cluster -Setup. Navigieren Sie zunächst zu unten
CD $ hadoop_home/etc/hadoop
Kernstelle bearbeiten.xml
fs.Standard.Name HDFS: // localhost: 9000
HDFS-Site bearbeiten.xml
DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode
Mapred-Site bearbeiten.xml
Karte verkleinern.Rahmen.Nennen Sie Garn
Garnstelle bearbeiten.xml
Garn.NodeManager.AUX-Service MapReduce_Shuffle
4.3. Formatnamenode
Formatieren Sie nun den Namenode mit dem folgenden Befehl und stellen Sie sicher, dass das Speicherverzeichnis ist
HDFS NAMENODE -Format
Beispielausgabe:
Warnung:/Home/Hadoop/Hadoop/Protokolle existieren nicht. Erstellen. 2018-05-02 17: 52: 09.678 Info Namenode.Namenode: Startup_msg: /************************************************ ****************************************.0.1.1 startup_msg: args = [-format] startup_msg: Version = 3.1.0… 2018-05-02 17: 52: 13.717 Info gemeinsam.Speicher: Speicherverzeichnis/Home/Hadoop/Hadoopdata/HDFS/Namenode wurde erfolgreich formatiert. 2018-05-02 17: 52: 13.806 Info Namenode.FSImageFormatProtobuf: Bilddatei speichern/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.CKPT_0000000000000000000 mit NO-Komprimierung 2018-05-02 17: 52: 14.161 Info Namenode.FSimageFormatProtobuf: Bilddatei/Home/Hadoop/Hadoopdata/HDFS/NAMENODE/Current/Fsimage.CKPT_00000000000000000 von Größe 391 Bytes in 0 Sekunden gespeichert . 2018-05-02 17: 52: 14.224 Info Namenode.NnstorageretentionManager: Aufbewahrung 1 Bilder mit TXID> = 0 2018-05-02 17: 52: 14.282 Info Namenode.Namenode: Shutdown_MSG: /************************************************************************* ****************************************.0.1.1 ************************************************************ ***********/
5. Starten Sie Hadoop Cluster
Beginnen wir Ihren Hadoop -Cluster mit den von Hadoop bereitgestellten Skripten. Navigieren Sie einfach zu Ihrem $ hadoop_home/sbin -Verzeichnis und führen Sie die Skripte nacheinander aus.
CD $ hadoop_home/sbin/
Jetzt rennen Start-dfs.Sch Skript.
./start-dfs.Sch
Beispielausgabe:
Starten von Namenoden auf [localhost] Starten von Datanoden Starten sekundärer Namenoden [Tecadmin] 2018-05-02 18: 00: 32.565 Warn Util.NativeCodeloader: Die native Hadoop-Bibliothek für Ihre Plattform kann nicht geladen werden
Jetzt rennen Start marnt.Sch Skript.
./starten Sie das Werk.Sch
Beispielausgabe:
Ressourcenanager Starten von NodeManagers starten
6. Zugriff auf Hadoop -Dienste im Browser
Hadoop Namenode begann mit Port 9870 Standard. Greifen Sie in Ihrem bevorzugten Webbrowser auf Ihren Server auf Port 9870 zu.
http: // svr1.Tecadmin.Netz: 9870/
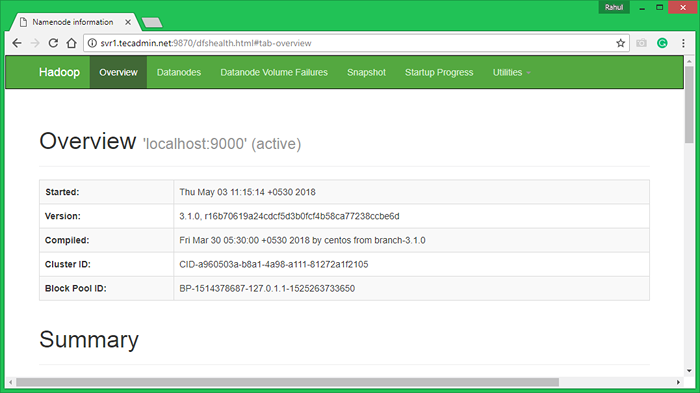
Greifen Sie nun auf Port 8042 zu, um die Informationen über den Cluster und alle Anwendungen zu erhalten
http: // svr1.Tecadmin.Netz: 8042/
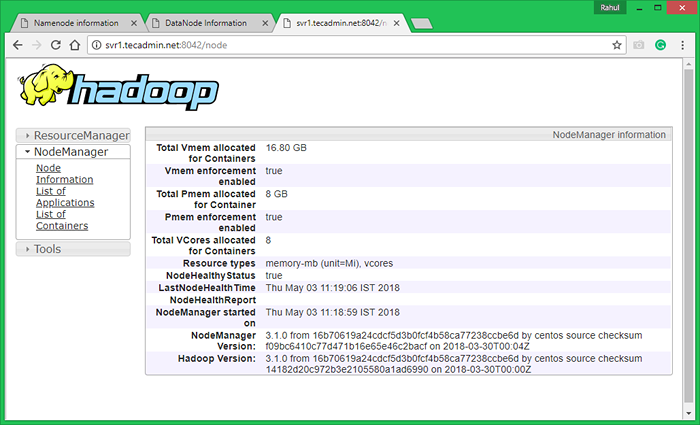
Greifen Sie auf Port 9864 zu, um Details über Ihren Hadoop -Knoten zu erhalten.
http: // svr1.Tecadmin.Netz: 9864/
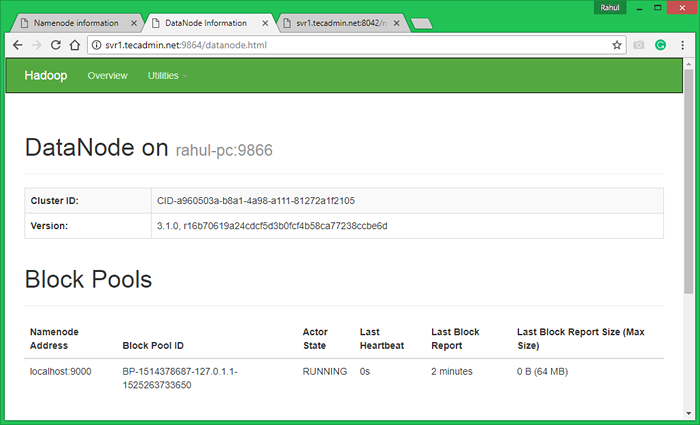
7. Testen Sie Hadoop Single -Knoten -Setup
7.1. Machen Sie die HDFS -Verzeichnisse mit den folgenden Befehlen erforderlich.
bin/hdfs dfs -mkdir/user bin/hdfs dfs -mkdir/user/hadoop
7.2. Kopieren Sie alle Dateien aus lokalem Dateisystem/var/log/httpd nach Hadoop -Distributed Dateisystem unter Verwendung des folgenden Befehls
Bin/HDFS DFS -put/var/log/apache2 -Protokolle
7.3. Durchsuchen. Sie sehen einen Apache2 -Ordner in der Liste. Klicken Sie auf den Ordneramen, um sie zu öffnen, und Sie finden dort alle Protokolldateien dort.
http: // svr1.Tecadmin.Netz: 9870/Explorer.html#/user/hadoop/logs/
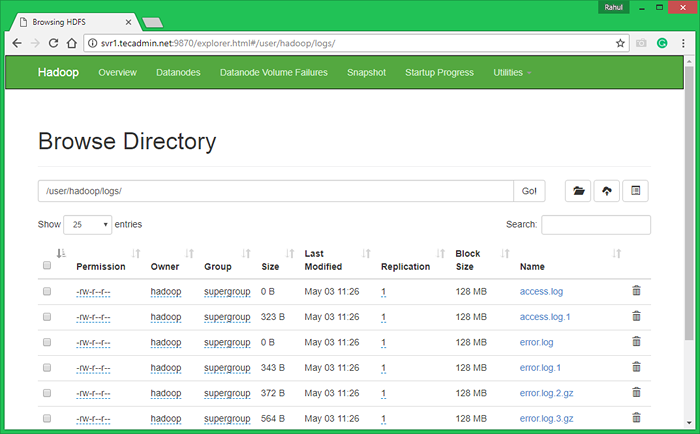
7.4 - Kopieren Sie nun das Protokoll -Verzeichnis für das Hadoop -Distributed Dateisystem in das lokale Dateisystem.
bin/hdfs dfs -get logs/tmp/logs ls -l/tmp/logs/
Sie können dieses Tutorial auch überprüfen, um WordCount MapReduce -Beispiel mit der Befehlszeile auszuführen.
- « 10 Dinge nach der Installation von Ubuntu & Linux Mint zu tun
- So entfernen Sie das JavaScript -Array -Element nach Wert »