

So installieren und konfigurieren Sie Hadoop auf Ubuntu 20.04

- 3139
- 582
- Ilja Köpernick
Hadoop ist ein kostenloses Software-Framework für Open-Source- und Java-basierte Software, der für die Speicherung und Verarbeitung großer Datensätze auf Maschinenclustern verwendet wird. Es verwendet HDFs, um ihre Daten zu speichern und diese Daten mithilfe von MapReduce zu verarbeiten. Es ist ein Ökosystem von Big -Data -Tools, die hauptsächlich für Data Mining und maschinelles Lernen verwendet werden.
Apache Hadoop 3.3 ist mit spürbaren Verbesserungen und vielen Fehlerbehebungen in den vorherigen Veröffentlichungen verbunden. Es verfügt über vier Hauptkomponenten wie Hadoop Common, HDFs, Garn und MapReduce.
In diesem Tutorial erklärt Sie, wie Sie Apache Hadoop auf Ubuntu 20 installieren und konfigurieren können.04 LTS Linux -System.
Schritt 1 - Java installieren
Hadoop ist in Java geschrieben und unterstützt nur Java Version 8. Hadoop Version 3.3 und die neuesten unterstützen auch die Java 11 -Laufzeit sowie Java 8.
Sie können OpenJDK 11 aus den Standard -APT -Repositories installieren:
sudo APT -Updatesudo apt installieren openjdk-11-jdk
Überprüfen Sie nach der Installation die installierte Version von Java mit dem folgenden Befehl:
Java -Version Sie sollten die folgende Ausgabe erhalten:
OpenJDK -Version "11.0.11 "2021-04-20 Openjdk Laufzeitumgebung (Build 11.0.11+9-UBUNTU-0UBUNTU2.20.04) OpenJDK 64-Bit Server VM (Build 11.0.11+9-UBUNTU-0UBUNTU2.20.04, gemischter Modus, Freigabe)
Schritt 2 - Erstellen Sie einen Hadoop -Benutzer
Es ist eine gute Idee, einen separaten Benutzer zu erstellen, der Hadoop aus Sicherheitsgründen ausführt.
Führen Sie den folgenden Befehl aus, um einen neuen Benutzer mit Namen Hadoop zu erstellen:
sudo adduser hadoop Geben Sie das neue Passwort wie unten gezeigt an und bestätigen Sie sie:
Hinzufügen von Benutzern 'Hadoop'… Hinzufügen einer neuen Gruppe 'Hadoop' (1002)… Hinzufügen neuer Benutzer 'Hadoop' (1002) mit Gruppe 'Hadoop'… Erstellen von Home Directory '/Home/Hadoop'… Kopieren von Dateien aus '/etc/skel' 'kopieren … Neues Passwort: Neues Passwort eingeben: PassWD: Passwort aktualisiert die Benutzerinformationen für Hadoop -Geben Sie den neuen Wert ein oder drücken Sie die Eingabetaste für den Standardnamen []: Zimmernummer []: Arbeit Telefon []: Home Telefon []: Andere []: Ist die Informationen korrekt? [Y/n] y
Schritt 3 - Konfigurieren Sie die SSH -Basis der Key -basierte Authentifizierung
Als nächstes müssen Sie eine kennwortlose SSH -Authentifizierung für das lokale System konfigurieren.
Ändern Sie zunächst den Benutzer mit dem folgenden Befehl in Hadoop:
Su - Hadoop Führen Sie als nächstes den folgenden Befehl aus, um öffentliche und private Schlüsselpaare zu generieren:
ssh -keygen -t RSA Sie werden gebeten, den Dateinamen einzugeben. Drücken Sie einfach die Eingabetaste, um den Vorgang zu vervollständigen:
Generieren von öffentlichem/privatem RSA -Schlüsselpaar. Geben Sie die Datei ein, in der der Schlüssel speichern kann (/home/hadoop/.SSH/ID_RSA): Verzeichnis erstellt '/home/hadoop/.ssh '. Geben Sie Passphrase ein (ohne Passphrase leer): Geben Sie erneut die gleiche Passphrase ein: Ihre Identifizierung wurde in/home/hadoop/gespeichert/wurde gespeichert.ssh/id_rsa Ihr öffentlicher Schlüssel wurde in/home/hadoop/gespeichert/.ssh/id_rsa.Pub the Key Fingerabdruck lautet: SHA256: QSA2SYEISWP0HD+UXXXI0J9MSORJKDGIBKFBM3EJYIK [E-Mail geschützt] Das Randomart-Bild des Schlüssels ist:+--- [RSA 3072] ----+|.+ | |… Oo++.O | |. oo. B . | | o… + o * . | | = ++ o o s | |.++o+ o | |.+.+ + . o | | o . o * o . | | E + . | +---- [SHA256]-----+
Gehen Sie als nächstes die generierten öffentlichen Schlüssel von ID_RSA an.Pub to Authorized_keys und setzen Sie die richtige Berechtigung:
Katze ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keyschmod 640 ~/.ssh/autorized_keys
Überprüfen Sie als nächstes die passwortlose SSH -Authentifizierung mit dem folgenden Befehl:
ssh localhost Sie werden gebeten, Hosts zu authentifizieren, indem Sie bekannte Hosts RSA Keys hinzufügen. Geben Sie Ja ein und drücken Sie die Eingabetaste, um den Localhost zu authentifizieren:
Die Authentizität von Host 'Localhost (127.0.0.1) 'kann nicht festgelegt werden. ECDSA Key Fingerabdruck ist SHA256: JFQDVBM3ZTPHUPGD5OMJ4CLVIH6TZIRZ2GD3BDNQGMQ. Sind Sie sicher, dass Sie sich weiter verbinden möchten (ja/nein/[Fingerabdruck])? Ja
Schritt 4 - Hadoop installieren
Ändern Sie zunächst den Benutzer mit dem folgenden Befehl in Hadoop:
Su - Hadoop Laden Sie als nächstes die neueste Version von Hadoop mit dem WGet -Befehl herunter:
WGet https: // downloads.Apache.org/hadoop/Common/Hadoop-3.3.0/Hadoop-3.3.0.Teer.gz Nach dem Herunterladen extrahieren Sie die heruntergeladene Datei:
tar -xvzf hadoop -3.3.0.Teer.gz Benennen Sie als nächstes das extrahierte Verzeichnis in Hadoop um:
MV Hadoop-3.3.0 Hadoop Als nächstes müssen Sie Hadoop- und Java -Umgebungsvariablen auf Ihrem System konfigurieren.
Öffne das ~/.bashrc Datei in Ihrem bevorzugten Texteditor:
Nano ~//.bashrc Fügen Sie die folgenden Zeilen an die Datei hinzu. Sie können den Standort von Java_Home finden, indem Sie laufend sind DirName $ (DirName $ (Readlink -f $ (was Java))) Befehl zum Terminal.
exportieren java_home =/usr/lib/jvm/java-11-openjdk-amd64 export hadoop_home =/home/hadoop/hadoop Export hadoop_install = $ hadoop_home export hadoop_mapred_home hadoop_home hadoop_home hadoop_homehome Hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home/lib/native Export Path = $ path: $ hadoop_home/sbin: $ hadoop_home/bin export hadoop_opts = "-djava.Bibliothek.path = $ hadoop_home/lib/native "
Speichern und schließen Sie die Datei. Aktivieren Sie dann die Umgebungsvariablen mit dem folgenden Befehl:
Quelle ~/.bashrc Öffnen Sie als nächstes die Hadoop -Umgebungsvariablendatei:
nano $ hadoop_home/etc/hadoop/hadoop-env.Sch Stellen Sie erneut das Java_Home in der Hadoop -Umgebung ein.
Exportieren Sie java_home =/usr/lib/jvm/java-11-openjdk-amd64
Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Schritt 5 - Hadoop konfigurieren
Zunächst müssen Sie die genannten Verzeichnisse in Hadoop Home -Verzeichnis erstellen:
Führen Sie den folgenden Befehl aus, um beide Verzeichnisse zu erstellen:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Bearbeiten Sie als nächstes die Kernstelle.xml Datei und Aktualisieren Sie mit Ihrem System Hostname:
Nano $ hadoop_home/etc/hadoop/core-Site.xml Ändern Sie den folgenden Namen gemäß Ihrem System -Hostnamen:
fs.defaultfs hdfs: // hadoop.Tecadmin.com: 9000| 123456 | fs.defaultfs hdfs: // hadoop.Tecadmin.com: 9000 |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die HDFS-Site.xml Datei:
nano $ hadoop_home/etc/hadoop/hdfs-site.xml Ändern Sie den Verzeichnispfad von Namenode und Datanode, wie unten gezeigt:
DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode| 1234567891011121314151617 | DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die Mapred-Site.xml Datei:
Nano $ hadoop_home/etc/hadoop/mapred-site.xml Nehmen Sie die folgenden Änderungen vor:
Karte verkleinern.Rahmen.Nennen Sie Garn| 123456 | Karte verkleinern.Rahmen.Nennen Sie Garn |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die Garnstelle.xml Datei:
Nano $ hadoop_home/etc/hadoop/arnseitenstelle.xml Nehmen Sie die folgenden Änderungen vor:
Garn.NodeManager.AUX-Service MapReduce_Shuffle| 123456 | Garn.NodeManager.AUX-Service MapReduce_Shuffle |
Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Schritt 6 - Start Hadoop Cluster
Bevor Sie mit dem Hadoop -Cluster beginnen. Sie müssen den Namenode als Hadoop -Benutzer formatieren.
Führen Sie den folgenden Befehl aus, um den Hadoop Namenode zu formatieren:
HDFS NAMENODE -Format Sie sollten die folgende Ausgabe erhalten:
2020-11-23 10: 31: 51.318 Info Namenode.NnstorageretentionManager: Aufbewahrung 1 Bilder mit TXID> = 0 2020-11-23 10: 31: 51,323 Info Namenode.FSIMAGE: FSIMageSaver Clean Checkpoint: TXID = 0 Beim Treffen mit dem Herunterfahren. 2020-11-23 10: 31: 51.323 Info Namenode.Namenode: Shutdown_MSG: /************************************************************************* ************************************.Tecadmin.net/127.0.1.1 ************************************************************ ***********/
Führen Sie nach dem Formatieren des Namenode den folgenden Befehl aus, um den Hadoop -Cluster zu starten:
Start-dfs.Sch Sobald die HDFs erfolgreich gestartet sind, sollten Sie die folgende Ausgabe erhalten:
Namenenoden auf [Hadoop.Tecadmin.com] hadoop.Tecadmin.Com: Warnung: Dauerhaft 'Hadoop hinzugefügt.Tecadmin.Com, Fe80 :: 200: 2dff: Fe3A: 26CA%ETH0 '(ECDSA) Auf die Liste der bekannten Hosts. DATANODES STARTEN STORN SECPERSE NAMENODEN [Hadoop.Tecadmin.com]
Starten Sie als nächstes den Garnservice wie unten gezeigt:
Start marnt.Sch Sie sollten die folgende Ausgabe erhalten:
Ressourcenanager Starten von NodeManagers starten
Sie können jetzt den Status aller Hadoop -Dienste über den JPS -Befehl überprüfen:
JPS Sie sollten alle laufenden Dienste in der folgenden Ausgabe sehen:
18194 Namenode 18822 NodeManager 17911 SekaryNamenode 17720 Datanode 18669 Resourcemanager 19151 JPS
Schritt 7 - Firewall einstellen
Hadoop fängt jetzt an und hört die Ports 9870 und 8088 an. Als nächstes müssen Sie diese Ports über die Firewall erlauben.
Führen Sie den folgenden Befehl aus, um Hadoop -Verbindungen durch die Firewall zu ermöglichen:
Firewall-CMD-Permanent --Add-Port = 9870/TCPFirewall-CMD-Permanent --Add-Port = 8088/TCP
Laden Sie als Nächstes den Firewalld -Dienst neu, um die Änderungen anzuwenden:
Firewall-CMD-Reload Schritt 8 - Zugriff auf Hadoop Namenode und Ressourcenmanager
Öffnen Sie Ihren Webbrowser und besuchen Sie die URL http: // your-server-ip: 9870. Sie sollten den folgenden Bildschirm sehen:
http: // hadoop.Tecadmin.Netz: 9870
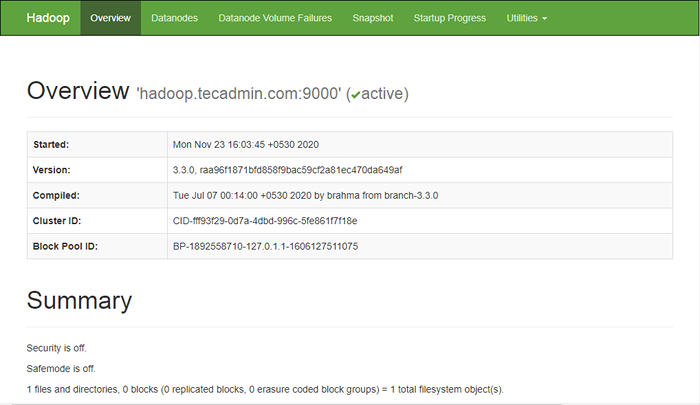
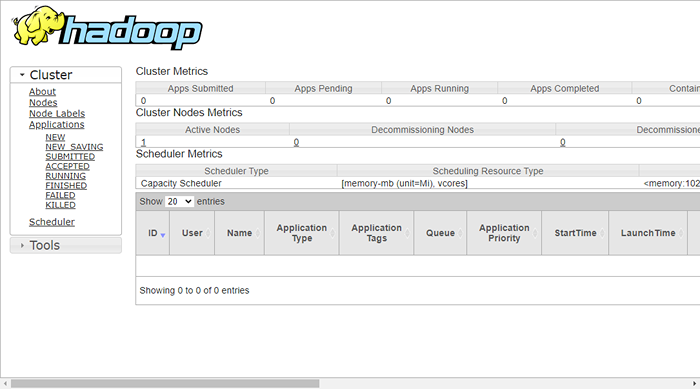
Um auf Ressourcen zuzugreifen, öffnen Sie Ihren Webbrowser und besuchen Sie die URL http: // your-server-ip: 8088. Sie sollten den folgenden Bildschirm sehen:
http: // hadoop.Tecadmin.Netz: 8088
Schritt 9 - Überprüfen Sie den Hadoop -Cluster
Zu diesem Zeitpunkt ist der Hadoop -Cluster installiert und konfiguriert. Als nächstes erstellen wir einige Verzeichnisse im HDFS -Dateisystem, um den Hadoop zu testen.
Erstellen wir einige Verzeichnisse im HDFS -Dateisystem mit dem folgenden Befehl:
HDFS DFS -MKDIR /Test1HDFS DFS -MKDIR /Protokolle
Führen Sie als nächstes den folgenden Befehl aus, um das obige Verzeichnis aufzulisten:
HDFS DFS -LS / Sie sollten die folgende Ausgabe erhalten:
Gefunden 3 Elemente DRWXR-XR-X-Hadoop Supergroup 0 2020-11-23 10:56 /Protokolle DRWXR-XR-X-Hadoop Supergroup 0 2020-11-23 10:51 /Test1
Stellen Sie auch einige Dateien an das Hadoop -Dateisystem ein. Zum Beispiel Protokolldateien vom Host -Computer zum Hadoop -Dateisystem einlegen.
HDFS DFS -put/var/log/*/logs/ Sie können auch die oben genannten Dateien und das Verzeichnis in der Weboberfläche Hadoop Namenode überprüfen.
Gehen Sie zur namenode -Weboberfläche, klicken Sie auf die Utilities => durchsuchen Sie das Dateisystem. Sie sollten Ihre Verzeichnisse sehen, die Sie früher im folgenden Bildschirm erstellt haben:
http: // hadoop.Tecadmin.Netz: 9870/Explorer.html
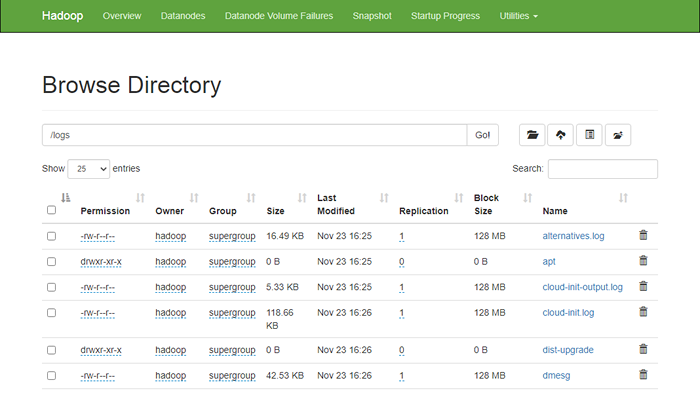
Schritt 10 - Hadoop Cluster stoppen
Sie können auch den Hadoop -Namenode- und Garnservice jederzeit stoppen, indem Sie das ausführen Stopp-DFS.Sch Und Stoppen Sie das Werk.Sch Skript als Hadoop -Benutzer.
Führen Sie den folgenden Befehl als Hadoop -Benutzer aus, um den Hadoop -Namenode -Dienst zu stoppen:
Stopp-DFS.Sch Führen Sie den folgenden Befehl aus, um den Hadoop Resource Manager -Service zu stoppen:
Stoppen Sie das Werk.Sch Abschluss
Dieses Tutorial wurde Ihnen ein Schritt-für-Schritt-Tutorial erklärt, Hadoop auf Ubuntu 20 zu installieren und zu konfigurieren.04 Linux -System.
- « So installieren Sie Wein 8.0 auf Linuxmint 21/20
- So installieren Sie Git auf Ubuntu 22.04 /20.04 »