

So installieren Sie Apache Hadoop auf Ubuntu 22.04

- 1343
- 301
- Lana Saumweber
Das Verständnis unstrukturierter Daten und die Analyse massiver Datenmengen ist heute ein anderes Ballspiel. Und so haben Unternehmen auf Apache Hadoop und andere verwandte Technologien zurückgegriffen, um ihre unstrukturierten Daten effizienter zu verwalten. Nicht nur Unternehmen, sondern auch Einzelpersonen verwenden Apache Hadoop für verschiedene Zwecke, z. B. die Analyse großer Datensätze oder das Erstellen einer Website, auf der Benutzeranfragen verarbeitet werden können. Die Installation von Apache Hadoop auf Ubuntu scheint jedoch für Benutzer, die neu in der Welt der Linux -Server sind, eine schwierige Aufgabe zu sein. Glücklicherweise müssen Sie kein erfahrener Systemadministrator sein, um Apache Hadoop auf Ubuntu zu installieren.
Mit dem folgenden Schritt-für-Schritt-Installationshandbuch können Sie den gesamten Vorgang vom Herunterladen der Software bis zur Konfiguration des Servers problemlos durchführen. In diesem Artikel werden wir erklären, wie Apache Hadoop auf Ubuntu 22 installiert werden kann.04 LTS -System. Dies kann auch für andere Ubuntu -Versionen verwendet werden.
Schritt 1: Installieren Sie Java Development Kit
Java ist eine notwendige Komponente von Apache Hadoop. Sie müssen daher ein Java -Entwicklungskit auf allen Knoten in Ihrem Netzwerk herunterladen und installieren, in denen Hadoop installiert wird. Sie können entweder die JRE oder JDK herunterladen. Wenn Sie nur Hadoop ausführen möchten, ist JRE ausreichend. Wenn Sie jedoch Anwendungen erstellen möchten, die auf Hadoop ausgeführt werden, müssen Sie die JDK installieren. Die neueste Version von Java, die Hadoop unterstützt, ist Java 8 und 11. Sie können dies auf der Website von Apache überprüfen und die entsprechende Version von Java abhängig von Ihrem Betriebssystem herunterladen.
- Die Standard -Ubuntu -Repositories enthalten Java 8 und Java 11 beide. Verwenden Sie den folgenden Befehl, um es zu installieren.
sudo APT Update && sudo APT installieren - Sobald Sie es erfolgreich installiert haben, überprüfen Sie die aktuelle Java -Version:
Java -Version Überprüfen Sie die Java -Version
Überprüfen Sie die Java -Version - Sie finden den Ort des Verzeichnisses java_home, indem Sie den folgenden Befehl ausführen. Dies wird in diesem Artikel die neueste benötigt sein.
DirName $ (DirName $ (Readlink -f $ (was Java))) Überprüfen Sie den Standort Java_Home
Überprüfen Sie den Standort Java_Home
Schritt 2: Benutzer für Hadoop erstellen
Alle Hadoop -Komponenten werden als Benutzer ausgeführt, den Sie für Apache Hadoop erstellen, und der Benutzer wird auch zur Anmeldung an der Weboberfläche von Hadoop verwendet. Sie können ein neues Benutzerkonto mit dem Befehl „sudo“ erstellen oder ein Benutzerkonto mit "Root" -Verwendungen erstellen. Das Benutzerkonto mit Root -Berechtigungen ist sicherer, ist jedoch möglicherweise nicht so bequem für Benutzer, die mit der Befehlszeile nicht vertraut sind.
- Führen Sie den folgenden Befehl aus, um einen neuen Benutzer mit dem Namen zu erstellen "Hadoop":
sudo adduser hadoop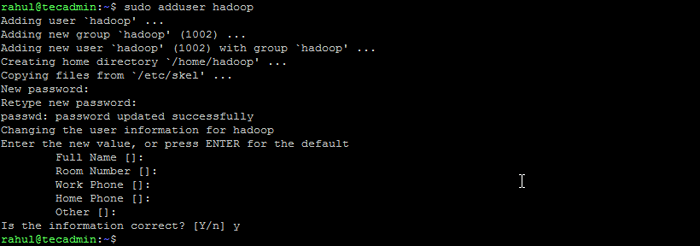 Hadoop -Benutzer erstellen
Hadoop -Benutzer erstellen - Wechseln Sie zum neu erstellten Hadoop -Benutzer:
Su - Hadoop - Konfigurieren Sie nun Kennwort ohne SSH-Zugriff für den neu erstellten Hadoop-Benutzer. Generieren Sie zuerst einen SSH -Tastatur:
ssh -keygen -t RSA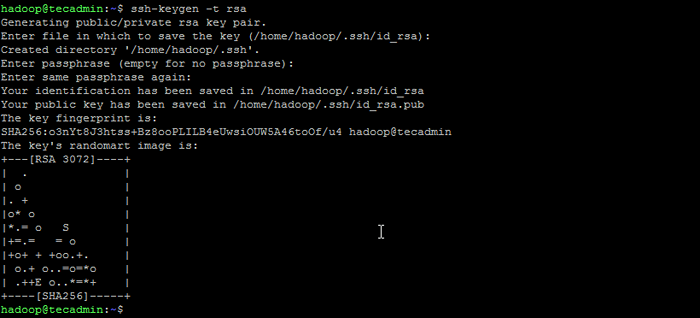 Generieren Sie das SSH -Schlüsselpaar
Generieren Sie das SSH -Schlüsselpaar - Kopieren Sie den generierten öffentlichen Schlüssel in die autorisierte Schlüsseldatei und setzen Sie die richtigen Berechtigungen fest:
Katze ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keyschmod 640 ~/.ssh/autorized_keys - Versuchen Sie nun, SSH zum lokalen Haus.
ssh localhostSie werden gebeten, Hosts zu authentifizieren, indem Sie bekannte Hosts RSA Keys hinzufügen. Geben Sie Ja ein und drücken Sie die Eingabetaste, um den Localhost zu authentifizieren:
 Verbinden Sie SSH mit Localhost
Verbinden Sie SSH mit Localhost
Schritt 3: Installieren Sie Hadoop auf Ubuntu
Sobald Sie Java installiert haben, können Sie Apache Hadoop und alle zugehörigen Komponenten, einschließlich Bienenstock, Schwein, Sqoop usw., herunterladen. Die neueste Version finden Sie auf der offiziellen Hadoop -Download -Seite. Stellen Sie sicher, dass Sie das binäre Archiv herunterladen (nicht die Quelle).
- Verwenden Sie den folgenden Befehl, um Hadoop 3 herunterzuladen.3.4:
WGet https: // dlcdn.Apache.org/hadoop/Common/Hadoop-3.3.4/Hadoop-3.3.4.Teer.gz - Sobald Sie die Datei heruntergeladen haben, können Sie sie auf Ihrer Festplatte in einen Ordner entpacken.
Tar XZF Hadoop-3.3.4.Teer.gz - Benennen Sie den extrahierten Ordner um, um Versionsinformationen zu entfernen. Dies ist ein optionaler Schritt, aber wenn Sie nicht umbenennen möchten, passen Sie die verbleibenden Konfigurationspfade an.
MV Hadoop-3.3.4 Hadoop - Als nächstes müssen Sie Hadoop- und Java -Umgebungsvariablen auf Ihrem System konfigurieren. Öffnen Sie das ~//.BASHRC -Datei in Ihrem bevorzugten Texteditor:
Nano ~//.bashrcFügen Sie die folgenden Zeilen der Datei hinzu. Sie können den Standort java_home durch Laufen finden
exportieren java_home =/usr/lib/jvm/java-11-openjdk-amd64 export hadoop_home =/home/hadoop/hadoop Export hadoop_install = $ hadoop_home export hadoop_mapred_home hadoop_home hadoop_home hadoop_homehome Hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home/lib/native Export Path = $ path: $ hadoop_home/sbin: $ hadoop_home/bin export hadoop_opts = "-djava.Bibliothek.path = $ hadoop_home/lib/native "DirName $ (DirName $ (Readlink -f $ (was Java)))Befehl am Terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ lib/norryExport path = $ path: $ hadoop_home/sbin: $ hadoop_home/binexport hadoop_opts = "-djava.Bibliothek.path = $ hadoop_home/lib/native " Speichern Sie die Datei und schließen Sie sie.
- Laden Sie die obige Konfiguration in der aktuellen Umgebung.
Quelle ~/.bashrc - Sie müssen auch konfigurieren Java_Home In Hadoop-Env.Sch Datei. Bearbeiten Sie die Hadoop -Umgebungsvariablendatei im Texteditor:
nano $ hadoop_home/etc/hadoop/hadoop-env.SchSuchen Sie nach dem "exportieren java_home" und konfigurieren Sie ihn mit dem in Schritt 1 gefundenen Wert. Siehe den folgenden Screenshot:
 Setzen Sie Java_Home
Setzen Sie Java_HomeSpeichern Sie die Datei und schließen Sie sie.
Schritt 4: Hadoop konfigurieren
Als nächstes konfigurieren Sie Hadoop -Konfigurationsdateien, die im usw. Verzeichnis verfügbar sind.
- Zuerst müssen Sie die erstellen Namenode Und Datanode Verzeichnisse im Hadoop User Home Directory. Führen Sie den folgenden Befehl aus, um beide Verzeichnisse zu erstellen:
mkdir -p ~/hadoopdata/hdfs/namenode, datanode - Bearbeiten Sie als nächstes die Kernstelle.xml Datei und Aktualisieren Sie mit Ihrem System Hostname:
Nano $ hadoop_home/etc/hadoop/core-Site.xmlÄndern Sie den folgenden Namen gemäß Ihrem System -Hostnamen:
fs.defaultFS HDFS: // localhost: 9000123456 fs.defaultFS HDFS: // localhost: 9000 Speichern und schließen Sie die Datei.
- Bearbeiten Sie dann die HDFS-Site.xml Datei:
nano $ hadoop_home/etc/hadoop/hdfs-site.xmlÄndern Sie die Verzeichnispfade von Namenode und Datanode, wie unten gezeigt:
DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode12345678910111213141516 DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode Speichern und schließen Sie die Datei.
- Bearbeiten Sie dann die Mapred-Site.xml Datei:
Nano $ hadoop_home/etc/hadoop/mapred-site.xmlNehmen Sie die folgenden Änderungen vor:
Karte verkleinern.Rahmen.Nennen Sie Garn123456 Karte verkleinern.Rahmen.Nennen Sie Garn Speichern und schließen Sie die Datei.
- Bearbeiten Sie dann die Garnstelle.xml Datei:
Nano $ hadoop_home/etc/hadoop/arnseitenstelle.xmlNehmen Sie die folgenden Änderungen vor:
Garn.NodeManager.AUX-Service MapReduce_Shuffle123456 Garn.NodeManager.AUX-Service MapReduce_Shuffle Speichern Sie die Datei und schließen Sie sie.
Schritt 5: Start Hadoop Cluster
Bevor Sie mit dem Hadoop -Cluster beginnen. Sie müssen den Namenode als Hadoop -Benutzer formatieren.
- Führen Sie den folgenden Befehl aus, um den Hadoop Namenode zu formatieren:
HDFS NAMENODE -FormatSobald das Namenode -Verzeichnis erfolgreich mit dem HDFS -Dateisystem formatiert wurde, sehen Sie die Nachricht “Speicherverzeichnis/Home/Hadoop/Hadoopdata/HDFS/Namenode wurde erfolgreich formatiert“.
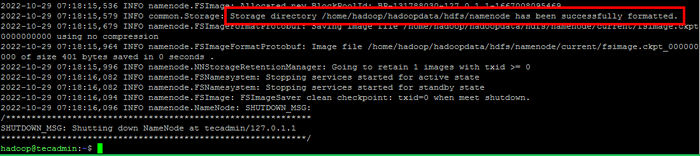 Formatnamenode
Formatnamenode - Starten Sie dann den Hadoop -Cluster mit dem folgenden Befehl.
All.Sch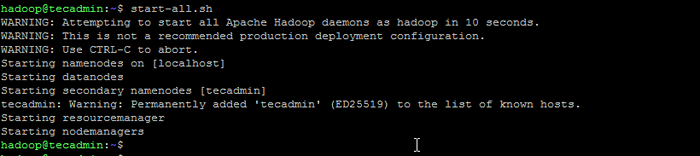 Starten Sie Hadoop -Dienste
Starten Sie Hadoop -Dienste - Sobald alle Dienste begonnen haben, können Sie auf die Hadoop unter: http: // localhost: 9870 zugreifen

- Und die Hadoop -Anwendungsseite ist unter http: // localhost: 8088 verfügbar

Abschluss
Die Installation von Apache Hadoop auf Ubuntu kann eine schwierige Aufgabe für Neulinge sein, insbesondere wenn sie nur die Anweisungen in der Dokumentation befolgen. Zum Glück bietet dieser Artikel eine Schritt-für-Schritt-Anleitung, mit der Sie Apache Hadoop auf Ubuntu mühelos installieren können. Alles, was Sie tun müssen, ist die in diesem Artikel aufgeführten Anweisungen zu befolgen, und Sie können sicher sein, dass Ihre Hadoop -Installation in kürzester Zeit in Betrieb ist.