

So installieren Sie Apache Kafka auf Ubuntu 22.04

- 2182
- 257
- Levke Harnapp
Apache Kafka ist eine von der Apache Software Foundation entwickelte Open-Source-Plattform für verteilte Event-Streaming-Plattform. Dies ist in Scala- und Java -Programmiersprachen geschrieben. Sie können Kafka auf jeder Plattform installieren, die die Java -Programmiersprache unterstützt.
Dieses Tutorial bietet Ihnen Schritt-für-Schritt-Anweisungen zur Installation von Apache Kafka auf Ubuntu 22.04 LTS Linux -System. Sie lernen auch, Themen in Kafka zu erstellen und Produzent und Verbraucherknoten zu führen.
Voraussetzungen
Sie müssen sudo privilegiertes Konto Zugriff auf die Ubuntu 22 haben.04 Linux -System.
Schritt 1 - Java installieren
Wir können den Apache Kafka -Server auf Systemen ausführen, die Java unterstützen. Stellen Sie also sicher, dass Java auf Ihrem Ubuntu -System installiert ist.
Verwenden Sie die folgenden Befehle, um OpenJDK auf Ihrem Ubuntu -System von den offiziellen Repositories zu installieren.
sudo APT -Updatesudo apt installieren Standard-JDK
Überprüfen Sie die aktuelle aktive Java -Version.
Java -Version Ausgabe: OpenJDK -Version "11.0.15 "2022-04-19 OpenJDK Runtime Environment (Build 11.0.15+10-UBUNTU-0UBUNTU0.22.04.1) OpenJDK 64-Bit Server VM (Build 11.0.15+10-UBUNTU-0UBUNTU0.22.04.1, gemischter Modus, Freigabe)
Schritt 2 - Laden Sie die neueste Apache Kafka herunter
Sie können die neuesten Apache Kafka -Binärdateien von der offiziellen Download -Seite herunterladen. Alternativaly Sie können Kafka 3 herunterladen.2.0 mit dem folgenden Befehl.
WGet https: // dlcdn.Apache.org/kafka/3.2.0/kafka_2.13-3.2.0.TGZ Extrahieren Sie dann die heruntergeladene Archivdatei und platzieren Sie sie unter /usr/local/kafka Verzeichnis.
TAR XZF KAFKA_2.13-3.2.0.TGZsudo mv kafka_2.13-3.2.0/usr/local/kafka
Schritt 3 - Erstellen Sie Systemd -Start -Skripte
Erstellen Sie nun Systemd -Einheitendateien für die Dienste Zookeeper und Kafka. Dies hilft Ihnen, den Kafka -Service auf einfache Weise zu starten/zu stoppen.
Erstellen Sie zunächst eine Systemd -Einheitsdatei für Zookeeper:
sudo nano/etc/systemd/system/zookeeper.Service Und fügen Sie den folgenden Inhalt hinzu:
[Einheit] Beschreibung = Apache Zookeeper Server -Dokumentation = http: // zookeeper.Apache.org erfordert = Netzwerk.Ziel-Remote-FS.Ziel nach = Netzwerk.Ziel-Remote-FS.Ziel [Service] type = einfacher execstart =/usr/local/kafka/bin/zookeeper-server-start.sh/usr/local/kafka/config/zookeeper.Eigenschaften execStop =/usr/local/kafka/bin/zookeeper-server-stop.sh restart = on-abnormal [install] suchtby = multi-user.Ziel
Speichern Sie die Datei und schließen Sie sie.
Erstellen Sie als Nächstes eine Systemd -Einheitsdatei für den Kafka -Dienst:
sudo nano/etc/systemd/system/kafka.Service Fügen Sie den folgenden Inhalt hinzu. Stellen Sie sicher, dass Sie den richtigen Stellen einstellen Java_Home Pfad gemäß den auf Ihrem System installierten Java.
[Einheit] Beschreibung = Apache Kafka Server -Dokumentation = http: // kafka.Apache.Org/Dokumentation.HTML erfordert = Zookeeper.Service [Service] type = einfache Umgebung = "java_home =/usr/lib/jvm/java-11-openjdk-amd64" execstart =/usr/local/kafka/bin/kafka-server-start.sh/usr/local/kafka/config/server.Eigenschaften execStop =/usr/local/kafka/bin/kafka-server-stop.sh [install] wantby by = multi-user.Ziel
Speichern Sie die Datei und schließen Sie.
Laden Sie den Systemd -Daemon neu, um neue Änderungen anzuwenden.
sudo systemctl dämon-reload Dadurch werden alle Systemd -Dateien in der Systemumgebung neu geladen.
Schritt 4 - Starten Sie Zookeeper- und Kafka -Dienste
Beginnen wir beide Dienste nacheinander. Zuerst müssen Sie den Zookeeper -Service starten und dann Kafka starten. Verwenden Sie den Befehl systemCTL, um eine Zookeeper-Instanz einzelner Knoten zu starten.
sudo systemctl starten zookeepersudo systemctl starten kafka
Überprüfen Sie den beiden Dienstleistungsstatus:
sudo systemctl Status Zookeepersudo systemctl Status kafka
Das ist es. Sie haben den Apache Kafka -Server auf Ubuntu 22 erfolgreich installiert.04 System. Als nächstes erstellen wir Themen auf dem Kafka -Server.
Schritt 5 - Erstellen Sie ein Thema in Kafka
Kafka bietet mehrere vorgefertigte Shell-Skript, um daran zu arbeiten. Erstellen Sie zunächst ein Thema mit dem Namen "Testtopic" mit einer einzelnen Partition mit einer einzigen Replik:
CD/USR/LOCAL/KAFKABin/Kafka-Topics.sh-create-Bootstrap-server localhost: 9092-Replikationsfaktor 1-Partitionen 1--topische Testtope
Ausgabe erstellt Topic Testtopic.
Hier:
- Verwenden
--erstellenOption zum Erstellen eines neuen Themas - Der
--Replikationsfaktorbeschreibt, wie viele Kopien von Daten erstellt werden. Wenn wir mit einer einzigen Instanz laufen, behalten Sie diesen Wert 1. - Setzen Sie die
--PartitionenOptionen als Anzahl der Makler, die Ihre Daten zwischen aufgeteilt werden sollen. Da wir mit einem einzigen Broker laufen, behalten Sie diesen Wert 1. - Der
--ThemaDefinieren Sie den Namen des Themas
Sie können mehrere Themen erstellen, indem Sie denselben Befehl wie oben ausgeführt haben. Danach sehen Sie die erstellten Themen auf Kafka, indem Sie den Befehl unter unten lief:
Bin/Kafka-Topics.SH-List-Bootstrap-server localhost: 9092 Die Ausgabe sieht aus wie der folgende Screenshot:
 Kafka -Themen auflisten
Kafka -Themen auflistenAlternativ können Sie Ihre Makler auch nicht manuell erstellen, um Themen zu konfigurieren, wenn ein nicht existierendes Thema veröffentlicht wird.
Schritt 6 - Senden und empfangen Nachrichten in Kafka
Der „Produzent“ ist der Prozess, der dafür verantwortlich ist, Daten in unsere Kafka zu setzen. Der Kafka wird mit einem Befehlslinienclient geliefert, der Eingaben aus einer Datei oder aus Standardeingaben übernimmt und als Nachrichten an den Kafka-Cluster versendet. Der Standard -Kafka sendet jede Zeile als separate Nachricht.
Lassen Sie uns den Produzenten ausführen und dann ein paar Nachrichten in die Konsole eingeben, um sie an den Server zu senden.
Bin/Kafka-Console-Produzent.SH-BROKER-LIST LOCALHOST: 9092-Topic Testtopic > Willkommen bei Kafka> Dies ist mein erstes Thema> Sie können diesen Befehl beenden oder dieses Terminal für weitere Tests laufen. Eröffnen Sie nun im nächsten Schritt ein neues Terminal für den Kafka -Verbraucherprozess.
Kafka verfügt außerdem über einen Befehlszeilenverbraucher, mit dem Daten aus dem Kafka-Cluster gelesen und Nachrichten auf die Standardausgabe angezeigt werden können.
Bin/Kafka-Console-Consumer.SH-Bootstrap-Server localhost: 9092--topic testtopic-from-beinging Willkommen in Kafka Dies ist mein erstes Thema Wenn Sie jetzt noch Kafka -Produzent in einem anderen Terminal betreiben. Geben Sie einfach einen Text in dieses Erzeugerterminal ein. Es wird sofort am Verbraucherterminal sichtbar sein. Siehe den folgenden Screenshot des Kafka -Produzenten und -verbrauchers in der Arbeit:
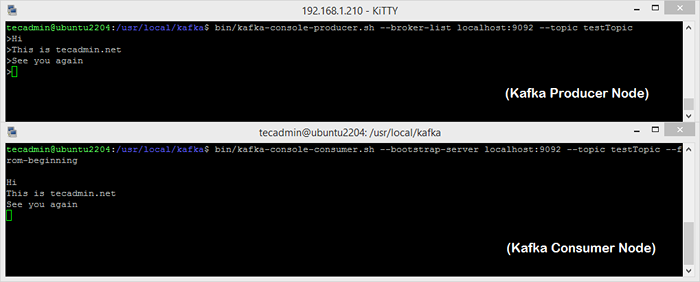 Ausführen von Apache Kafka -Produzent und Verbraucherknoten
Ausführen von Apache Kafka -Produzent und VerbraucherknotenAbschluss
Dieses Tutorial hat Ihnen geholfen, den Apache Kafka -Server auf einem Ubuntu 22 zu installieren und zu konfigurieren.04 Linux -System. Darüber hinaus haben Sie gelernt, ein neues Thema auf dem Kafka -Server zu erstellen und mit Apache Kafka einen Beispielproduktions- und Verbraucherprozess auszuführen.
- « So erstellen Sie einen leeren Zweig in Git (ohne Parrent)
- So ersetzen Sie die Zeichenfolge in JavaScript »