

So installieren Sie Elasticsearch (Multi -Knoten) -Cluster auf CentOS/Rhel, Ubuntu & Debian

- 1042
- 138
- Miriam Bauschke
Elasticsarch ist flexibel und leistungsstarke Open Source, verteilte Echtzeitsuche und analytische Engine. Mit einem einfachen APIs-Satz bietet es die Möglichkeit zur Volltext-Suche. Die elastische Suche ist unter der Apache 2 -Lizenz frei verfügbar, die die größte Flexibilität bietet.
Dieser Artikel hilft Ihnen bei der Konfiguration von Elasticsearch Multi -Knotencluster auf CentOS, Rhel, Ubuntu und Debian Systems. In Elasticsearch konfiguriert Multi -Knoten -Cluster nur mehrere Einzelknotencluster mit demselben Clusternamen im selben Netzwerk.
Netzwerker -Szene
Wir haben drei Server mit folgenden IPs und Hostnamen. Der gesamte Server wird im selben LAN ausgeführt und verfügt über volle Zugriff aufeinander mit IP und Hostname.
192.168.10.101 NODE_1 192.168.10.102 NODE_2 192.168.10.103 NODE_3
Überprüfen Sie Java (alle Knoten)
Java ist die Hauptanforderung für die Installation von Elasticsearch. Stellen Sie also sicher, dass Java auf allen Knoten installiert ist.
# Java -version Java Version "1.8.0_31 "Java (TM) SE -Laufzeitumgebung (Build 1.8.0_31-B13) Java Hotspot (TM) 64-Bit Server VM (Build 25.31-B07, gemischter Modus)
Wenn Java auf keinem Knotensystem installiert ist, verwenden Sie einen der folgenden Link, um es zuerst zu installieren.
Installieren Sie Java 8 auf CentOS/RHEL 7/6/5
Installieren Sie Java 8 auf Ubuntu
Laden Sie ElasticSearch (alle Knoten) herunter
Laden Sie nun das neueste Elasticsearch -Archiv auf allen Knotensystemen von seiner offiziellen Download -Seite herunter. Zum Zeitpunkt des letzten Updates dieses Artikels Elasticsearch 1.4.2 Version ist die neueste Version zum Download zur Verfügung. Verwenden Sie den folgenden Befehl zum Herunterladen von Elasticsearch 1.4.2.
$ wget https: // herunterladen.Elasticsarch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.Teer.gz
Extrahieren Sie nun Elasticsearch auf allen Knotensystemen.
$ tar xzf elasticsearch-1.4.2.Teer.gz
Konfigurieren Sie ElasticSearch
Jetzt müssen wir Elasticsearch auf allen Knotensystemen einrichten. Elasticsearch verwendet "Elasticsearch" als Standard -Cluster -Name. Wir empfehlen, es gemäß Ihrem Namensunterhalt zu ändern.
$ MV Elasticsearch-1.4.2/usr/share/elasticsearch $ cd/usr/share/elasticsearch
Um Cluster mit dem Namen Bearbeiten zu ändern config/elasticsearch.YML Datei in jedem Knoten und aktualisieren Sie die folgenden Werte. Knotennamen werden dynamisch generiert, aber um einen festen benutzerfreundlichen Namen zu behalten, ändern Sie ihn auch.
Auf node_1
Bearbeiten Sie die Clusterkonfiguration der Elasticsearch auf node_1 (192).168.10.101) System.
$ vim config/elasticsearch.YML
Cluster.Name: Tecadmincluster -Knoten.Name: "node_1"
Auf node_2
Bearbeiten Sie die Clusterkonfiguration der Elasticsearch auf node_2 (192.168.10.102) System.
$ vim config/elasticsearch.YML
Cluster.Name: Tecadmincluster -Knoten.Name: "node_2"
Auf node_3
Bearbeiten Sie die Clusterkonfiguration der Elasticsearch auf node_3 (192.168.10.103) System.
$ vim config/elasticsearch.YML
Cluster.Name: Tecadmincluster -Knoten.Name: "node_3"
Installieren Sie das Elasticsearch-Head-Plugin (alle Knoten)
Elasticsearch-Head ist ein Web-Front-End zum Surfen und Interagieren mit einem elastischen Suchcluster. Verwenden Sie den folgenden Befehl, um dieses Plugin auf allen Knotensystemen zu installieren.
$ Bin/Plugin-Installieren Sie Mobz/Elasticsearch-Head
Elasticsearch -Cluster starten (alle Knoten)
Wie das Elasticsearch -Cluster -Setup abgeschlossen wurde. Lassen Sie den Elasticsearch -Cluster mit dem folgenden Befehl auf allen Knoten starten.
$ ./bin/elasticsearch &
Standardmäßig Elasticserch hören Sie auf Port 9200 und 9300 an. Also verbinden Sie Node_1 Auf Port 9200 wie der URL folgen Sie alle drei Knoten in Ihrem Cluster.
http: // node_1: 9200/_plugin/head/
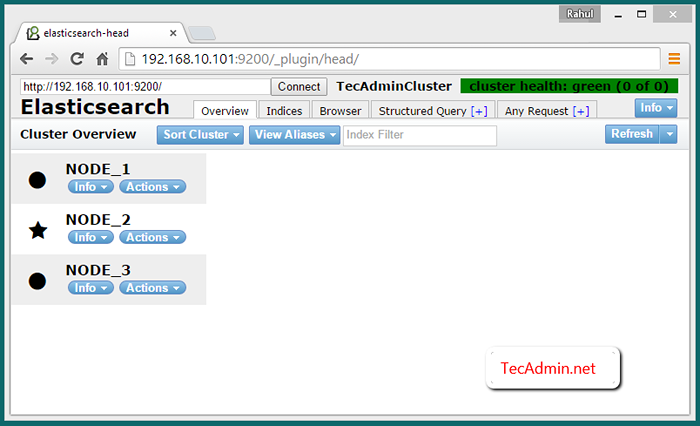
Überprüfen Sie den Multimode -Cluster
Um zu überprüfen, ob Cluster ordnungsgemäß funktioniert. Fügen Sie einige Daten in einen Knoten ein und wenn dieselben Daten in anderen Knoten verfügbar sind, bedeutet dies, dass Cluster ordnungsgemäß funktioniert.
Daten auf node_1 einfügen
So überprüfen Sie, ob Cluster einen Eimer erstellen in Node_1 und einige Daten hinzufügen.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"name": "rahul kumar"'
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '"user": "rahul", "postdate": "01-16-2015", "Body": "Daten hinzufügen In Elasticsearch Cluster "," Titel ":" Elasticsearch -Cluster -Test ""
Suchen Sie nach Daten zu allen Knoten
Suchen Sie nun die gleichen Daten von Node_2 Und Node_3 und prüfen Sie, ob die gleichen Daten an andere Knoten von Cluster repliziert werden. Nach den oben genannten Befehlen haben wir einen Benutzer namens Rahul erstellt und dort einige Daten hinzugefügt. Verwenden Sie daher folgende Befehle, um Daten zu durchsuchen, die mit dem Benutzer RAHUL zugeordnet sind.
$ curl 'http: // node_1: 9200/mybucket/post/_SEARCH?Q = Benutzer: Rahul & Pretty = True '$ curl' http: // node_2: 9200/mybucket/post/_SEARCH?Q = Benutzer: Rahul & Pretty = True '$ curl' http: // node_3: 9200/mybucket/post/_SEARCH?Q = Benutzer: Rahul & Pretty = True '
Und Sie erhalten Ergebnisse für alle obigen Befehle nach unten wie unten.
"Taking": 69, "Timed_out": Falsch, "_shards": "Gesamt": 5, "erfolgreich": 5, "fehlgeschlagen": 0, "Hits": "Total": 1, "max_score" ": 1.0, "Hits": ["_index": "mybucket", "_type": "post", "_id": "1", "_score": 1.0, "_Source": "Benutzer": "Rahul", "Postdate": "01-16-2015", "Body": "Daten in Elasticsearch-Cluster hinzufügen", "Titel": "Elasticsearch-Cluster-Test" ]
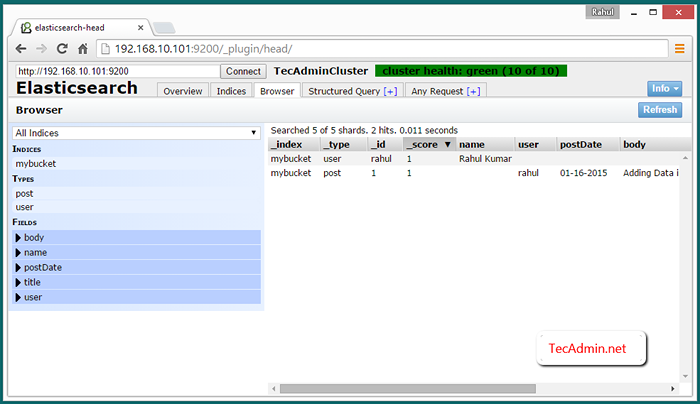
Sehen Sie sich Clusterdaten im Webbrowser an
Um Daten zum Elasticsearch-Cluster-Zugriff des Elasticsearch-Head-Plugins mit einem von Cluster IP unter der URL anzuzeigen. Klicken Sie dann auf Browser Tab.
http: // node_1: 9200/_plugin/head/
- « So verwenden Sie den SystemCTL -Befehl zum Verwalten von Systemd Services
- Hinzufügen von zusätzlichen Repository Epel und Remi auf einem rhelbasierten System »