

So installieren Sie Hadoop auf Ubuntu 18.04 Bionic Beaver Linux
- 1145
- 102
- Tom Jakobs
Apache Hadoop ist ein Open -Source -Framework für verteilte Speicher sowie die verteilte Verarbeitung von Big -Data auf Clustern von Computern, die auf Waren -Hardware ausgeführt werden. Hadoop speichert Daten in Hadoop Distributed Dateisystem (HDFS) und die Verarbeitung dieser Daten erfolgt mithilfe von MapReduce. Garn bietet API für das Anfragen und Zuordnen von Ressourcen im Hadoop -Cluster.
Das Apache Hadoop -Framework besteht aus den folgenden Modulen:
- Hadoop Common
- Hadoop Distributed Dateisystem (HDFS)
- GARN
- Karte verkleinern
In diesem Artikel wird erläutert, wie Hadoop Version 2 auf Ubuntu 18 installiert wird.04. Wir werden HDFs (Namenode und Datanode), Garn, MapReduce im einzelnen Knotencluster im Pseudo -verteilten Modus installieren, der auf einer einzelnen Maschine verteilt ist. Jeder Hadoop -Dämon wie HDFs, Garn, MapReduce usw. wird als separater/individueller Java -Prozess ausgeführt.
In diesem Tutorial lernen Sie:
- So fügen Sie Benutzer für die Hadoop -Umgebung hinzu
- So installieren und konfigurieren Sie den Oracle JDK
- So konfigurieren Sie passwortlos SSH
- So installieren Sie Hadoop und konfigurieren die erforderlichen zugehörigen XML -Dateien
- So starten Sie den Hadoop -Cluster
- So greifen Sie auf Namenode und ResourceManager Web UI zu
NAMENODE -Webbenutzeroberfläche. Softwareanforderungen und Konventionen verwendet
| Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Ubuntu 18.04 |
| Software | Hadoop 2.8.5, Oracle JDK 1.8 |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
Andere Versionen dieses Tutorials
Ubuntu 20.04 (fokale Fossa)
Fügen Sie Benutzer für die Hadoop -Umgebung hinzu
Erstellen Sie den neuen Benutzer und die neue Gruppe mit dem Befehl:
# Benutzer hinzufügen
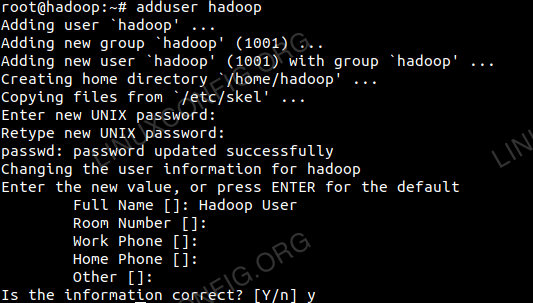 Fügen Sie einen neuen Benutzer für Hadoop hinzu.
Fügen Sie einen neuen Benutzer für Hadoop hinzu.
Installieren und konfigurieren Sie den Oracle JDK
Laden Sie das Java -Archiv unter dem herunter und extrahieren Sie sie /opt Verzeichnis.
# cd /opt # tar -xzvf jdk-8u192-linux-x64.Teer.gz
oder
$ tar -xzvf jdk-8U192-linux-x64.Teer.gz -c /opt
So setzen Sie den JDK 1.8 UPDATE 192 Als Standard -JVM werden wir die folgenden Befehle verwenden:
# Update-Alternative-Installieren/usr/bin/java java/opt/jdk1.8.0_192/bin/java 100 # Update-Alternative--install/usr/bin/javac javac/opt/jdk1.8.0_192/bin/javac 100
Nach der Installation zur Überprüfung der Java wurde erfolgreich konfiguriert, führen Sie die folgenden Befehle aus:
# Update-Alternative-DISPLY JAVA # UPDATE-ALTERNIENSTEN--Display Javac
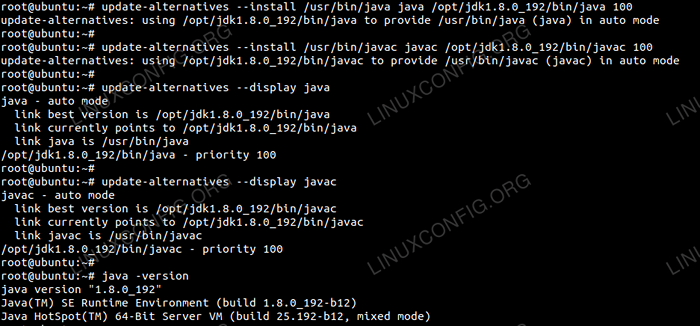 Oraclejdk -Installation und Konfiguration.
Oraclejdk -Installation und Konfiguration. Konfigurieren Sie passwortlos SSH
Installieren Sie den Open SSH -Server und öffnen Sie den SSH -Client mit dem Befehl:
# sudo apt-get install OpenSSH-Server OpenSSH-Client
Generieren Sie öffentliche und private Schlüsselpaare mit dem folgenden Befehl. Das Terminal fordert die Eingabe des Dateinamens auf. Drücken Sie EINGEBEN und fortfahren. Danach kopieren Sie das Formular der öffentlichen Schlüssel id_rsa.Pub Zu Autorisierte_Keys.
$ ssh -keygen -t RSA $ cat ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keys
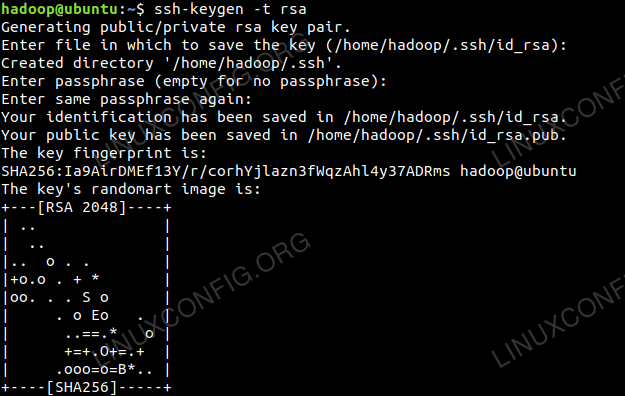 Passwortlose SSH -Konfiguration.
Passwortlose SSH -Konfiguration.
Überprüfen Sie die SSH-Konfiguration ohne Passwort mit dem Befehl:
$ ssh localhost
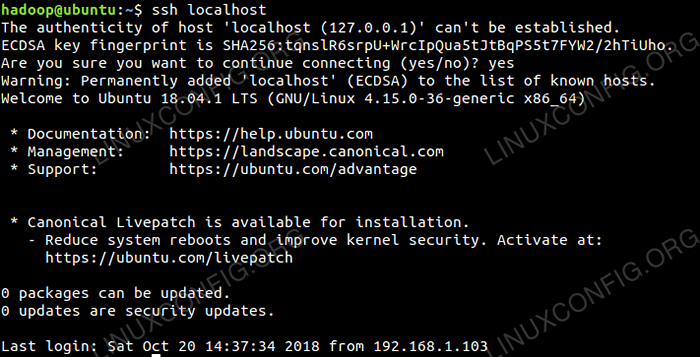 Passwortloses SSH -Check.
Passwortloses SSH -Check.
Installieren Sie Hadoop und konfigurieren verwandte XML -Dateien
Download und extrahieren Hadoop 2.8.5 von der offiziellen Website von Apache.
# tar -xzvf hadoop -2.8.5.Teer.gz
Einrichten der Umgebungsvariablen
Bearbeiten die bashrc Für den Hadoop -Benutzer durch Einrichten der folgenden Hadoop -Umgebungsvariablen:
Export hadoop_home =/home/hadoop/hadoop-2.8.5 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin Exportieren Sie Hadoop_opts = "-Djava.Bibliothek.path = $ hadoop_home/lib/native " Quellen Sie die .bashrc In der aktuellen Anmeldesitzung.
$ source ~/.bashrc
Bearbeiten die Hadoop-Env.Sch Datei, die sich befindet /etc/hadoop Im Verzeichnis des Hadoop -Installationsverzeichnisses und die folgenden Änderungen vornehmen und prüfen, ob Sie andere Konfigurationen ändern möchten.
Exportieren Sie java_home =/opt/jdk1.8.0_192 Export hadoop_conf_dir = $ hadoop_conf_dir:-"/home/hadoop/hadoop-2.8.5/etc/hadoop " 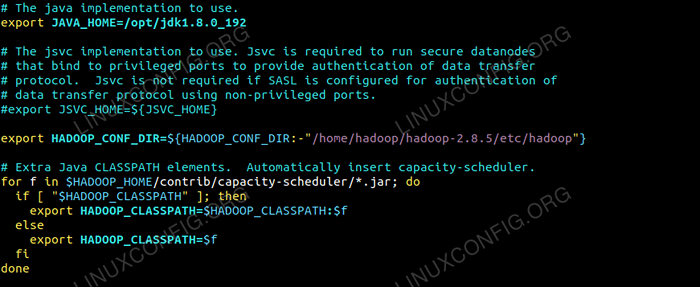 Änderungen in Hadoop-Env.SH -Datei.
Änderungen in Hadoop-Env.SH -Datei. Konfigurationsänderungen in der Kernseite.XML -Datei
Bearbeiten die Kernstelle.xml mit Vim oder Sie können einen der Redakteure verwenden. Die Datei ist unter /etc/hadoop innen Hadoop Home -Verzeichnis und fügen Sie die folgenden Einträge hinzu.
fs.Standard HDFS: // localhost: 9000 Hadoop.TMP.Dir /home/hadoop/hadooptmpdata Erstellen Sie außerdem das Verzeichnis unter Hadoop Home-Ordner.
$ mkdir hadooptmpdata
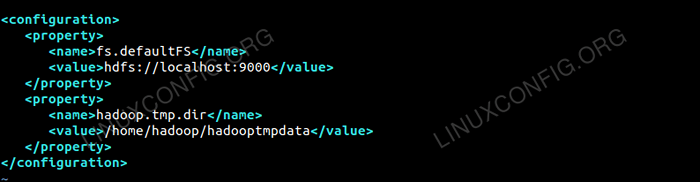 Konfiguration für die Kernseite.XML -Datei.
Konfiguration für die Kernseite.XML -Datei. Konfigurationsänderungen in der HDFS-Site.XML -Datei
Bearbeiten die HDFS-Site.xml die unter demselben Ort vorhanden ist.e /etc/hadoop innen Hadoop Installationsverzeichnis und erstellen Sie das Namenode/Datanode Verzeichnisse unter Hadoop User Home Directory.
$ MKDIR -P HDFS/NAMENODE $ MKDIR -P HDFS/DATANODE
DFS.Reproduzieren 1 DFS.Name.Dir Datei: /// home/hadoop/hdfs/namenode DFS.Daten.Dir Datei: /// home/hadoop/hdfs/datanode 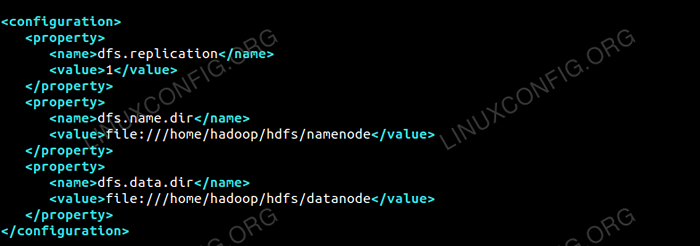 Konfiguration für HDFS-Site.XML -Datei.
Konfiguration für HDFS-Site.XML -Datei. Konfigurationsänderungen in Mapred-Site.XML -Datei
Kopiere das Mapred-Site.xml aus Mapred-Site.xml.Vorlage Verwendung CP Befehl und dann die bearbeiten Mapred-Site.xml platziert in /etc/hadoop unter Hadoop Das Instillationsverzeichnis mit den folgenden Änderungen.
$ cp Mapred-Site.xml.Vorlage Mapred-Site.xml
 Erstellen der neuen Mapred-Site.XML -Datei.
Erstellen der neuen Mapred-Site.XML -Datei. Karte verkleinern.Rahmen.Name Garn  Konfiguration für Mapred-Site.XML -Datei.
Konfiguration für Mapred-Site.XML -Datei. Konfigurationsänderungen in der Garnstelle.XML -Datei
Bearbeiten Garnstelle.xml mit den folgenden Einträgen.
MAPREDUCEYARN.NodeManager.Aux-Services MAPREDUCE_SHUFFE  Konfiguration für Garnstelle.XML -Datei.
Konfiguration für Garnstelle.XML -Datei. Starten Sie den Hadoop -Cluster
Formatieren Sie den Namenode, bevor Sie ihn zum ersten Mal verwenden. Als HDFS -Benutzer führen Sie den folgenden Befehl aus, um den Namenode zu formatieren.
$ hdfs namenode -format
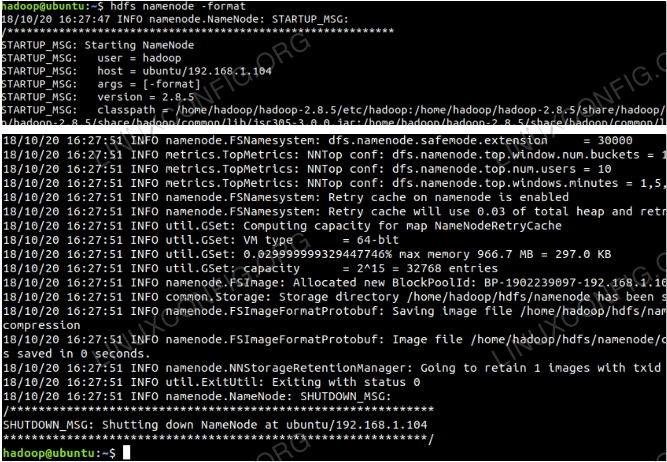 Formatieren Sie den Namenode.
Formatieren Sie den Namenode.
Sobald der Namenode formatiert wurde, starten Sie die HDFs mit dem Start-dfs.Sch Skript.
 Starten Sie das DFS -Startskript, um HDFS zu starten.
Starten Sie das DFS -Startskript, um HDFS zu starten.
Um die Garndienste zu starten, müssen Sie das Garn -Startskript i ausführen.e. Start marnt.Sch
 Starten Sie das Garnstartskript, um Garn zu starten.
Starten Sie das Garnstartskript, um Garn zu starten. Um alle Hadoop -Dienste/Dämonen erfolgreich zu überprüfen, können Sie die verwenden JPS Befehl.
/opt/jdk1.8.0_192/bin/jps 20035 SecondaryNamenode 19782 Datanode 21671 JPS 20343 NODEMANATER 19625 NAMENODE 20187 RESECORDEMANAGER  Hadoop -Dämonen Ausgabe aus dem JPS -Befehl.
Hadoop -Dämonen Ausgabe aus dem JPS -Befehl.
Jetzt können wir die aktuelle Hadoop -Version überprüfen, die Sie unten verwenden können:
$ hadoop Version
oder
$ HDFS -Version
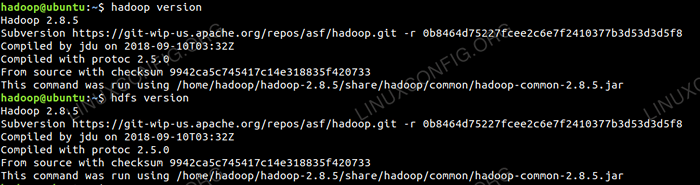 Überprüfen Sie die Hadoop -Version.
Überprüfen Sie die Hadoop -Version.
HDFS -Befehlszeilenschnittstelle
Um auf die HDFs zuzugreifen und einige Verzeichnisse auf dem DFS zu erstellen, können Sie HDFS CLI verwenden.
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
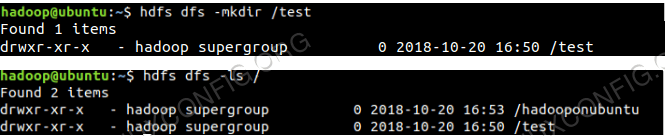 HDFS -Verzeichniserstellung mit HDFS CLI.
HDFS -Verzeichniserstellung mit HDFS CLI.
Greifen Sie vom Browser auf den Namenode und Garn zuzugreifen
Sie können über einen der Browser wie Google Chrome/Mozilla Firefox auf die Web -Benutzeroberfläche für Namenode- und Garnressourcenmanager zugreifen.
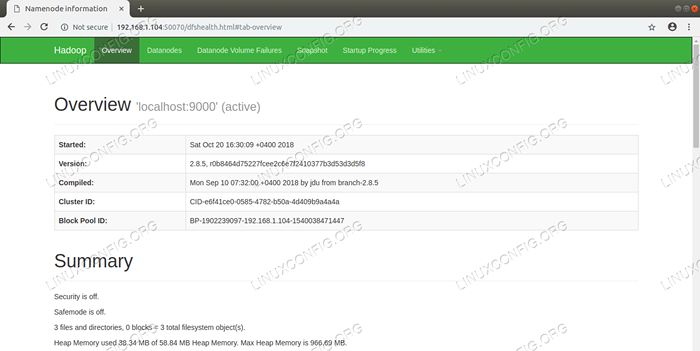
Namenode Web UI - http: //: 50070
NAMENODE -Webbenutzeroberfläche. 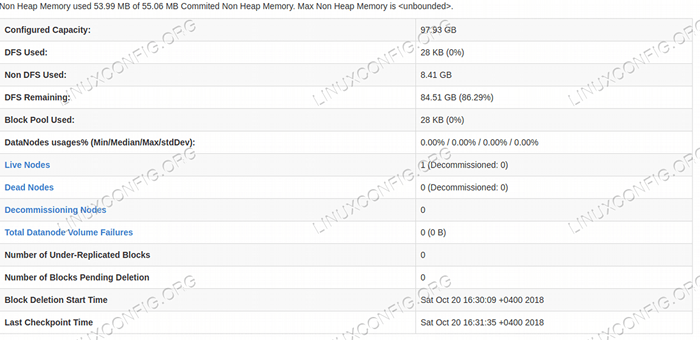 HDFS -Details von der NAMENODE -Webbenutzeroberfläche.
HDFS -Details von der NAMENODE -Webbenutzeroberfläche. 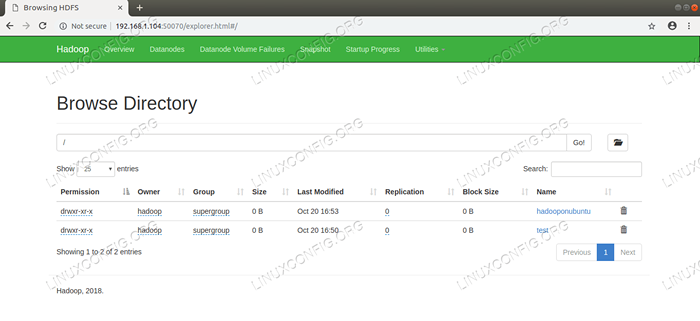 HDFS -Verzeichnis durch die NAMENODE -Webbenutzeroberfläche durchsucht.
HDFS -Verzeichnis durch die NAMENODE -Webbenutzeroberfläche durchsucht. Die Weboberfläche des Yarn Resource Managers (RM) zeigt alle laufenden Jobs auf dem aktuellen Hadoop -Cluster an.
Ressourcenmanager Web -Benutzeroberfläche - http: //: 8088
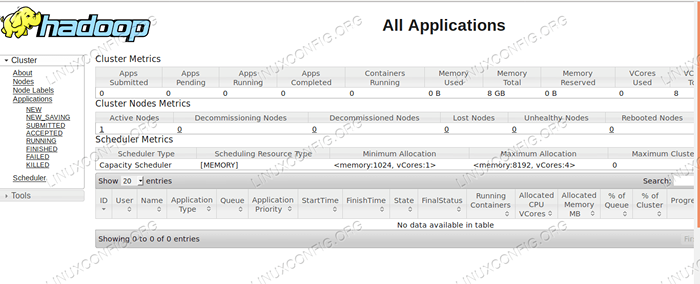 Ressourcenmanager -Webbenutzeroberfläche.
Ressourcenmanager -Webbenutzeroberfläche. Abschluss
Die Welt verändert die Art und Weise, wie sie derzeit funktioniert, und Big-Data spielt in dieser Phase eine wichtige Rolle. Hadoop ist ein Framework, das unser Leben erleichtert, während wir an großen Datensätzen arbeiten. Es gibt Verbesserungen an allen Fronten. Die Zukunft ist aufregend.
Verwandte Linux -Tutorials:
- Ubuntu 20.04 Hadoop
- Dinge zu installieren auf Ubuntu 20.04
- So erstellen Sie einen Kubernetes -Cluster
- So installieren Sie Kubernetes auf Ubuntu 20.04 fokale Fossa Linux
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- So installieren Sie Kubernetes auf Ubuntu 22.04 Jammy Quallen…
- Dinge zu installieren auf Ubuntu 22.04
- Wie man mit der Woocommerce -REST -API mit Python arbeitet
- So verwalten Sie Kubernetes -Cluster mit Kubectl
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- « So installieren Sie Android Studio unter Manjaro 18 Linux
- So installieren Sie Google Chrome unter Manjaro 18 Linux »