

So installieren Sie Hadoop -Single -Knoten -Cluster (Pseudonode) auf CentOS 7

- 4775
- 1165
- Henry Liebold
Hadoop ist ein Open-Source-Framework, das häufig verwendet wird, um damit umzugehen Große Daten. Die meisten von den BigData/Data Analytics Projekte werden über dem aufgebaut Hadoop-Ökosystem. Es besteht aus zweischichtiger Daten speichern und ein anderer ist für Daten verarbeiten.
Lagerung wird durch ein eigenes Dateisystem genannt HDFS (Hadoop verteilte Dateisystem) Und wird bearbeitet wird durch GARN (Ein weiterer Ressourcenverhandler). Karte verkleinern ist die Standardverarbeitungsmotor der Hadoop-Ökosystem.
Dieser Artikel beschreibt den Vorgang zur Installation der Pseudonode Installation von Hadoop, wo alles Daemons (JVMS) wird laufen Einzelknoten Cluster auf Centos 7.
Dies ist hauptsächlich für Anfänger, um Hadoop zu lernen. In Echtzeit, Hadoop wird als Multinode -Cluster installiert, in dem die Daten auf die Server als Blöcke verteilt werden und der Job parallel ausgeführt wird.
Voraussetzungen
- Eine minimale Installation des CentOS 7 -Servers.
- Java v1.8 Release.
- Hadoop 2.x stabile Veröffentlichung.
Auf dieser Seite
- So installieren Sie Java auf CentOS 7
- Richten Sie eine passwortlose Login auf CentOS 7 ein
- So installieren Sie den Hadoop -Single -Knoten in CentOS 7
- So konfigurieren Sie Hadoop in CentOS 7
- Formatieren des HDFS -Dateisystems über den Namenode
Installation von Java auf CentOS 7
1. Hadoop ist ein Ökosystem, aus dem besteht Java. Wir brauchen Java installiert in unserem System maßgeblich zur Installation Hadoop.
# Yum Java-1 installieren.8.0-openjdk
2. Überprüfen Sie als nächstes die installierte Version von Java auf dem System.
# Java -Version
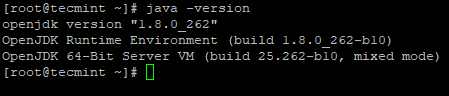 Überprüfen Sie die Java-Version
Überprüfen Sie die Java-Version Konfigurieren Sie passwortlose Login auf CentOS 7
Wir müssen SSH in unserer Maschine konfigurieren lassen, Hadoop verwaltet Knoten mit Verwendung von Ssh. Master -Knoten verwendet Ssh Verbindung, um die Sklavenknoten zu verbinden und den Betrieb wie Start und Stopp durchzuführen.
Wir müssen SSH ohne Passwort einrichten, damit der Master mit SSH mit SSH ohne Passwort mit Sklaven kommunizieren kann. Andernfalls müssen für jede Verbindungseinrichtung das Passwort eingeben.
In diesem einzelnen Knoten, Meister Dienstleistungen (Namenode, Sekundärer Namenode & Ressourcenmanager) Und Sklave Dienstleistungen (Datanode & NodeManager) wird als getrennt laufen JVMS. Obwohl es sich Meister kommunizieren Sklave ohne Authentifizierung.
3. Richten Sie eine SSH-Anmeldung ohne Passwort mit den folgenden Befehlen auf dem Server ein.
# ssh-keygen # ssh-copy-id -i localhost
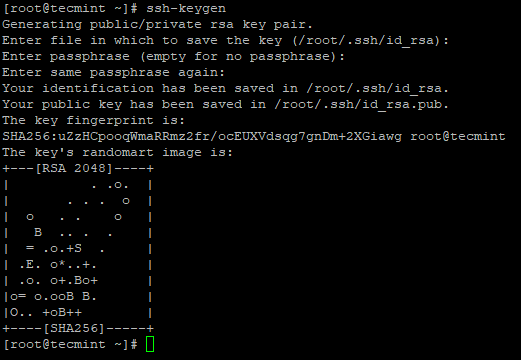 Erstellen Sie SSH Keygen in CentOS 7
Erstellen Sie SSH Keygen in CentOS 7 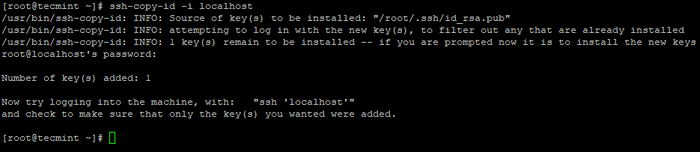 Kopieren Sie den SSH -Schlüssel zu CentOS 7
Kopieren Sie den SSH -Schlüssel zu CentOS 7 4. Nachdem Sie eine passwortlose SSH -Anmeldung konfiguriert haben, versuchen Sie sich erneut, ohne Kennwort verbunden zu sein.
# SSH LOCALHOST
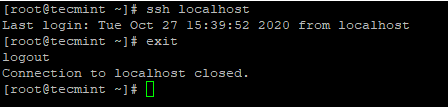 Ssh passwortlos Anmeldung bei CentOS 7
Ssh passwortlos Anmeldung bei CentOS 7 Installation von Hadoop in CentOS 7
5. Gehen Sie zur Apache Hadoop -Website und laden Sie die stabile Version von Hadoop mit dem folgenden WGet -Befehl herunter.
# WGet https: // Archiv.Apache.org/dist/hadoop/core/hadoop-2.10.1/Hadoop-2.10.1.Teer.GZ # TAR XVPZF Hadoop-2.10.1.Teer.gz
6. Als nächstes fügen Sie die hinzu Hadoop Umgebungsvariablen in ~/.bashrc Datei wie gezeigt.
Hadoop_prefix =/root/hadoop-2.10.1 path = $ path: $ hadoop_prefix/bin exportpfad java_home hadoop_prefix
7. Nach dem Hinzufügen von Umgebungsvariablen zu ~/.bashrc Die Datei, beziehen Sie die Datei und überprüfen Sie die Hadoop, indem Sie die folgenden Befehle ausführen.
# Quelle ~//.Bashrc # CD $ Hadoop_Prefix # bin/hadoop Version
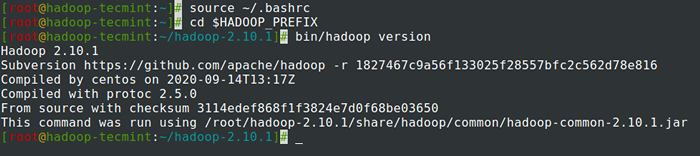 Überprüfen Sie die Hadoop -Version in CentOS 7
Überprüfen Sie die Hadoop -Version in CentOS 7 Hadoop in CentOS 7 konfigurieren
Wir müssen die folgenden Hadoop -Konfigurationsdateien konfigurieren, um in Ihren Computer zu passen. In Hadoop, Jeder Dienst verfügt über eine eigene Portnummer und ein eigenes Verzeichnis, um die Daten zu speichern.
- Hadoop -Konfigurationsdateien - Core -Site.XML, HDFS-Site.XML, Mapred-Site.XML & Garnstelle.xml
8. Zuerst müssen wir aktualisieren Java_Home Und Hadoop Weg in der Hadoop-Env.Sch Datei wie gezeigt.
# CD $ hadoop_prefix/etc/hadoop # vi hadoop-env.Sch
Geben Sie die folgende Zeile zu Beginn der Datei ein.
Exportieren Sie java_home =/usr/lib/jvm/java-1.8.0/jre export hadoop_prefix =/root/hadoop-2.10.1
9. Als nächstes ändern Sie die Kernstelle.xml Datei.
# CD $ Hadoop_prefix/etc/hadoop # vi Core-Site.xml
Einfügen folgen zwischen Tags wie gezeigt.
fs.defaultFS HDFS: // localhost: 9000
10. Erstellen Sie die folgenden Verzeichnisse unter Tecmint User Home Directory, das für verwendet wird Nn Und Dn Lagerung.
# Mkdir -p/home/tecmint/hdata/ # mkdir -p/home/tecmint/hdata/data # mkdir -p/home/tecmint/hdata/name
10. Als nächstes ändern Sie die HDFS-Site.xml Datei.
# CD $ Hadoop_prefix/etc/hadoop # vi HDFS-Site.xml
Einfügen folgen zwischen Tags wie gezeigt.
DFS.Replikation 1 DFS.Namenode.Name.Dir/Home/Tecmint/Hdata/Name DFS .Datanode.Daten.Dir Home/Tecmint/Hdata/Daten
11. Ändern Sie erneut die Mapred-Site.xml Datei.
# CD $ Hadoop_prefix/etc/hadoop # cp Mapred-Site.xml.Vorlage Mapred-Site.XML # VI Mapred-Site.xml
Einfügen folgen zwischen Tags wie gezeigt.
Karte verkleinern.Rahmen.Nennen Sie Garn
12. Schließlich ändern Sie die Garnstelle.xml Datei.
# CD $ Hadoop_prefix/etc/hadoop # vi Garn-Site.xml
Einfügen folgen zwischen Tags wie gezeigt.
Garn.NodeManager.AUX-Service MapReduce_Shuffle
Formatieren des HDFS -Dateisystems über den Namenode
13. Vor Beginn der Cluster, Wir müssen das formatieren Hadoop nn in unserem lokalen System, wo es installiert wurde. Normalerweise erfolgt es in der Anfangsphase, bevor der Cluster zum ersten Mal beginnt.
Formatieren der Nn wird Datenverlust in NN Metastore verursachen, daher müssen wir vorsichtiger sein, wir sollten uns nicht formatieren Nn Während der Cluster läuft, es sei denn, er ist absichtlich erforderlich.
# CD $ Hadoop_Prefix # bin/hadoop namenode -format
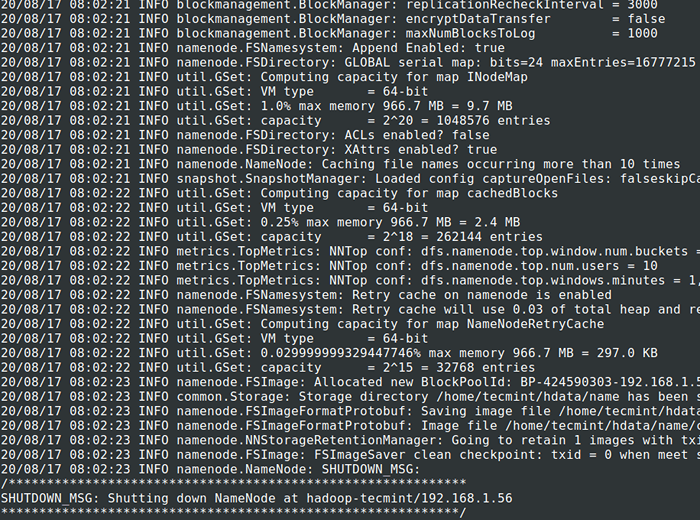 Format HDFS -Dateisystem
Format HDFS -Dateisystem 14. Start Namenode Dämon und Datanode Daemon: (Port 50070).
# CD $ Hadoop_Prefix # SBIN/START-DFS.Sch
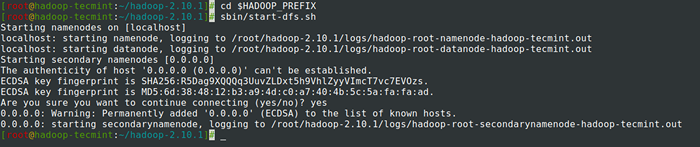 Starten Sie Namenode und Datanode Daemon
Starten Sie Namenode und Datanode Daemon 15. Start Ressourcenmanager Dämon und NodeManager Daemon: (Port 8088).
# SBIN/START-MARARN.Sch
 Starten Sie Resourcemanager und NodeManager Daemon
Starten Sie Resourcemanager und NodeManager Daemon 16. Alle Dienste zu stoppen.
# SBIN/STOP-DFS.SH # SBIN/STOP-DFS.Sch
Zusammenfassung
Zusammenfassung
In diesem Artikel haben wir den Schritt -für -Schritt -Prozess zur Einrichtung durchlaufen Hadoop Pseudonode (Einzelknoten) Cluster. Wenn Sie grundlegende Kenntnisse über Linux haben und diese Schritte ausführen, ist der Cluster in 40 Minuten gestiegen.
Dies kann für Anfänger sehr nützlich sein, um zu lernen und zu üben Hadoop oder diese Vanilleversion von Hadoop kann für Entwicklungszwecke verwendet werden. Wenn wir einen Echtzeit-Cluster haben möchten, benötigen wir entweder mindestens 3 physische Server in der Hand oder müssen Cloud für mehrere Server bereitstellen.
- « Einrichten von Hadoop -Voraussetzungen und Sicherheitshärten - Teil 2
- Was ist MongoDB? Wie funktioniert MongoDB?? »