

So installieren Sie Kafka auf RHEL 8
- 3458
- 786
- Phoebe Jeorga
Apache Kafka ist eine verteilte Streaming -Plattform. Mit seiner Rich -API (Application Programing Interface) -Set können wir meistens alles mit Datenquelle anschließen und am anderen Ende eine große Anzahl von Verbrauchern einrichten, die den Dampf von Datensätzen für die Verarbeitung erhalten. Kafka ist sehr skalierbar und speichert die Datenströme auf zuverlässige und fehlertolerante Weise. Aus der Sicht der Konnektivität kann Kafka als Brücke zwischen vielen heterogenen Systemen dienen, was wiederum auf den Funktionen zur Übertragung und Bestätigung der bereitgestellten Daten beruhen kann.
In diesem Tutorial installieren wir Apache Kafka auf einem Red Hat Enterprise Linux 8, erstellen die systemd Einheitsdateien zur einfachen Verwaltung und testen Sie die Funktionalität mit den versendeten Befehlszeilen -Tools.
In diesem Tutorial lernen Sie:
- So installieren Sie Apache Kafka
- So erstellen Sie Systemd Services für Kafka und Zookeeper
- So testen Sie Kafka mit Befehlszeilenclients
Verbrauch von Nachrichten zu Kafka -Thema aus der Befehlszeile. Softwareanforderungen und Konventionen verwendet
| Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Red Hat Enterprise Linux 8 |
| Software | Apache Kafka 2.11 |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
So installieren Sie Kafka auf Redhat 8 Schritt für Schritt Anweisungen
Apache Kafka ist in Java geschrieben, sodass wir nur OpenJDK 8 installiert haben, um mit der Installation fortzufahren. Kafka verlässt sich auf Apache Zookeeper, einen verteilten Koordinierungsdienst, der auch in Java geschrieben ist und mit dem Paket geliefert wird, das wir herunterladen werden. Während die Installation von HA -Diensten (hohe Verfügbarkeit) an einem einzigen Knoten ihren Zweck tötet, werden wir Zookeeper für Kafkas Sake installieren und ausführen.
- Um Kafka vom nächsten Spiegel herunterzuladen, müssen wir die offizielle Download -Site konsultieren. Wir können die URL des
.Teer.gzDatei von dort. Wir werden verwendenwget, und die URL, die zum Herunterladen des Pakets auf die Zielmaschine geklebt wurde:# WGet https: // www-euu.Apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz -o /opt /kafka_2.11-2.1.0.TGZ
- Wir betreten die
/optVerzeichnis und extrahieren Sie das Archiv:# cd /opt # tar -xvf kafka_2.11-2.1.0.TGZ
Und erstellen Sie einen Symlink aufgerufen
/opt/kafkadas zeigt auf die jetzt erstellten/opt/kafka_2_11-2.1.0Verzeichnis, um unser Leben leichter zu machen.ln -S /opt /kafka_2.11-2.1.0 /opt /kafka
- Wir erstellen einen nicht privilegierten Benutzer, der beide ausgeführt wird
ZookeeperUndKafkaService.# UserAdd Kafka
- Und setzen Sie den neuen Benutzer als Eigentümer des gesamten Verzeichnisses, das wir extrahiert haben, rekursiv:
# Chown -r Kafka: Kafka /opt /kafka*
- Wir erstellen die Einheitsdatei
/etc/systemd/system/zookeeper.Servicemit dem folgenden Inhalt:
Kopieren[Einheit] Beschreibung = Zookeeper nach = syslog.Zielnetzwerk.Ziel [Service] type = einfacher user = kafka Group = kafka execstart =/opt/kafka/bin/zookeeper-server-start.sh/opt/kafka/config/zookeeper.Eigenschaften execStop =/opt/kafka/bin/zookeeper-server-stop.sh [install] wantby by = multi-user.ZielBeachten Sie, dass wir die Versionsnummer aufgrund des von uns erstellten Symlinks nicht dreimal schreiben müssen. Gleiches gilt für die nächste Einheitsdatei für Kafka,
/etc/systemd/system/kafka.Service, Das enthält die folgenden Konfigurationszeilen:
Kopieren[Einheit] Beschreibung = Apache Kafka erfordert = Zookeeper.Service nach = Zookeeper.Service [Service] type = Simple User = Kafka Group = Kafka execstart =/opt/kafka/bin/kafka-server-start.sh/opt/kafka/config/server.Eigenschaften execStop =/opt/kafka/bin/kafka-server-stop.sh [install] wantby by = multi-user.Ziel - Wir müssen nachladen
systemdUm es zu erhalten, lesen Sie die neuen Einheitsdateien:
# Systemctl Daemon-Reload
- Jetzt können wir unsere neuen Dienste beginnen (in dieser Reihenfolge):
# Systemctl Start Zookeeper # SystemCTL Start Kafka
Wenn alles gut geht,
systemdSollte sich über den Status beider Dienstleistungen ausführen, ähnlich wie die folgenden Ausgänge:# Systemctl Status Zookeeper.Service Zookeeper.Service - Zookeeper geladen: geladen (/etc/systemd/system/zookeeper.Service; Behinderte; Anbieter Voreinstellung: Behindert) aktiv: aktiv (laufend) seit dem Jahr 2019-01-10 20:44:37 CET; Vor 6s Hauptpid: 11628 (Java) Aufgaben: 23 (Grenze: 12544) Speicher: 57.0M CGROUP: /SYSTEM.Slice/Zookeeper.Service 11628 Java -xmx512m -xms512m -server […] # Systemctl Status Kafka.Service Kafka.Service - Apache Kafka geladen: geladen (/etc/systemd/system/kafka.Service; Behinderte; Anbieter Voreinstellung: Behindert) aktiv: aktiv (laufend) seit dem Jahr 2019-01-10 20:45:11 CET; Vor 11s Hauptpid: 11949 (Java) Aufgaben: 64 (Grenze: 12544) Speicher: 322.2m Cgroup: /System.Slice/Kafka.Service 11949 Java -xmx1g -xms1g -server […]
- Optional können wir den automatischen Start für beide Dienste aktivieren:
# SystemCTL Aktivieren Sie Zookeeper.Service # SystemCTL Aktivieren Sie Kafka.Service
- Um die Funktionalität zu testen, werden wir mit einem Produzenten und einem Verbraucher -Kunden eine Verbindung zu Kafka herstellen. Die vom Hersteller bereitgestellten Nachrichten sollten auf der Konsole des Verbrauchers erscheinen. Aber vorher brauchen wir ein Medium, diese beiden Austauschnachrichten auf. Wir erstellen einen neuen Datenkanal mit dem Namen
ThemaIn Kafkas Bedingungen, bei denen der Anbieter veröffentlichen wird und wo der Verbraucher abonniert wird. Wir werden das Thema anrufenFirstkafkatopic. Wir werden die verwendenKafkaBenutzer, um das Thema zu erstellen:$/opt/kafka/bin/kafka-topics.sh-create-Zookeeper localhost: 2181-Replikationsfaktor 1-Partitionen 1--Topic Firstkafkatopic
- Wir starten einen Verbraucher -Client aus der Befehlszeile, die das (zu diesem Zeitpunkt leere) Thema abonniert, das im vorherigen Schritt erstellt wurde:
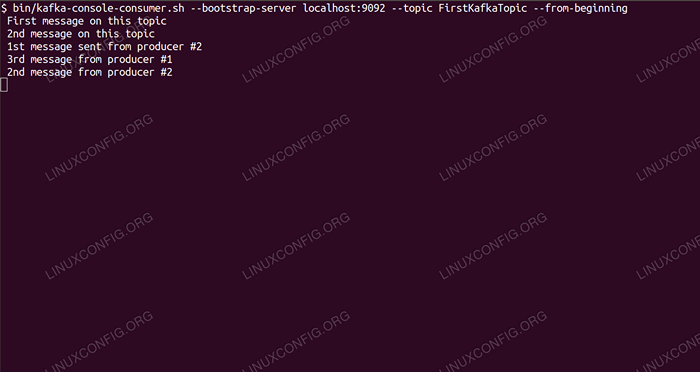
$/opt/kafka/bin/kafka-console-Console-Konsumer.SH-Bootstrap-Server localhost: 9092 --Thema Firstkafkatopic --von Anfang an
Wir lassen die Konsole und der Kunde im sie offen laufen. In dieser Konsole erhalten wir die Nachricht, die wir mit dem Produzenten -Kunden veröffentlichen.
- In einem anderen Terminal starten wir einen Produzenten -Client und veröffentlichen einige Nachrichten an dem von uns erstellten Thema. Wir können Kafka nach verfügbaren Themen abfragen:
$/opt/kafka/bin/kafka-topics.SH -List -Zookeeper Lokalhost: 2181 Firstkafkatopic
Und stellen Sie eine Verbindung zu dem, den der Verbraucher abonniert hat, und senden Sie dann eine Nachricht:
$/opt/kafka/bin/kafka-console-produzierter.SH-BROKER-LIST LOCALHOST: 9092--Topic Firstkafkatopic> Neue Nachricht, die vom Produzenten aus der Konsole #2 veröffentlicht wurde
Am Verbraucherterminal sollte die Nachricht in Kürze angezeigt werden:
$/opt/kafka/bin/kafka-console-Console-Konsumer.SH-Bootstrap-Server localhost: 9092--topic firstkafkatopic-From-Beinging Neue Nachricht, die vom Produzenten aus der Konsole #2 veröffentlicht wurde
Wenn die Nachricht angezeigt wird, ist unser Test erfolgreich und unsere Kafka -Installation funktioniert wie beabsichtigt. Viele Kunden könnten ein oder mehrere Themenaufzeichnungen auf die gleiche Weise bereitstellen und konsumieren, selbst mit einem einzigen Knoten -Setup, das wir in diesem Tutorial erstellt haben.
Verwandte Linux -Tutorials:
- So verwenden Sie überbrückte Netzwerke mit Libvirt und KVM
- Dinge zu installieren auf Ubuntu 20.04
- So verhindern Sie die Überprüfung der Konnektivitätskonnektivität von NetworkManager
- So installieren Sie Dampf auf Ubuntu 22.04 Jammy Jellyfish Linux
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- So verwenden Sie ADB Android Debugg Bridge, um Ihr Android zu verwalten…
- Mastering -Bash -Skriptschleifen beherrschen
- Verschachtelte Schleifen in Bash -Skripten
- Ubuntu 20.04 WordPress mit Apache -Installation
- Wie man mit der Woocommerce -REST -API mit Python arbeitet