

So installieren Sie Spark auf RHEL 8
- 3225
- 596
- Lana Saumweber
Apache Spark ist ein verteiltes Computersystem. Es besteht aus einem Meister und einer oder mehreren Sklaven, bei denen der Meister die Arbeit unter den Sklaven verteilt und so die Möglichkeit gibt, unsere vielen Computer zu verwenden, um an einer Aufgabe zu arbeiten. Man könnte vermuten, dass dies in der Tat ein leistungsstarkes Werkzeug ist, bei dem Aufgaben große Berechnungen benötigen, um sie zu vervollständigen, aber in kleinere Stufen aufgeteilt werden kann, die zu den Sklaven gedrückt werden können, um daran zu arbeiten. Sobald unser Cluster in Betrieb ist, können wir Programme schreiben, um in Python, Java und Scala darauf auszuführen.
In diesem Tutorial arbeiten wir an einer einzigen Maschine, die Red Hat Enterprise Linux 8 ausführt, und installieren den Spark -Master und den Sklaven auf derselben Maschine. Beachten Sie jedoch, dass die Schritte, die das Slave -Setup beschreiben, auf eine beliebige Anzahl von Computern angewendet werden können. So erstellen Sie einen echten Cluster, der starke Workloads verarbeiten kann. Wir werden auch die erforderlichen Einheitsdateien für die Verwaltung hinzufügen und ein einfaches Beispiel gegen den mit dem verteilten Paket verschickten Cluster ausführen, um sicherzustellen, dass unser System in Betrieb ist.
In diesem Tutorial lernen Sie:
- So installieren Sie Spark Master und Sklave
- So fügen Sie Systemdateien mit Systemd -Einheiten hinzu
- So überprüfen Sie eine erfolgreiche Master-Slave-Verbindung
- So führen Sie einen einfachen Beispieljob auf dem Cluster aus
Funkenhülle mit PySpark. Softwareanforderungen und Konventionen verwendet
| Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Red Hat Enterprise Linux 8 |
| Software | Apache Spark 2.4.0 |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
So installieren Sie Spark auf Redhat 8 Schritt für Schritt Anweisungen
Apache Spark läuft auf JVM (Java Virtual Machine), sodass eine funktionierende Java 8 -Installation erforderlich ist, damit die Anwendungen ausgeführt werden können. Abgesehen davon gibt es mehrere Muscheln innerhalb des Pakets, einer davon ist PYSPARK, Eine Python -basierte Hülle. Um damit zu arbeiten, müssen Sie auch Python 2 installiert und einrichten.
- Um die URL of Sparks neuestes Paket zu erhalten, müssen wir die Site von Spark Downloads besuchen. Wir müssen den Spiegel auswählen, der unserem Standort am nächsten liegt, und die von der Download -Site bereitgestellte URL kopieren. Dies bedeutet auch, dass sich Ihre URL vom folgenden Beispiel unterscheidet. Wir werden das Paket unter installieren
/opt/opt/, Also geben wir das Verzeichnis als einWurzel:# CD /opt
Und füttern Sie die ausgeworbene URL zu
wgetUm das Paket zu bekommen:# WGet https: // www-euu.Apache.org/dist/spark/spark-2.4.0/Spark-2.4.0-bin-hadoop2.7.TGZ
- Wir werden den Tarball auspacken:
# TAR -XVF Spark -2.4.0-bin-hadoop2.7.TGZ
- Und erstellen Sie einen Symlink, um unsere Pfade in den nächsten Schritten leichter zu erinnern:
# ln -s /opt /spark -2.4.0-bin-hadoop2.7 /opt /Spark
- Wir erstellen einen nicht privilegierten Benutzer, der sowohl Anwendungen, Master als auch Slave ausführt:
# UserAdd Spark
Und setzen Sie es als Eigentümer des Ganzen
/opt/SparkVerzeichnis rekursiv:# Chown -r Spark: Spark /Opt /Spark*
- Wir schaffen a
systemdEinheitsdatei/etc/systemd/system/spark-master.ServiceFür den Master -Service mit folgenden Inhalten:
Kopieren[Einheit] Beschreibung = Apache Spark Master After = Netzwerk.Ziel [Service] type = gabing user = Spark Group = Spark Execstart =/opt/spark/sbin/start-master.sh execstop =/opt/spark/sbin/stopmaster.sh [install] wantby by = multi-user.ZielUnd auch einen für den Sklavendienst, der sein wird
/etc/systemd/system/spark-slave.Service.Servicemit dem folgenden Inhalt:
Kopieren[Einheit] Beschreibung = Apache Spark Slave After = Netzwerk.Ziel [Service] type = gabing user = spark Group = Spark execstart =/opt/spark/sbin/start-slave.SH Spark: // rhel8lab.Linuxconfig.org: 7077 execStop =/opt/spark/sbin/stop-slave.sh [install] wantby by = multi-user.ZielBeachten Sie die hervorgehobene Funken -URL. Dies ist mit konstruiert
Spark: //: 7077, In diesem Fall hat der Laborgerät, auf dem der Master ausgeführt wird, den Hostnamenrhel8lab.Linuxconfig.Org. Der Name Ihres Meisters wird anders sein. Jede Sklaven müssen in der Lage sein, diesen Hostnamen aufzulösen und den Master am angegebenen Port zu erreichen, der Port ist7077standardmäßig. - Mit den Servicedateien müssen wir fragen
systemdsie erneut lesen:# Systemctl Daemon-Reload
- Wir können unseren Funkenmeister mit beginnen
systemd:# Systemctl Start Spark-Master.Service
- Um zu überprüfen, ob unser Master ausgeführt und funktioniert, können wir den Systemd -Status verwenden:
# Systemctl Status Spark-Master.Service Spark-Master.Service - Apache Spark Master geladen: geladen (/etc/systemd/system/spark -master.Service; Behinderte; Anbieter Voreinstellung: Behindert) aktiv: aktiv (laufend) seit Fr 2019-01-11 16:30:03 CET; Vor 53 Minuten Prozess: 3308 execStop =/opt/spark/sbin/stopmaster.SH (Code = beendet, Status = 0/Erfolg) Prozess: 3339 execstart =/opt/spark/sbin/startmaster.SH (Code = beendet, Status = 0/Erfolg) Hauptpid: 3359 (Java) Aufgaben: 27 (Grenze: 12544) Speicher: 219.3M CGROUP: /System.Slice/Spark-Master.Service 3359/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org org.Apache.Funke.einsetzen.Meister.Meister -Host […] 11. Januar 16:30:00 RHEL8LAB.Linuxconfig.org systemd [1]: Apache Spark Master starten… 11. Januar 16:30:00 RHEL8LAB.Linuxconfig.org-Startmeister.SH [3339]: Organ org.Apache.Funke.einsetzen.Meister.Master, Anmelde an/opt/spark/logs/spark-spark-org.Apache.Funke.einsetzen.Meister.Master-1 […]
Die letzte Zeile gibt auch die Hauptprotokolldatei des Meisters an, die sich in der befindet
ProtokolleVerzeichnis unter dem Funken -Basisverzeichnis,/opt/Sparkin unserem Fall. Durch die Untersuchung dieser Datei sollten wir am Ende eine Zeile sehen, die dem folgenden Beispiel ähnelt:2019-01-11 14:45:28 Info Master: 54-Ich wurde zum Führer gewählt! Neuer Staat: lebendig
Wir sollten auch eine Zeile finden, die uns sagt, wo die Master -Oberfläche zuhört:
2019-01-11 16:30:03 Info Utils: 54-erfolgreich gestartet Service 'MasterUi' auf Port 8080
Wenn wir einen Browser auf den Port des Host Machine verweisen
8080, Wir sollten die Statusseite des Meisters sehen, ohne dass im Moment keine Arbeiter angehängt sind.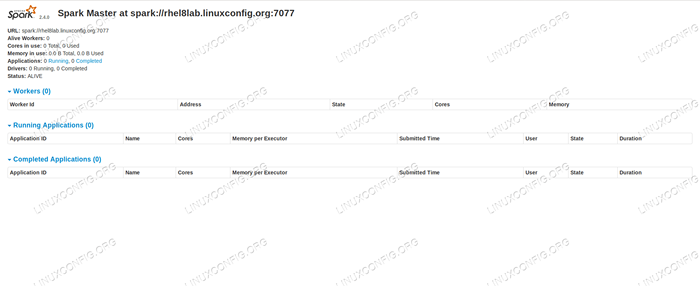 Funken -Master -Statusseite ohne Arbeiter angeschlossen.
Funken -Master -Statusseite ohne Arbeiter angeschlossen. Beachten Sie die URL -Linie auf der Statusseite des Spark Master's Status. Dies ist die gleiche URL, die wir für die Einheitsdatei eines Sklavens verwenden müssen, in der wir erstellt wurden
Schritt 5.
Wenn wir eine Fehlermeldung im Browser erhalten, müssen wir wahrscheinlich den Port in der Firewall öffnen:# Firewall-cmd --zone = public --add-port = 8080/tcp --permanent Erfolg # Firewall-CMD-Reload Erfolg
- Unser Meister läuft, wir werden ihm einen Sklaven befestigen. Wir beginnen den Sklavenservice:
# Systemctl Start Spark-Slave.Service
- Wir können überprüfen, ob unser Sklave mit Systemd ausgeführt wird:
# Systemctl Status Spark-Slave.Service Spark-Slave.Service - Apache Spark Slave geladen: geladen (/etc/systemd/system/spark -slave.Service; Behinderte; Anbieter Voreinstellung: Behindert) aktiv: aktiv (laufend) seit Fr 2019-01-11 16:31:41 CET; 1H vor 3 Minuten Prozess: 3515 execStop =/opt/spark/sbin/stop-slave.SH (Code = beendet, Status = 0/Erfolg) Prozess: 3537 execstart =/opt/spark/sbin/start-slave.SH Spark: // rhel8lab.Linuxconfig.Org: 7077 (Code = beendet, Status = 0/Erfolg) Hauptpid: 3554 (Java) Aufgaben: 26 (Grenze: 12544) Speicher: 176.1m Cgroup: /System.Slice/Spark-Sklave.Service 3554/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org org.Apache.Funke.einsetzen.Arbeiter.Arbeiter […] 11. Januar 16:31:39 rhel8lab.Linuxconfig.org systemd [1]: Apache Spark Slave starten… 11. Januar 16:31:39 RHEL8LAB.Linuxconfig.Org Start-Sklave.SH [3537]: Organ org.Apache.Funke.einsetzen.Arbeiter.Arbeiter, Anmeldung an/opt/spark/logs/spark-spar […]
Diese Ausgabe liefert auch den Pfad zur Protokolldatei des Sklaven (oder des Arbeiters), der sich im selben Verzeichnis befindet, mit „Arbeiter“ im Namen. Durch die Überprüfung dieser Datei sollten wir etwas Ähnliches wie die folgende Ausgabe sehen:
2019-01-11 14:52:23 Info Worker: 54-Verbindung mit Master Rhel8lab herstellen.Linuxconfig.org: 7077… 2019-01-11 14:52:23 Info consexHandler: 781-Start o.S.J.S.ServletContexTHandler@62059f4a /metrics/json, null, verfügbar,@Spark 2019-01-11 14:52:23 Info TransportClientFactory: 267-erfolgreich erstellt eine Verbindung zu RHEL8LAB erstellt.Linuxconfig.org/10.0.2.15: 7077 nach 58 ms (0 ms in Bootstraps ausgegeben) 2019-01-11 14:52:24 Info Worker: 54-erfolgreich bei Master Spark: // rhel8lab registriert.Linuxconfig.Org: 7077
Dies zeigt an, dass der Arbeiter erfolgreich mit dem Meister verbunden ist. In derselben Protokolldatei werden wir eine Zeile finden, die uns der URL sagt, die der Arbeiter hört:
2019-01-11 14:52:23 Info Workerwebui: 54-gebundener Arbeiterwebui bis 0.0.0.0 und begann unter http: // rhel8lab.Linuxconfig.Org: 8081
Wir können unseren Browser auf die Statusseite des Arbeiters verweisen, auf der der Master aufgeführt ist.
 Funken -Worker -Statusseite, mit Master verbunden.
Funken -Worker -Statusseite, mit Master verbunden.
Bei der Protokolldatei des Master sollte eine überprüfende Zeile angezeigt werden:
2019-01-11 14:52:24 Info Master: 54-Registrierung von Arbeitern 10.0.2.15: 40815 mit 2 Kernen, 1024.0 MB RAM
Wenn wir jetzt die Statusseite des Masters neu laden, sollte auch der Arbeiter dort mit einem Link zu seiner Statusseite erscheinen.
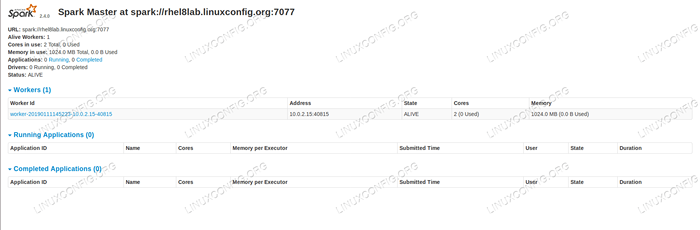 Funken -Master -Statusseite mit einem angehängten Arbeiter.
Funken -Master -Statusseite mit einem angehängten Arbeiter. Diese Quellen überprüfen, dass unser Cluster angehängt und bereit ist zu arbeiten.
- Um eine einfache Aufgabe im Cluster auszuführen, führen wir eines der Beispiele aus, die mit dem von uns heruntergeladenen Paket ausgeliefert wurden. Betrachten Sie die folgende einfache Textdatei
/opt/spark/test.Datei:
KopierenZeile1 Word1 Word2 Word3 Zeile2 Word1 Zeile3 Word1 Word2 Word3 Word4Wir werden die ausführen
Wortzahl.pyBeispiel dazu, dass das Vorfall jedes Wortes in der Datei zählt. Wir können die verwendenFunkeBenutzer, neinWurzelPrivilegien benötigt.$/opt/spark/bin/spark-submit/opt/spark/example/src/main/python/wordcount.PY/OPT/Spark/Test.Datei 2019-01-11 15:56:57 Info SparkContext: 54-Eingereichtes Antrag: PythonwordCount 2019-01-11 15:56:57 Info SecurityManager: 54-Ansicht der ACLs Ansicht in: Spark 2019-01111 15:56: 57 Info SecurityManager: 54 - Ändern ändern ACLs an: Spark […]
Wenn die Aufgabe ausgeführt wird, wird eine lange Ausgabe bereitgestellt. Schließlich wird das Ergebnis angezeigt. Der Cluster berechnet die erforderlichen Informationen:
2019-01-11 15:57:05 Info Dagscheduler: 54-Job 0 Fertig: Sammeln.PY: 40, genommen 1.619928 s Zeile3: 1 Zeile2: 1 Zeile1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 […]
Damit haben wir unseren Apache -Funken in Aktion gesehen. Zusätzliche Sklavenknoten können installiert und angebracht werden, um die Rechenleistung unseres Clusters zu skalieren.
Verwandte Linux -Tutorials:
- So erstellen Sie einen Kubernetes -Cluster
- Oracle Java Installation auf Ubuntu 20.04 fokale Fossa Linux
- Dinge zu installieren auf Ubuntu 20.04
- So installieren Sie Java unter Manjaro Linux
- Linux: Java installieren
- So installieren Sie Kubernetes auf Ubuntu 20.04 fokale Fossa Linux
- So installieren Sie Kubernetes auf Ubuntu 22.04 Jammy Quallen…
- Ubuntu 20.04 Hadoop
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- Ubuntu 20.04 WordPress mit Apache -Installation