

So überwachen Sie die Systemnutzung, Ausfälle und Fehlerbehebung bei Linux -Servern - Teil 9

- 4252
- 338
- Tamina Liebach
Obwohl Linux sehr zuverlässig ist, sollten weise Systemadministratoren einen Weg finden, das Verhalten und die Nutzung des Systems jederzeit im Auge zu behalten. Gewährleistung einer Betriebszeit so nahe 100% wie möglich und die Verfügbarkeit von Ressourcen sind in vielen Umgebungen kritische Bedürfnisse. Durch die Untersuchung des vergangenen und aktuellen Status des Systems können wir vorhersehen und höchstwahrscheinlich mögliche Probleme verhindern.
 Linux Foundation Certified Engineer - Teil 9
Linux Foundation Certified Engineer - Teil 9 Einführung des Linux Foundation -Zertifizierungsprogramms
In diesem Artikel werden wir eine Liste mit einigen Tools vorstellen, die in den meisten vorgelagerten Verteilungen verfügbar sind, um den Systemstatus zu überprüfen, Ausfälle zu analysieren und fortlaufende Probleme zu beheben. Insbesondere der unzähligen verfügbaren Daten konzentrieren wir uns auf CPU, Speicherplatz und Speicherauslastung, grundlegende Prozessverwaltung und Protokollanalyse.
Speicherplatzauslastung
Es gibt 2 bekannte Befehle in Linux, die zur Überprüfung des Speicherplatzverbrauchs verwendet werden: df Und Du.
Der erste, df (Was für Disk Free steht), wird in der Regel verwendet, um die Nutzung der gesamten Festplattenspeicher nach Dateisystem zu melden.
Beispiel 1: Berichterstattung über den Speicherplatzieren in Bytes und das menschliche Lesbarformat
Ohne Optionen, df meldet Speicherplatznutzung in Bytes. Mit dem -H Markieren Sie die gleichen Informationen mit MB oder GB stattdessen. Beachten Sie, dass dieser Bericht auch die Gesamtgröße jedes Dateisystems (in 1-k-Blöcken), die freien und verfügbaren Räume und den Mountspunkt jedes Speichergeräts enthält.
# df # df -h
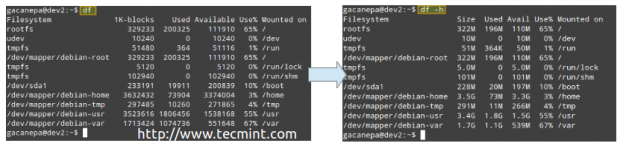 Speicherplatznutzung
Speicherplatznutzung Das ist sicherlich schön - aber es gibt eine weitere Einschränkung, die ein Dateisystem unbrauchbar machen kann, und der Inodes ausgeht. Alle Dateien in einem Dateisystem werden einem Inode zugeordnet, der seine Metadaten enthält.
Beispiel 2: Inspektion der Inode-Verwendung nach Dateisystem in menschlich-lesbarem Format mit
# df -hti
Sie können die Menge der gebrauchten und verfügbaren Inodes sehen:
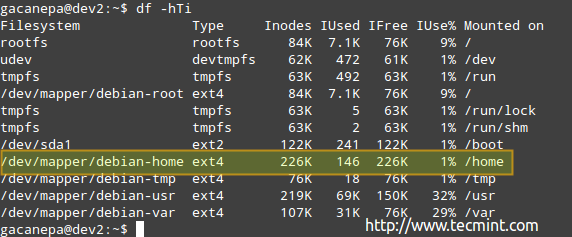 Inode -Disk -Nutzung
Inode -Disk -Nutzung Nach dem obigen Bild gibt es 146 gebrauchte Inodes (1%) in /home, was bedeutet, dass Sie in diesem Dateisystem weiterhin 226K -Dateien erstellen können.
Beispiel 3: Finden und / oder Löschen leerer Dateien und Verzeichnisse
Beachten Sie, dass Ihnen der Speicherplatz noch lange vor Inodes und umgekehrt ausgeht, und umgekehrt. Aus diesem Grund müssen Sie nicht nur die Auslastung des Speicherplatzes, sondern auch die Anzahl der vom Dateisystem verwendeten Inodes überwachen.
Verwenden Sie die folgenden Befehle, um leere Dateien oder Verzeichnisse (die 0B belegen) zu finden, die Inodes ohne Grund verwenden:
# FIND /HOME -TYPE F -EMPTY # FIND /HOME -TYPE D -WELLY
Außerdem können Sie die hinzufügen -löschen FLACHEN SIE AN DEN ENDE VON JEDEM Befehl, wenn Sie diese leeren Dateien und Verzeichnisse auch löschen möchten:
# find /home -typ f -ießer
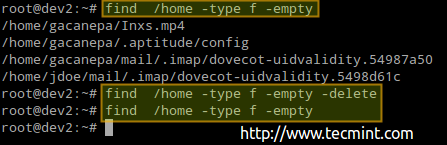 Finden und löschen Sie leere Dateien unter Linux
Finden und löschen Sie leere Dateien unter Linux Die vorherige Prozedur hat 4 Dateien gelöscht. Lassen Sie uns erneut die Anzahl der gebrauchten / verfügbaren Knoten in / home überprüfen:
# df -hti | Grep Home
 Überprüfen Sie die Verwendung von Linux -Inode -Nutzung
Überprüfen Sie die Verwendung von Linux -Inode -Nutzung Wie Sie sehen können, gibt es 142 verwendete Inodes jetzt (4 weniger als zuvor).
Beispiel 4: Untersuchung der Festplattennutzung nach Verzeichnis
Wenn die Verwendung eines bestimmten Dateisystems über einem vordefinierten Prozentsatz liegt, können Sie verwenden Du (Kurz gesagt, für die Festplattennutzung), um herauszufinden, welche Dateien die meisten Platz einnehmen.
Das Beispiel ist gegeben für /var, Was wie Sie im ersten Bild oben sehen können, wird bei 67% verwendet.
# du -sch /var /*
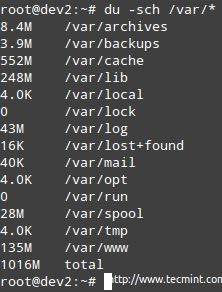 Überprüfen Sie die Nutzung von Speicherplatz nach Verzeichnis
Überprüfen Sie die Nutzung von Speicherplatz nach Verzeichnis Notiz: Dass Sie zu einem der oben genannten Unterverzeichnisse wechseln können, um genau herauszufinden, was sich in ihnen befindet und wie viel jeder Artikel einnimmt. Sie können diese Informationen dann verwenden, um einige Dateien entweder zu löschen, wenn nicht benötigt wird, oder die Größe des logischen Volumens bei Bedarf verlängern.
Lesen Sie auch
- 12 nützliche „DF“ -Kande, um den Speicherplatz zu überprüfen
- 10 nützliche „DU“ -Hindungen, um die Datenträgernutzung von Dateien und Verzeichnissen zu finden
Speicher- und CPU -Nutzung
Das klassische Tool in Linux, mit dem eine Gesamtüberprüfung der CPU / Speicherauslastung und der Prozessverwaltung durchgeführt wird, ist der Top -Befehl. Darüber hinaus zeigt Top eine Echtzeitansicht eines laufenden Systems an. Es gibt andere Tools, die für denselben Zweck verwendet werden könnten, wie z. B. HTOP, aber ich habe mich mit Top entschieden.
Beispiel 5: Anzeigen eines Live -Status Ihres Systems mit oben
Um an der Spitze zu starten, geben Sie einfach den folgenden Befehl in Ihre Befehlszeile ein und drücken Sie die Eingabetaste.
# Spitze
Untersuchen wir eine typische Top -Ausgabe:
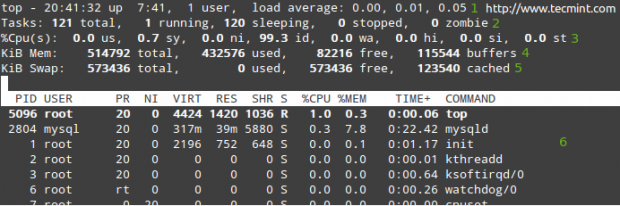 Listen Sie alle laufenden Prozesse unter Linux auf
Listen Sie alle laufenden Prozesse unter Linux auf In Zeilen 1 bis 5 werden folgende Informationen angezeigt:
1. Die aktuelle Zeit (8:41:32 Uhr) und Betriebszeit (7 Stunden und 41 Minuten). Nur ein Benutzer ist am System angemeldet, und der Lastdurchschnitt während der letzten 1, 5 bzw. 15 Minuten. 0.00, 0.01 und 0.05 Geben Sie an, dass das System über diese Zeitintervalle in 0% der Zeit im Leerlauf war (0.00: Keine Prozesse warteten auf die CPU), es wurde dann um 1% (0) überladen.01: durchschnittlich 0.01 Prozesse warteten auf die CPU) und 5% (0.05). Wenn weniger als 0 und je kleiner die Zahl (0).65 zum Beispiel) war das System in den letzten 1, 5 oder 15 Minuten für 35% im Leerlauf, je nachdem, wo 0.65 erscheint.
2. Derzeit werden 121 Prozesse ausgeführt (Sie können die vollständige Auflistung in 6 sehen). Nur 1 von ihnen läuft (oben in diesem Fall, wie Sie in der %CPU -Spalte sehen können) und die restlichen 120 warten jedoch im Hintergrund, „schlafen“ und bleiben in diesem Zustand, bis wir sie anrufen. Wie? Sie können dies überprüfen, indem Sie eine MySQL -Eingabeaufforderung öffnen und ein paar Abfragen ausführen. Sie werden feststellen, wie die Anzahl der laufenden Prozesse zunimmt.
Alternativ können Sie einen Webbrowser öffnen und zu einer bestimmten Seite navigieren, die von Apache bedient wird, und Sie erhalten das gleiche Ergebnis. Natürlich gehen diese Beispiele davon aus, dass beide Dienste auf Ihrem Server installiert sind.
3. US (Zeitläufe von Benutzerprozessen mit unmodifizierter Priorität), SY (Zeitausführung von Kernelprozessen), NI (Zeitläufe von Benutzerprozessen mit geänderter Priorität), WA (Zeit, die auf die E/A -Fertigstellung warten), HI (Zeit für die Zeit, die die Hardware für die Zeit für die Wartung von Hardware für die Zeit für die Hardware für die Wartung von Zeiten vervollständigt), SI (Zeit für die Zeit für die Wartung von Software), ST (Zeit, die der aktuelle VM vom Hypervisor gestohlen hat - nur in virtualisierten Umgebungen).
4. Physischer Gedächtnisgebrauch.
5. Raumnutzung tauschen.
Beispiel 6: Untersuchung der Verwendung des physischen Gedächtnisses
Um den RAM -Speicher zu inspizieren und die Nutzung auszutauschen, können Sie auch verwenden frei Befehl.
# frei
 Überprüfen Sie die Verwendung von Linux -Speicher
Überprüfen Sie die Verwendung von Linux -Speicher Natürlich können Sie auch die verwenden -M (Mb) oder -G (GB) Umschaltet, um dieselben Informationen in der menschlichen lesbaren Form anzuzeigen:
# frei -m
 Linux -Speicherverbrauch anzeigen
Linux -Speicherverbrauch anzeigen In jedem Fall müssen Sie sich der Tatsache bewusst sein, dass der Kernel so viel Speicher wie möglich reserviert und den Prozessen zur Verfügung steht, wenn sie ihn anfordern. Besonders das “-/+ Puffer/CacheDie Zeile zeigt die tatsächlichen Werte, nachdem dieser I/A -Cache berücksichtigt wird.
Mit anderen Worten, die von Prozessen verwendete Speichermenge und die Menge, die anderen Prozessen zur Verfügung steht (in diesem Fall, 232 MB gebraucht und 270 MB jeweils verfügbar). Wenn Prozesse diesen Speicher benötigen, verringert der Kernel automatisch die Größe des E/A -Cache.
Lesen Sie auch: 10 nützlicher „kostenloser“ Befehl zum Überprüfen der Linux -Speicherverwendung
Sehen Sie sich Prozesse genauer an
Zu jedem Zeitpunkt gibt es viele Prozesse, die auf unserem Linux -System ausgeführt werden. Es gibt zwei Tools, mit denen wir Prozesse genau überwachen werden: ps Und Pstree.
Beispiel 7: Anzeige der gesamten Prozessliste in Ihrem System mit PS (Volles Standardformat)
Verwendung der -e Und -F Optionen kombiniert zu einem (-EF) Sie können alle Prozesse auflisten, die derzeit auf Ihrem System ausgeführt werden. Sie können diese Ausgabe an andere Werkzeuge wie z Grep (Wie in Teil 1 der LFCS -Serie erläutert), um die Ausgabe auf Ihren gewünschten Prozess (ES) einzugrenzen:
# ps -f | Grep -i Tintenfisch | Grep -v Grep
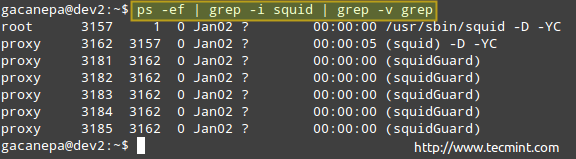 Überwachungsprozesse unter Linux
Überwachungsprozesse unter Linux Die obige Vorgangsauflistung zeigt die folgenden Informationen:
Eigentümer des Prozesses, PID, übergeordnete PID (übergeordneter Prozess), Prozessornutzung, Zeit, zu der der Befehl startete, tty (der ? Gibt an.
Beispiel 8: Anpassen und Sortieren der Ausgabe von PS
Vielleicht benötigen Sie jedoch nicht all diese Informationen und möchten dem Eigentümer des Prozesses, dem Befehl, der ihn gestartet hat Speicher verwendet in absteigender Reihenfolge (beachten Sie, dass PS standardmäßig nach PID sortiert wird).
# ps -eo Benutzer, COMM, PID, PPID,%mem - -sort -%mem
Wobei das Minus vor %Mem angibt, dass die Sortierung in absteigender Reihenfolge sortiert wird.
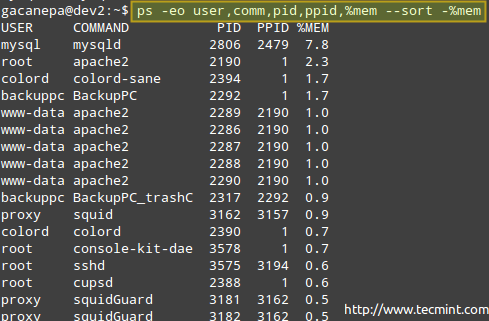 Überwachen Sie die Verwendung von Linux -Prozessspeicher verwendet
Überwachen Sie die Verwendung von Linux -Prozessspeicher verwendet Wenn aus irgendeinem Grund ein Prozess zu viel Systemressourcen einnimmt und wahrscheinlich die Gesamtfunktionalität des Systems gefährdet wird, sollten Sie die Ausführung einstellen oder pausieren, die eines der folgenden Signale mit dem Kill -Programm an sie weitergeben. Andere Gründe, warum Sie dies tun würden, ist, wenn Sie einen Prozess im Vordergrund gestartet haben, ihn aber innehalten und im Hintergrund wieder aufnehmen möchten.
| Signalname | Signalzahl | Beschreibung |
| Sigterm | 15 | Töte den Prozess anmutig. |
| Sigint | 2 | Dies ist das Signal, das gesendet wird, wenn wir Strg + C drücken. Es zielt darauf ab, den Prozess zu unterbrechen, aber der Prozess kann ihn ignorieren. |
| Sigkill | 9 | Dieses Signal unterbricht auch den Prozess, aber dies bedingungslos (mit Sorgfalt verwenden!) Da ein Prozess ihn nicht ignorieren kann. |
| SEUFZEND | 1 | Kurz gesagt, für „Aufhängen“ anweist diese Signale Dämonen, seine Konfigurationsdatei erneut zu lesen, ohne den Prozess tatsächlich zu stoppen. |
| SIGTSTP | 20 | Pause Ausführung und warte bereit, fortzufahren. Dies ist das Signal, das gesendet wird, wenn wir die Strg + Z -Schlüsselkombination eingeben. |
| Sigstop | 19 | Der Vorgang wird innehalten und wird aus den CPU -Zyklen erst mehr beachtet, wenn er neu gestartet wird. |
| Sigcont | 18 | Dieses Signal gibt den Prozess an, die Ausführung wieder aufzunehmen, nachdem sie entweder SIGTSTP oder Sigstop erhalten hat. Dies ist das Signal, das von der Shell gesendet wird, wenn wir die FG- oder BG -Befehle verwenden. |
Beispiel 9: Pause der Ausführung eines laufenden Prozesses und wieder aufnimmt ihn im Hintergrund wieder
Wenn die normale Ausführung eines bestimmten Prozesses impliziert, dass während des Ausführens keine Ausgabe an den Bildschirm gesendet wird, möchten Sie möglicherweise entweder im Hintergrund starten (Anhänge eines Ampers und am Ende des Befehls).
Prozessname &
oder,
Sobald es im Vordergrund angefangen hat, meieren Sie es und senden Sie es mit dem Hintergrund mit
Strg + z
# Kill -18 PID
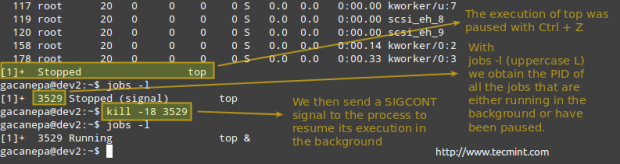 Tötenprozess in Linux töten
Tötenprozess in Linux töten Beispiel 10: Tötung mit Gewalt einen Prozess „wild geworden“
Bitte beachten Sie, dass jede Verteilung Tools bereitstellt Service in sysv-basierten Systemen oder Systemctl In systemd-basierten Systemen.
Wenn ein Prozess nicht auf diese Dienstprogramme reagiert, können Sie ihn mit Gewalt töten, indem Sie ihm das Sigkill -Signal an ihn senden.
# ps -f | Grep Apache # Kill -9 3821
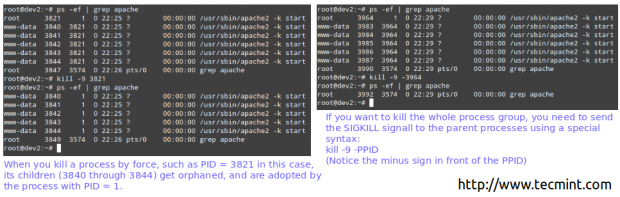 Töten Sie einen Linux -Prozess gewaltsam ab
Töten Sie einen Linux -Prozess gewaltsam ab Also ... was ist passiert / passiert?
Wenn es im System irgendeine Art von Ausfall gab (sei es ein Stromausfall, ein Hardwarefehler, eine geplante oder ungeplante Unterbrechung eines Prozesses oder überhaupt eine Abnormalität), die Protokolle in /var/log Sind Ihre besten Freunde, um festzustellen, was passiert ist oder was die Probleme verursachen könnte, mit denen Sie konfrontiert sind.
# cd /var /log
 Linux -Protokolle anzeigen
Linux -Protokolle anzeigen Einige der Gegenstände in /var/log sind reguläre Textdateien, andere sind Verzeichnisse und andere sind komprimierte Dateien von rotierten (historischen) Protokollen. Sie möchten diejenigen mit dem Wortfehler in ihrem Namen überprüfen, aber der Rest kann auch nützlich sein.
Beispiel 11: Untersuchung der Protokolle auf Fehler in Prozessen
Stellen Sie sich dieses Szenario vor. Ihre LAN -Clients können nicht auf Netzwerkdrucker drucken. Der erste Schritt zur Fehlerbehebung dieser Situation wird /var/log/tups Verzeichnis und sehen, was da drin ist.
Du kannst den ... benutzen Schwanz Befehl zum Anzeigen der letzten 10 Zeilen der Datei "ERROR_LOG) oder Tail -f ERROR_LOG Für eine Echtzeitansicht des Protokolls.
# cd/var/log/cups # ls # tail error_log
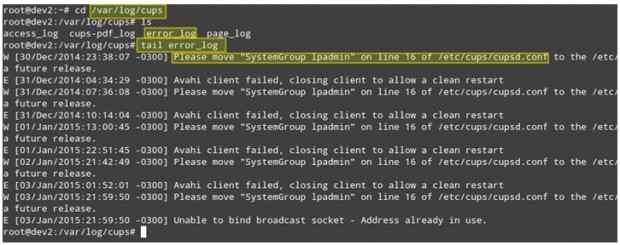 Überwachen Sie Protokolldateien in Echtzeit
Überwachen Sie Protokolldateien in Echtzeit Der obige Screenshot bietet einige hilfreiche Informationen, um zu verstehen, was Ihr Problem verursachen könnte. Beachten Sie, dass die Befolgung der Schritte oder die Korrektur der Fehlfunktion des Prozesses das Gesamtproblem möglicherweise noch nicht lösen. Wenn Sie jedoch von Anfang an verwendet werden, um die Protokolle jedes Mal zu überprüfen, wenn ein Problem auftritt (sei es ein lokales oder ein Netzwerk), Sie Ich werde definitiv auf dem richtigen Weg sein.
Beispiel 12: Untersuchung der Protokolle auf Hardwarefehler untersuchen
Obwohl Hardwarefehler schwierig sein können, um Fehler zu beheben, sollten Sie das überprüfen dmesg und Nachrichtenprotokolle und Grep für verwandte Wörter zu einem Hardware -Teil, das fehlerhaft vermutet wurde.
Das Bild unten wird von entnommen /var/log/messages Nach der Suche nach dem Wortfehler unter Verwendung des folgenden Befehls:
# Less/var/log/messages | Grep -i -Fehler
Wir können sehen, dass wir ein Problem mit zwei Speichergeräten haben: /dev/sdb Und /dev/sdc, was wiederum ein Problem mit dem RAID -Array verursacht.
 Fehlerbehebung bei Linuxproblemen
Fehlerbehebung bei Linuxproblemen Abschluss
In diesem Artikel haben wir einige der Tools untersucht, mit denen Sie immer den Gesamtstatus Ihres Systems bewusst sind. Darüber hinaus müssen Sie sicherstellen, dass Ihr Betriebssystem und installierte Pakete auf ihren neuesten stabilen Versionen aktualisiert werden. Und vergessen Sie niemals, die Protokolle zu überprüfen! Dann werden Sie in die richtige Richtung gehen, um die endgültige Lösung für alle Probleme zu finden.
Fühlen Sie sich frei, Ihre Kommentare, Vorschläge oder Fragen zu hinterlassen - wenn Sie das folgende Formular verwenden.
Werden Sie ein Linux -zertifizierter Ingenieur- « So richten Sie ein Netzwerk -Repository zur Installation oder Aktualisierung von Paketen ein - Teil 11
- So richten Sie eine Iptables -Firewall ein, um den Remote -Zugriff auf Dienste unter Linux - Teil 8 zu ermöglichen »