

So wiederherstellen Sie Daten und fehlgeschlagene Software -RAIDs - Teil 8

- 2064
- 261
- Susanne Stoutjesdijk
In den vorherigen Artikeln dieser RAID. Wir haben mehrere Software -RAID -Konfigurationen überprüft und das Wesentliche der einzelnen sowie die Gründe erklärt, warum Sie sich je nach Ihrem spezifischen Szenario dem einen oder anderen anwenden würden.
 Wiederherstellung von Rebuild fehlgeschlagene Software RAIDs - Teil 8
Wiederherstellung von Rebuild fehlgeschlagene Software RAIDs - Teil 8 In diesem Leitfaden diskutieren wir, wie ein Software -RAID -Array ohne Datenverlust wieder aufgebaut wird. Für die Kürze werden wir nur eine in Betracht ziehen Überfall 1 Setup - aber die Konzepte und Befehle gelten für alle Fälle gleichermaßen.
RAID -Testszenario
Bevor Sie weiter fortfahren, stellen Sie bitte sicher, dass Sie a eingerichtet haben Überfall 1 Array folgt den Anweisungen in Teil 3 dieser Serie: So richten Sie RAID 1 (Mirror) unter Linux ein.
Die einzigen Variationen in unserem vorliegenden Fall sind:
1) Eine andere Version von CentOS (V7) als die in diesem Artikel verwendete (v6.5) und
2) verschiedene Scheibengrößen für /dev/sdb Und /dev/sdc (Jeweils 8 GB).
Außerdem wenn, wenn Selinux Im Durchsetzungsmodus ist aktiv. Andernfalls werden Sie auf diese Warnmeldung stoßen, während Sie versuchen, sie zu montieren:
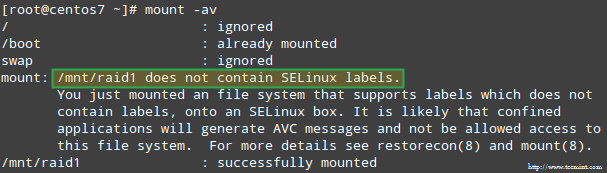 Selinux Raid Mount -Fehler
Selinux Raid Mount -Fehler Sie können dies durch Ausführen beheben:
# restorecon -r /mnt /raid1
RAID -Überwachung einrichten
Es gibt eine Vielzahl von Gründen, warum ein Speichergerät ausfallen kann (SSDs haben jedoch die Wahrscheinlichkeit, dass dies geschehen Teil und um die Verfügbarkeit und Integrität Ihrer Daten zu gewährleisten.
Zuerst ein Rat der Ratschläge. Auch wenn Sie inspizieren können /proc/mdstat Um den Status Ihrer Überfälle zu überprüfen, gibt es eine bessere und zeitsparende Methode, die aus dem Laufen besteht mdadm Im Monitor + Scan -Modus, der Warnungen per E -Mail an einen vordefinierten Empfänger sendet.
Um dies einzurichten, fügen Sie die folgende Zeile hinzu in /etc/mdadm.Conf:
Mailaddr [E -Mail geschützt]
In meinem Fall:
Mailaddr [E -Mail geschützt]
 RAID -Überwachungs -E -Mail -Warnungen
RAID -Überwachungs -E -Mail -Warnungen Laufen mdadm Fügen Sie im Monitor + Scan -Modus den folgenden Crontab -Eintrag als Root hinzu:
@Reboot /sbin /mdadm -Monitor -scan --oneshot
Standardmäßig, mdadm Überprüft die RAID -Arrays alle 60 Sekunden und sendet eine Warnung, wenn es ein Problem findet. Sie können dieses Verhalten ändern, indem Sie das hinzufügen --Verzögerung Option zum obigen Crontab -Eintrag zusammen mit der Menge von Sekunden (zum Beispiel, --Verzögerung 1800 bedeutet 30 Minuten).
Schließlich stellen Sie sicher, dass Sie eine haben E -Mail -Benutzer -Agent (MUA) installiert, wie Mutt oder Mailx. Andernfalls erhalten Sie keine Warnungen.
In einer Minute werden wir sehen, was ein Alarm von gesendet wird mdadm sieht aus wie.
Simulieren und Ersetzen eines fehlgeschlagenen RAID -Speichergeräts
Um ein Problem mit einem der Speichergeräte im RAID -Array zu simulieren, werden wir die verwenden --verwalten Und --Set-Meister Optionen wie folgt:
# MDADM --MANAGE-SET-FAUTY /DEV /MD0 /DEV /SDC1
Dies wird dazu führen /dev/sdc1 als fehlerhaft markiert werden, wie wir sehen können /proc/mdstat:
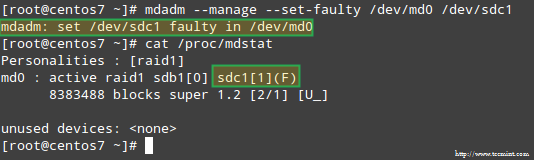 Das Problem mit RAID -Speicher stimulieren
Das Problem mit RAID -Speicher stimulieren Noch wichtiger ist, dass wir sehen, ob wir eine E -Mail -Warnung mit derselben Warnung erhalten haben:
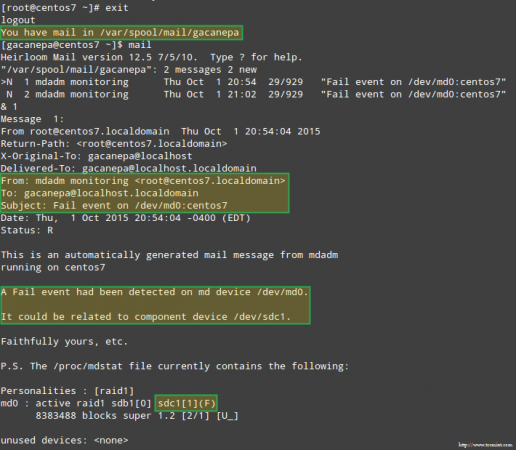 E -Mail -Alarm auf fehlgeschlagenes RAID -Gerät
E -Mail -Alarm auf fehlgeschlagenes RAID -Gerät In diesem Fall müssen Sie das Gerät aus dem Software -RAID -Array entfernen:
# mdadm /dev /md0 -remove /dev /sdc1
Dann können Sie es physisch aus der Maschine entfernen und durch ein Ersatzteil ersetzen (/dev/sdd, wo eine Partition des Typs fd wurde zuvor erstellt):
# MDADM --MANAGE /DEV /MD0 --ADD /DEV /SDD1
Zum Glück für uns wird das System automatisch mit dem Wiederaufbau des Arrays mit dem Teil, den wir gerade hinzugefügt haben. Wir können dies durch Markieren testen /dev/sdb1 als fehlerhaft, um es aus dem Array zu entfernen und sicherzustellen, dass die Datei Tecmint.txt ist immer noch zugänglich bei /mnt/raid1:
# MDADM -DETAIL /DEV /MD0 # MOUNT | GREP RAID1 # ls -l /mnt /raid1 | Grep Tecmint # cat/mnt/raid1/tecmint.txt
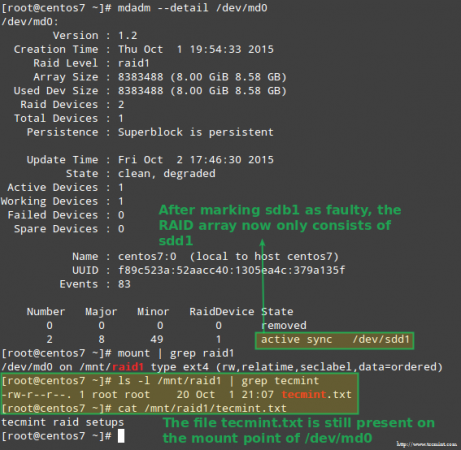 Bestätigen Sie den Wiederaufbau von Raid -Array
Bestätigen Sie den Wiederaufbau von Raid -Array Das obige Bild zeigt das deutlich nach dem Hinzufügen /dev/sdd1 zum Array als Ersatz für /dev/sdc1, Der Wiederaufbau von Daten wurde vom System automatisch ohne Intervention von unserem Teil durchgeführt.
Obwohl nicht ausschließlich erforderlich, ist es eine großartige Idee, ein Ersatzgerät zur Verfügung zu haben, damit der Prozess des Ersetzens des fehlerhaften Geräts durch ein gutes Laufwerk in einem Schnappschuss durchgeführt werden kann. Um das zu tun, lasst uns neu anpassen /dev/sdb1 Und /dev/sdc1:
# MDADM --MANAGE /DEV /MD0 --ADD /DEV /SDB1 # MDADM --MANAGE /DEV /MD0 --ADD /DEV /SDC1
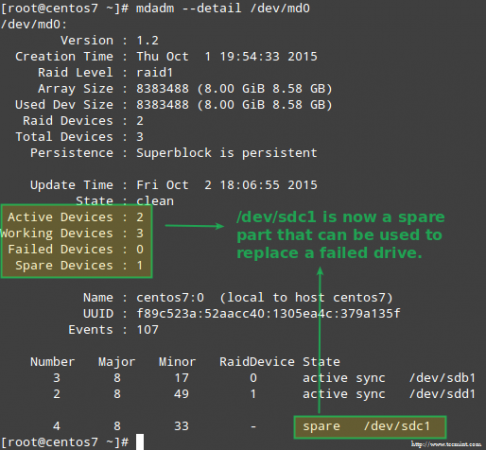 Ersetzen Sie fehlgeschlagenes RAID -Gerät
Ersetzen Sie fehlgeschlagenes RAID -Gerät Erholung von einem Redundanzverlust
Wie bereits erläutert, mdadm wird die Daten automatisch wieder aufbauen, wenn eine Festplatte fehlschlägt. Aber was passiert, wenn 2 Scheiben im Array scheitern?? Lassen Sie uns ein solches Szenario simulieren, indem wir markieren /dev/sdb1 Und /dev/sdd1 als fehlerhaft:
# Umount /Mnt /Raid1 # Mdadm-Manmanage--Set-Faulty /dev /md0 /dev /sdb1 # mdadm --stop /dev /md0 # mdadm-Manmanage--Set-Fault SDD1
Versuche, das Array auf die gleiche Art und Weise zu erstellen, wie es zu diesem Zeitpunkt erstellt wurde (oder die Verwendung der --Übernehmen Sie sie Option) kann zu einem Datenverlust führen, daher sollte sie als letztes Mittel gelassen werden.
Versuchen wir, die Daten aus wiederherzustellen /dev/sdb1, Zum Beispiel in eine ähnliche Festplattenpartition (/dev/sde1 - Beachten Sie, dass Sie eine Partition vom Typ erstellen müssen fd In /dev/sde vor fortfahren) verwenden Ddrescue:
# Ddrescue -r 2 /dev /sdb1 /dev /sde1
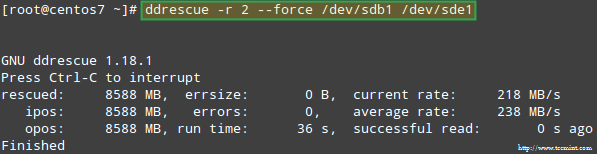 RAID -Array wiederherstellen
RAID -Array wiederherstellen Bitte beachten Sie, dass wir bis zu diesem Zeitpunkt nicht berührt haben /dev/sdb oder /dev/sdd, Die Partitionen, die Teil des RAID -Arrays waren.
Lassen Sie uns nun das Array mithilfe des Arrays wieder aufbauen /dev/sde1 Und /dev/sdf1:
# MDADM-CREATE /DEV /MD0 --LEVEL = MILROR-RAID-DEVICES = 2 /DEV /SD [E-F] 1
Bitte beachten Sie, dass Sie in einer realen Situation in der Regel dieselben Gerätenamen wie beim Original -Array verwenden, dh, /dev/sdb1 Und /dev/sdc1 Nachdem die fehlgeschlagenen Scheiben durch neue ersetzt wurden.
In diesem Artikel habe ich mich für zusätzliche Geräte ausgewählt, um das Array mit brandneuen Festplatten neu zu erstellen und Verwirrung mit den ursprünglichen fehlgeschlagenen Laufwerken zu vermeiden.
Wenn Sie gefragt werden, ob Sie ein Array weiter schreiben sollen, geben Sie an Y und drücke Eingeben. Das Array sollte gestartet werden und Sie sollten in der Lage sein, seinen Fortschritt mit:
# Watch -n 1 Katze /Proc /Mdstat
Nach Abschluss des Vorgangs sollten Sie in der Lage sein, auf den Inhalt Ihres RAID zugreifen zu können:
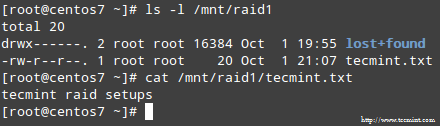 Bestätigen Sie RAID -Inhalte
Bestätigen Sie RAID -Inhalte Zusammenfassung
In diesem Artikel haben wir überprüft, wie sich erholt werden kann ÜBERFALLEN Misserfolge und Redundanzverluste. Sie müssen sich jedoch daran erinnern, dass diese Technologie eine Speicherlösung ist und NICHT Backups ersetzen.
Die in diesem Leitfaden erläuterten Prinzipien gelten für alle RAID -Setups gleichermaßen sowie für die Konzepte, die wir im nächsten und letzten Leitfaden dieser Serie abdecken (RAID -Management).
Wenn Sie Fragen zu diesem Artikel haben, können Sie uns eine Notiz mit dem folgenden Kommentarformular angeben. Wir freuen uns von Ihnen zu hören!
- « So erhalten Sie Hardwareinformationen mit dem Befehl DMideCode unter Linux
- PowerLine - Fügt leistungsstarke Statuslinien und Aufforderungen an VIM -Editor und Bash Terminal hinzu »