

Wie man Hadoop 2 einstellt.6.5 (Einzelknotencluster) auf Ubuntu, Centos und Fedora

- 4767
- 347
- Tamina Liebach
Apache Hadoop 2.6.5 spürbare Verbesserungen gegenüber dem vorherigen Stall 2.X.Y veröffentlicht. Diese Version hat viele Verbesserungen in HDFs und MapReduce. Diese Anleitung hilft Ihnen, Hadoop 2 zu installieren.6 zu CentOS/RHEL 7/6/5, Ubuntu und anderen Debian-basierten Betriebssystemen. Dieser Artikel enthält nicht die Gesamtkonfiguration zum Einrichten von Hadoop. Wir haben nur eine grundlegende Konfiguration, die für die Arbeit mit Hadoop erforderlich ist.
Schritt 1: Java installieren
Java ist die Hauptanforderung, Hadoop auf jedem System einzurichten. Stellen Sie daher sicher, dass Java auf Ihrem System mit dem folgenden Befehl installiert ist.
# Java -version Java Version "1.8.0_101 "Java (TM) SE -Laufzeitumgebung (Build 1.8.0_131-B11) Java Hotspot (TM) 64-Bit Server VM (Build 25.131-B11, gemischter Modus)
Wenn Sie Java nicht auf Ihrem System installiert haben, verwenden Sie eine der folgenden Links, um es zuerst zu installieren.
Installieren Sie Java 8 auf CentOS/RHEL 7/6/5
Installieren Sie Java 8 auf Ubuntu
Schritt 2: Hadoop -Benutzer erstellen
Wir empfehlen, ein normales (noch rootes) Konto für Hadoop -Arbeiten zu erstellen. Erstellen Sie also ein Systemkonto mit dem folgenden Befehl.
# Adduser Hadoop # Passwd Hadoop
Nach dem Erstellen eines Konto. Um dies zu tun, verwenden Sie die folgenden Befehle aus, um die folgenden Befehle auszuführen.
# su -Hadoop $ ssh -keygen -t RSA $ cat ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keys $ chmod 0600 ~/.ssh/autorized_keys
Überprüfen Sie die wichtige Anmeldung. Der folgende Befehl sollte nicht nach dem Passwort fragen, aber das erste Mal, dass das Hinzufügen von RSA zu der Liste der bekannten Hosts auffordert.
$ ssh localhost $ exit
Schritt 3. Herunterladen von Hadoop 2.6.5
Laden Sie jetzt Hadoop 2 herunter.6.0 Quellarchivdatei mit dem folgenden Befehl. Sie können auch einen alternativen Download Mirror auswählen, um die Download -Geschwindigkeit zu erhöhen.
$ cd ~ $ wget http: // www-euu.Apache.org/dist/hadoop/Common/Hadoop-2.6.5/Hadoop-2.6.5.Teer.gz $ tar xzf hadoop-2.6.5.Teer.GZ $ MV Hadoop-2.6.5 Hadoop
Schritt 4. Konfigurieren Sie den Hadoop-Pseudo-verteilten Modus
4.1. Setup Hadoop -Umgebungsvariablen einrichten
Zunächst müssen wir Umgebungsvariablen durch Hadoop einstellen. Bearbeiten ~/.bashrc Datei und Anhängen der folgenden Werte am Ende der Datei.
Export hadoop_home =/home/hadoop/hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop hadoop export hadoop hadoop_hdfs_home Hadoop_Home/sbin: $ hadoop_home/bin
Wenden Sie nun die Änderungen in der aktuellen laufenden Umgebung an
$ source ~/.bashrc
Jetzt bearbeiten $ Hadoop_home/etc/hadoop/hadoop-env.Sch Datei und festgelegt Java_Home Umgebungsvariable. Ändern Sie den Java -Pfad gemäß der Installation Ihres Systems.
Exportieren Sie java_home =/opt/jdk1.8.0_131/
4.2. Konfigurationsdateien bearbeiten
Hadoop hat viele Konfigurationsdateien, die gemäß den Anforderungen konfiguriert werden müssen, um die Hadoop -Infrastruktur einzurichten. Beginnen wir mit der Konfiguration mit Basic Hadoop Single Knode Cluster -Setup. Navigieren Sie zunächst zu unten
$ cd $ hadoop_home/etc/hadoop
Kernstelle bearbeiten.xml
fs.Standard.Name HDFS: // localhost: 9000
HDFS-Site bearbeiten.xml
DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/Hadoopdata/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hadoopdata/hdfs/datanode
Mapred-Site bearbeiten.xml
Karte verkleinern.Rahmen.Nennen Sie Garn
Garnstelle bearbeiten.xml
Garn.NodeManager.AUX-Service MapReduce_Shuffle
4.3. Formatnamenode
Formatieren Sie nun den Namenode mit dem folgenden Befehl und stellen Sie sicher, dass das Speicherverzeichnis ist
$ hdfs namenode -format
Beispielausgabe:
15/02/04 09:58:43 Info Namenode.Namenode: Startup_msg: /************************************************ ******************************************.Tecadmin.NET/192.168.1.133 startup_msg: args = [-format] startup_msg: Version = 2.6.5… 15/02/04 09:58:57 Info gemeinsam.Speicher: Speicherverzeichnis/Home/Hadoop/Hadoopdata/HDFS/Namenode wurde erfolgreich formatiert. 15/02/04 09:58:57 Info Namenode.NnstorageretentionManager: Aufbewahrung 1 Bilder mit TXID> = 0 15/02/04 09:58:57 Info Util.ExitUtil: Ausgang mit Status 0 15/02/04 09:58:57 Info Namenode.Namenode: Shutdown_MSG: /************************************************************************* **************************************.Tecadmin.NET/192.168.1.133************************************************************* ***********/
Schritt 5. Starten Sie Hadoop Cluster
Starten Sie jetzt Ihren Hadoop -Cluster mit den von Hadoop bereitgestellten Skripten. Navigieren Sie einfach zu Ihrem Hadoop SBIN -Verzeichnis und führen Sie die Skripte nacheinander aus.
$ cd $ hadoop_home/sbin/
Jetzt rennen Start-dfs.Sch Skript.
$ start-dfs.Sch
Beispielausgabe:
15/02/04 10:00:34 Warn Util.NativeCodeloader: Die Native-Hadoop-Bibliothek für Ihre Plattform kann nicht geladen werden. Bei [localhost] localhost: starten namenode, an/home/hadoop/logs/hadoop-namenode-svr1 anmelden.Tecadmin.Netz.Out localhost: Datanode starten, an/home/hadoop/hadoop/logs/hadoop-hadoop-datanode-svr1 anmelden.Tecadmin.Netz.Aus dem sekundären Namenoden [0).0.0.0] Die Authentizität des Hosts '0.0.0.0 (0.0.0.0) 'kann nicht festgelegt werden. RSA Key Fingerabdruck ist 3c: C4: F6: F1: 72: D9: 84: F9: 71: 73: 4a: 0d: 55: 2C: F9: 43. Sind Sie sicher, dass Sie sich weiter verbinden möchten (Ja/Nein)? Ja 0.0.0.0: Warnung: Dauerhaft '0 hinzugefügt' 0.0.0.0 '(RSA) zur Liste der bekannten Hosts. 0.0.0.0: SecondaryNamenode beginnen, sich an/home/hadoop/hadoop/logs/hadoop-hadoop-secondaryynamenode-svr1 anmelden.Tecadmin.Netz.Aus dem 15.02.04 10:01:15 Warn Util utile.NativeCodeloader: Die native Hadoop-Bibliothek für Ihre Plattform kann nicht geladen werden
Jetzt rennen Start marnt.Sch Skript.
$ start marn.Sch
Beispielausgabe:
Startgarn-Daemons Starten von Resourcemanager, Anmeldung bei/Home/Hadoop/Hadoop/Logs/Garn-Hadoop-Resourcemanager-SVR1.Tecadmin.Netz.Out localhost: NodeManager starten, an/home/hadoop/hadoop/logs/marn-hadoop-nodemanager-svr1 anmelden.Tecadmin.Netz.aus
Schritt 6. Zugriff auf Hadoop -Dienste im Browser
Hadoop Namenode begann mit Port 50070 Standard. Greifen Sie in Ihrem bevorzugten Webbrowser auf Ihren Server auf Port 50070 zu.
http: // svr1.Tecadmin.Netz: 50070/
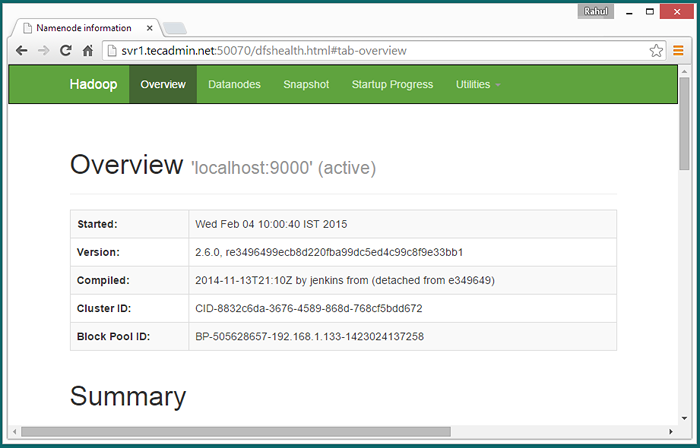
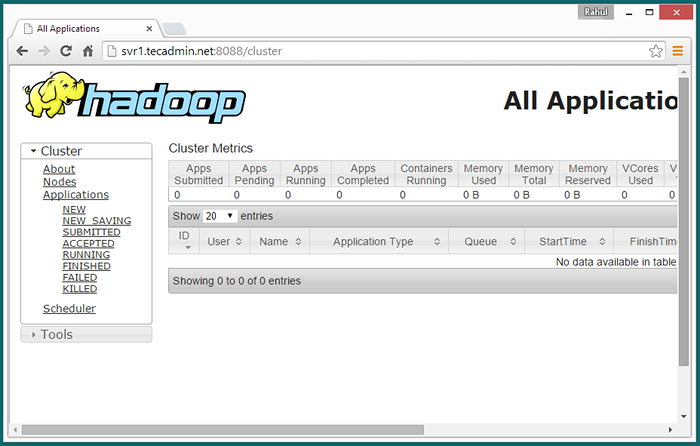
Greifen Sie nun auf Port 8088 zu, um die Informationen über Cluster und alle Anwendungen zu erhalten
http: // svr1.Tecadmin.Netz: 8088/
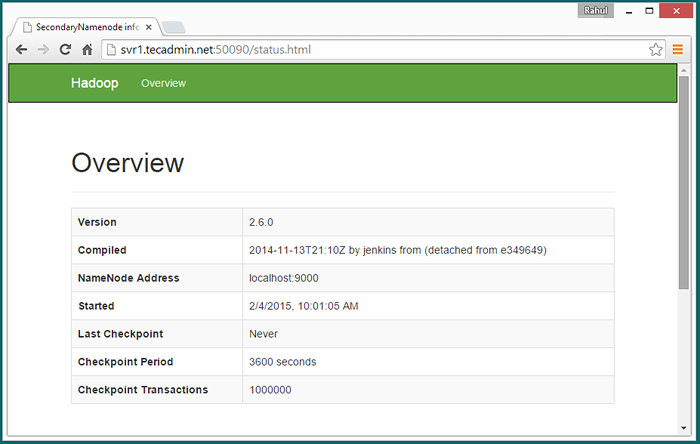
Zugriff auf Port 50090, um Details zu Secondary Namenode zu erhalten.
http: // svr1.Tecadmin.Netz: 50090/
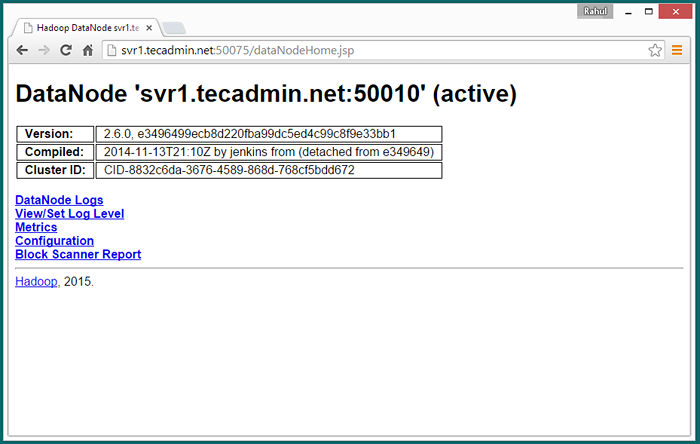
Greifen Sie auf Port 50075 zu, um Details zu Datanode zu erhalten
http: // svr1.Tecadmin.Netz: 50075/
Schritt 7. Testen Sie Hadoop Single -Knoten -Setup
7.1 - Machen Sie die HDFS -Verzeichnisse mit den folgenden Befehlen erforderlich.
$ bin/hdfs dfs -mkdir/user $ bin/hdfs dfs -mkdir/user/hadoop
7.2 - Kopieren Sie nun alle Dateien aus lokalem Dateisystem/var/log/httpd auf das verteilte Dateisystem von Hadoop unter Verwendung des folgenden Befehls
$ bin/hdfs dfs -put/var/log/httpd logs
7.3 - Durchsuchen.
http: // svr1.Tecadmin.Netz: 50070/Explorer.HTML#/user/Hadoop/Protokolle
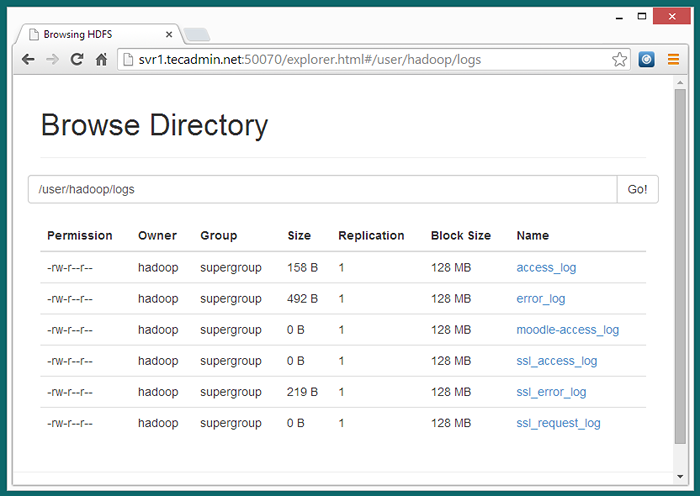
7.4 - Kopieren Sie nun das Protokoll -Verzeichnis für das Hadoop -Distributed Dateisystem in das lokale Dateisystem.
$ bin/hdfs dfs -protokolle/tmp/logs $ ls -l/tmp/logs/
Sie können dieses Tutorial auch überprüfen, um WordCount MapReduce -Beispiel mit der Befehlszeile auszuführen.
- « So entfernen Sie Leerzeichen von String in JavaScript
- So erstellen Sie die ASPState -Datenbank in SQL Server »