

Installieren Sie den Hadoop -Multinode -Cluster mit CDH4 in RHEL/Centos 6.5

- 3469
- 145
- Tom Jakobs
Hadoop ist ein Open -Source -Programmierrahmen, das von Apache entwickelt wurde, um Big Data zu verarbeiten. Es benutzt HDFS (Hadoop verteiltes Dateisystem), um die Daten über alle Datanodien im Cluster auf verteilende Weise zu speichern, und das MapReduce -Modell, um die Daten zu verarbeiten.
 Installieren Sie den Hadoop -Multinode -Cluster
Installieren Sie den Hadoop -Multinode -Cluster Namenode (Nn) ist ein Master -Daemon, der kontrolliert HDFS Und Jobtracker (JT) ist Master -Daemon für MapReduce Engine.
Anforderungen
In diesem Tutorial verwende ich zwei Centos 6.3 VMs 'Meister' Und 'Knoten'nämlich. (Master und Knoten sind meine Hostnamen). Der 'Master' IP ist 172.21.17.175 und Knoten IP ist ''172.21.17.188''. Die folgenden Anweisungen funktionieren auch Rhel/Centos 6.X Versionen.
Auf Meister
[[E -Mail geschützt] ~]# Hostname Meister
[[E -Mail geschützt] ~]# ifconfig | grep 'inet adDr' | Kopf -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 Maske: 255.255.252.0
Auf dem Knoten
[[E -Mail geschützt] ~]# Hostname Knoten
[[E -Mail geschützt] ~]# ifconfig | grep 'inet adDr' | Kopf -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 Maske: 255.255.252.0
Stellen Sie zunächst sicher, dass alle Cluster -Hosts dort sind '/etc/hosts'Datei (auf jedem Knoten), wenn Sie keine DNS einrichten haben.
Auf Meister
[[E -Mail geschützt] ~]# cat /etc /hosts 172.21.17.175 Master 172.21.17.188 Knoten
Auf dem Knoten
[[E -Mail geschützt] ~]# cat /etc /hosts 172.21.17.197 Qabox 172.21.17.176 Ansible-Ground
Installation von Hadoop -Multinoden -Cluster in CentOS
Wir verwenden offiziell CDH Repository zu installieren CDH4 auf allen Hosts (Master und Knoten) in einem Cluster.
Schritt 1: Installieren Sie die Installation CDH -Repository herunter
Gehen Sie zur offiziellen CDH -Download -Seite und schnappen Sie sich das CDH4 (i.e. 4.6) Version oder Sie können die folgenden verwenden wget Befehl zum Herunterladen des Repositorys und der Installation.
Auf rhel/centos 32-bit
# WGet http: // Archiv.Cloudera.COM/CDH4/One-Click-Installation/Redhat/6/I386/Cloudera-CDH-4-0.i386.rpm # yum-nogpgcheck localinstall cloudera-cdh-4-0.i386.Drehzahl
Auf rhel/centos 64-bit
# WGet http: // Archiv.Cloudera.com/cdh4/ein-Klickinstall/Redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm # yum-nogpgcheck localinstall cloudera-cdh-4-0.x86_64.Drehzahl
Fügen Sie vor der Installation von Hadoop -Multinode -Cluster den Cloudera Public GPG -Schlüssel zu Ihrem Repository hinzu, indem Sie einen der folgenden Befehl gemäß Ihrer Systemarchitektur ausführen.
## auf 32-Bit-System ## # RPM -Import http: // Archiv.Cloudera.com/cdh4/redhat/6/i386/cdh/rpm-gpg-kloudera
## auf 64-Bit-System ## # RPM -Import http: // Archiv.Cloudera.com/cdh4/redhat/6/x86_64/cdh/rpm-gpg-key-cloudera
Schritt 2: Setup JobTracker & Namenode Setup
Führen Sie als nächstes den folgenden Befehl aus, um JobTracker und Namenode auf dem Master Server zu installieren und einzusetzen.
[[E-Mail geschützt] ~]# yum reinigen alle [[E-Mail geschützt] ~]# yum Installation Hadoop-0.20-Mapreduce-Jobtracker
[[E-Mail geschützt] ~]# yum reinigen alle [[E-Mail geschützt] ~]# yum Installieren Sie Hadoop-hdfs-namenode
Schritt 3: Setup Secondary Name Node einrichten
Führen Sie erneut die folgenden Befehle auf dem Master -Server aus, um den Sekundärnamenknoten einzurichten.
[[E-Mail geschützt] ~]# yum reinigen alle [[E-Mail geschützt] ~]# Yum Installation Hadoop-HDFS-Sekundarynam
Schritt 4: Setup TaskTracker & Datanode einstellen
Als nächstes Setup TaskTracker & Datanode auf allen Cluster -Hosts (Knoten) mit Ausnahme der Jobtracker-, Namenode- und Sekundär- (oder Standby) -Namenode -Hosts (in diesem Fall auf Knoten).
[[E-Mail geschützt] ~]# yum reinigen alle [[E-Mail geschützt] ~]# yum Installation Hadoop-0.20-Mapreduce-Tasktracker Hadoop-HDFS-Datenanode
Schritt 5: Setup Hadoop Client einrichten
Sie können den Hadoop -Client auf einem separaten Computer installieren (in diesem Fall habe ich ihn auf Datanode installiert, Sie können ihn auf jedem Computer installieren).
[[E-Mail geschützt] ~]# Yum Installation Hadoop-Client
Schritt 6: HDFS auf Knoten einsetzen
Wenn wir nun mit oben genannten Schritten ausgeschlossen sind, gehen wir vorwärts, um HDFs bereitzustellen (um an allen Knoten durchgeführt zu werden).
Kopieren Sie die Standardkonfiguration nach /etc/hadoop Verzeichnis (auf jedem Knoten im Cluster).
[[E -Mail geschützt] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
[[E -Mail geschützt] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
Verwenden Alternativen Befehl zum Festlegen Ihres benutzerdefinierten Verzeichnisses wie folgt (auf jedem Knoten im Cluster).
[[E-Mail geschützt] ~]# Alternativen --verbose-installieren/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 Reading/var/lib/alternatives/hadoop-conf [[E-Mail geschützt] ~]# Alternativen-set hadoop-conf/etc/hadoop/conf.my_cluster
[[E-Mail geschützt] ~]# Alternativen --verbose-installieren/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 Reading/var/lib/alternatives/hadoop-conf [[E-Mail geschützt] ~]# Alternativen-set hadoop-conf/etc/hadoop/conf.my_cluster
Schritt 7: Konfigurationsdateien anpassen
Jetzt offen 'Kernstelle.xml'Datei und Aktualisierung'fs.Standard”Auf jedem Knoten im Cluster.
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/core-Site.xml
fs.Standard HDFS: // Master/
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/core-Site.xml
fs.Standard HDFS: // Master/
Nächstes Update “DFS.Berechtigungen.Superusergroup" In HDFS-Site.xml auf jedem Knoten im Cluster.
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/HDFS-Site.xml
DFS.Name.Dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name DFS.Berechtigungen.Superusergroup Hadoop
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/HDFS-Site.xml
DFS.Name.Dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name DFS.Berechtigungen.Superusergroup Hadoop
Notiz: Bitte stellen Sie sicher, dass die obige Konfiguration auf allen Knoten vorhanden ist (auf einem Knoten und ausführen scp auf den Rest der Knoten kopieren).
Schritt 8: Konfigurieren lokaler Speicherverzeichnisse
Aktualisieren Sie „DFS.Name.Dir oder DFS.Namenode.Name.Dir ”in 'HDFS-Site.XML 'auf dem Namenode (auf Master und Knoten). Bitte ändern Sie den Wert als hervorgehoben.
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/HDFS-Site.xml
DFS.Namenode.Name.Dir Datei: /// Data/1/dfs/nn,/nfsmount/dfs/nn
[[E-Mail geschützt] conf]# cat/etc/hadoop/conf/HDFS-Site.xml
DFS.Datanode.Daten.Dir Datei: /// Data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Schritt 9: Erstellen Sie Verzeichnisse und Verwalten Sie Berechtigungen
Führen Sie die folgenden Befehle aus, um die Verzeichnisstruktur zu erstellen und Benutzerberechtigungen auf dem Maschine von Namenode (Master) und Datanode (Knoten) zu verwalten.
[[E -Mail geschützt]]# Mkdir -p/data/1/dfs/nn/nfsmount/dfs/nn [[E -Mail geschützt]]# chmod 700/data/1/dfs/nn/nfsmount/dfs/nn
[[E -Mail geschützt]]# Mkdir -p/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/dn [[E -Mail -Protected]]# Chown -R HDFS: HDFS/DATA/1/DFS/NN/NFSMOUNT/DFS/NN/DATA/1/DFS/DN/DATA/2/DFS/DN/DATA/3/DFS/DN/DATA/4/DFS/ dn
Formatieren Sie den Namenode (auf Master), indem Sie den folgenden Befehl ausgeben.
[[E -Mail geschützt] conf]# sudo -u hdfs hdfs namenode -format
Schritt 10: Konfigurieren des Sekundärnamenode
Fügen Sie der folgenden Eigenschaft zur Füge hinzu HDFS-Site.xml Datei und ersetzen Sie den Wert wie auf dem Master gezeigt.
DFS.Namenode.http-adress 172.21.17.175: 50070 Die Adresse und der Port, auf den die Namenode -Benutzeroberfläche zuhört.
Notiz: In unserem Fall sollte der Wert die IP -Adresse von Master VM sein.
Lassen Sie uns nun MRV1 einsetzen (Map-Reduce Version 1). Offen 'Mapred-Site.xml'Datei folgende Werte wie gezeigt.
[[E-Mail geschützt] conf]# CP HDFS-Site.XML Mapred-Site.XML [[E-Mail geschützt] conf]# vi Mapred-Site.XML [[E-Mail geschützt] conf]# Cat Mapred-Site.xml
Mapred.Arbeit.Tracker Master: 8021
Als nächstes kopieren Sie 'Mapred-Site.xml'Datei zum Knotenmaschine mit dem folgenden SCP -Befehl.
[[E-Mail geschützt] conf]# scp/etc/hadoop/conf/mapred-site.XML-Knoten:/etc/hadoop/conf/Mapred-Site.XML 100% 200 0.2kb/s 00:00
Konfigurieren Sie nun lokale Speicherverzeichnisse für MRV1 -Daemons, um sie zu verwenden. Wieder öffnen 'Mapred-Site.xml'Datei und Änderungen wie unten gezeigt für jeden TaskTracker.
 Mapred.lokal.Dir â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Nach Angabe dieser Verzeichnisse in der '' 'Mapred-Site.xml'Datei, Sie müssen die Verzeichnisse erstellen und ihnen auf jedem Knoten in Ihrem Cluster die richtigen Dateiberechtigungen zuweisen.
mkdir -p/data/1/mapred/local/data/2/mapred/local/data/3/mapred/local/daten/4/mapred/local chown -r mapred: hadoop/daten/1/mapred/local/local/ Daten/2/Mapred/Lokal/Daten/3/Mapred/Lokal/Daten/4/Mapred/Lokal
Schritt 10: HDFS starten
Führen Sie nun den folgenden Befehl aus, um HDFs auf jedem Knoten im Cluster zu starten.
[[E -Mail geschützt] conf]# für x in 'cd /etc /init.D ; ls hadoop-hdfs-*'; Sudo Service $ x Start; Erledigt
[[E -Mail geschützt] conf]# für x in 'cd /etc /init.D ; ls hadoop-hdfs-*'; Sudo Service $ x Start; Erledigt
Schritt 11: Erstellen Sie HDFS /TMP- und MapReduce /VAR -Verzeichnisse
Es ist zu erstellen erforderlich /tmp mit ordnungsgemäßen Berechtigungen genau wie unten erwähnt.
[[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -mkdir /tmp [[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -chmod -r 1777 /tmp
[[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -mkdir -p/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -chmod 1777/var/lib/hadoop -hdfs/cache/mapred/mapred/staging [[E -Mail geschützt] conf]
Überprüfen Sie nun die HDFS -Dateistruktur.
[[E-Mail geschützt] ode conf]# sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt-hdfs hadoop 0 2014-05-29 09:58 / TMP DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09 09 09 09 09 09 : 59 /var drwxr-xr-x-HDFS Hadoop 0 2014-05-29 09:59 /var /lib DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59 /var /lib /hadoop-hdfs DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache drwxr-xr-x-Mapred Hadoop 0 2014-05-29 09:59/var/lib/hadoop -HDFS/Cache/Mapred Drwxr-XR-X-Mapred Hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache/mapred/mapred drwxrwxrwt-Mapred Hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging
Nachdem Sie HDFs gestartet haben und erstellen '/tmp', aber bevor Sie mit dem JobTracker beginnen.System.Dir 'Parameter (standardmäßig $ Hadoop.TMP.Dir/Mapred/System und ändern Sie den Eigentümer in Mapred.
[[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -mkdir/tmp/mapred/system [[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -chown mapred: hadoop/tmp/mapred/system
Schritt 12: Starten Sie MapReduce
So starten Sie MapReduce: Bitte starten Sie die TT- und JT -Dienste.
Auf jedem TaskTracker -System
[[E-Mail geschützt] conf]# service Hadoop-0.20-Mapreduce-TaskTracker-Starten mit TaskTracker: [OK] Tasktracker starten, Anmelde an/var/log/hadoop-0.20-Mapreduce/Hadoop-Hadoop-Tasktracker-Knoten.aus
Auf dem JobTracker -System
[[E-Mail geschützt] conf]# service Hadoop-0.20-Mapreduce-Jobtracker Starten Sie mit JobTracker: [OK] JobTracker starten, Anmelde bei/var/log/hadoop-0.20-Mapreduce/Hadoop-Hadoop-Jobtracker-Master.aus
Erstellen Sie als nächstes ein Home -Verzeichnis für jeden Hadoop -Benutzer. Es wird empfohlen, dies auf Namenode zu tun. Zum Beispiel.
[[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -mkdirâ /user /[[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -chown /user /
Notiz: Wo ist der Linux -Benutzername jedes Benutzers.
Alternativ können Sie das Home -Verzeichnis wie folgt konschlichen.
[[E -Mail geschützt] conf]# sudo -u HDFS Hadoop fs -mkdir /user /$ user [[E -Mail geschützt] conf]# sudo -u hdfs hadoop fs -chown $ user /user /$ user
Schritt 13: Öffnen Sie JT, NN UI vom Browser
Öffnen Sie Ihren Browser und geben Sie die URL als ein http: // ip_address_of_namenode: 50070 Zu namensode zugreifen.
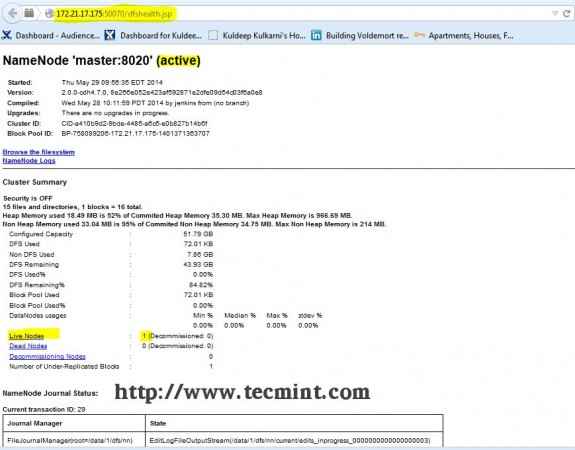 Hadoop -Namenode -Schnittstelle
Hadoop -Namenode -Schnittstelle Öffnen Sie eine andere Registerkarte in Ihrem Browser und geben Sie die URL als ein http: // ip_address_of_jobtracker: 50030 Zu Zugang zu Jobtracker.
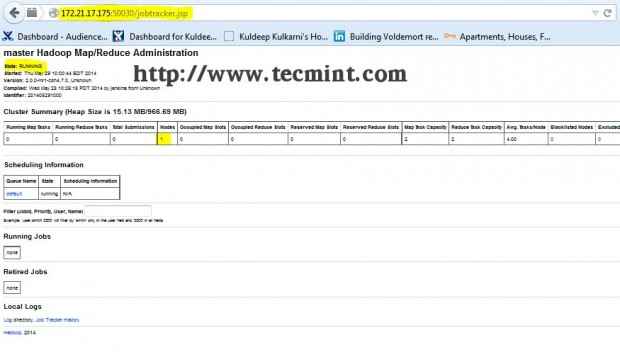 Hadoop -Karte/Verabreichung reduzieren
Hadoop -Karte/Verabreichung reduzieren Dieses Verfahren wurde erfolgreich getestet Rhel/Centos 5.X/6.X. Bitte kommentieren Sie unten, wenn Sie Probleme mit der Installation haben, werde ich Ihnen bei den Lösungen helfen.
- « Erstellen Sie Ihre eigene Video -Sharing -Website mit 'Cumulusclips -Skript' unter Linux
- Erstellen Sie virtuelle Hosts, generieren Sie SSL -Zertifikate und -tasten und aktivieren Sie das CGI -Gateway in Gentoo Linux »