

Einführung

- 4122
- 213
- Henry Liebold
31. Juli 2009
Von Pierre Vignéras
Abstrakt:
Wie Sie wahrscheinlich wissen, unterstützt Linux unter anderem verschiedene Dateisysteme wie Ext2, Ext3, Ext4, XFS, Reiserfs, JFS. Nur wenige Benutzer betrachten diesen Teil eines Systems wirklich und wählen die Standardoptionen des Installationsprogramms ihrer Verteilung aus. In diesem Artikel werde ich einige Gründe für eine bessere Berücksichtigung des Dateisystems und des Layouts angeben. Ich werde einen Top-Bottom-Prozess für das Design eines „intelligenten“ Layouts vorschlagen, das im Laufe der Zeit für eine bestimmte Computernutzung so stabil wie möglich bleibt.Einführung
Die erste Frage, die Sie vielleicht stellen, ist, warum es so viele Dateisysteme gibt und welche Unterschiede, wenn überhaupt? Um es kurz zu machen (Einzelheiten siehe Wikipedia):
- Ext2: Es ist der Linux FS, ich meine, derjenige, der speziell für Linux entwickelt wurde (beeinflusst von Ext und Berkeley FFS). Pro: schnell; Nachteile: nicht journalisiert (langes FscK).
- Ext3: Die natürliche Ext2 -Erweiterung. Pro: kompatibel mit ext2, journalisiert; Nachteile: Langsamer als ext2, wie viele Konkurrenten, die heute veraltet sind.
- EXT4: Die letzte Erweiterung der EXT -Familie. Pro: Aufstiegskompatibilität mit ext3, großer Größe; gute Leseaufführung; Nachteile: Ein bisschen zu letztes, um es zu wissen?
- JFS: IBM AIX FS auf Linux portiert. Pro: reif, schnell, leicht und zuverlässig, große Größe; Nachteile: immer noch entwickelt?
- XFS: SGI IRIX FS auf Linux portiert. Pro: Sehr reif und zuverlässig, gute durchschnittliche Leistung, große Größe, viele Tools (wie ein Defragmentierer); Nachteile: Keiner, soweit ich weiß.
- Reiserfs: Alternative zu Ext2/3-Dateisystem unter Linux. Pro: Schnell für kleine Dateien; Nachteile: immer noch entwickelt?
Es gibt andere Dateisysteme, insbesondere neue wie BTRFS, ZFS und NILFS2, die auch sehr interessant klingen können. Wir werden uns später in diesem Artikel mit ihnen befassen.
Jetzt ist die Frage: Welches Dateisystem ist für Ihre bestimmte Situation am besten geeignet? Die Antwort ist nicht einfach. Aber wenn Sie nicht wirklich wissen, wenn Sie Zweifel haben, würde ich XFS aus verschiedenen Gründen empfehlen:
- Es funktioniert sehr gut im Allgemeinen und insbesondere bei gleichzeitiger Lesen/Schreiben (siehe Benchmark);
- Es ist sehr ausgereift und wurde daher ausgiebig getestet und eingestellt;
- Vor allem ist es mit großartigen Funktionen wie XFS_FSR, einem einfach zu verwendenden Defragmentierer (einfach ein LN -SF $ (das XFS_FSR) /etc /cron durchführen.täglich/defragsieren und vergessen Sie es).
Das einzige Problem, das ich bei XFS sehe, ist, dass Sie ein XFS FS nicht reduzieren können. Sie können eine XFS-Partition selbst beim Montieren und im aktiven Gebrauch (Hot Grow) anbauen, aber Sie können ihre Größe nicht reduzieren. Wenn Sie daher ein reduzierendes Dateisystem haben, wählen Sie ein anderes Dateisystem wie Ext2/3/4 oder Reiserfs aus (soweit ich weiß, dass Sie weder ext3 noch Reiserfs Dateisysteme mit heißem Reduzieren können). Eine andere Möglichkeit besteht darin, XFs zu behalten und immer mit einer kleinen Partitionsgröße zu beginnen (da Sie immer danach heiß werden können).
Wenn Sie einen niedrig profilierten Computer (oder einen Dateiserver) haben und Ihre CPU wirklich für etwas anderes als mit Eingabe-/Ausgabebetrieb benötigen, würde ich JFS vorschlagen.
Wenn Sie viele Verzeichnisse oder/und kleine Dateien haben, ist Reiserfs möglicherweise eine Option.
Wenn Sie um jeden Preis Leistung benötigen, würde ich ext2 vorschlagen.
Ehrlich gesagt sehe ich keinen Grund für die Auswahl von Ext3/4 (Leistung? Wirklich?).
Das ist für die Auswahl des Dateisystems. Aber dann ist die andere Frage, welches Layout ich verwenden soll? Zwei Partitionen? Drei? Engagiert /zu Hause /? Schreibgeschützt /? Separat /tmp?
Offensichtlich gibt es keine einzige Antwort auf diese Frage. Viele Faktoren sollten berücksichtigt werden, um eine gute Wahl zu treffen. Ich werde zuerst diese Faktoren definieren:
- Komplexität: wie komplex das Layout weltweit ist;
- Flexibilität: wie einfach es ist, das Layout zu ändern;
- Leistung: Wie schnell das Layout ermöglicht, das System auszuführen.
Das perfekte Layout zu finden ist ein Kompromiss zwischen diesen Faktoren.
Standardlayout
Oft befolgt ein Desktop-Endbenutzer mit wenigen Kenntnissen von Linux Standardeinstellungen seiner Verteilung, wobei (normalerweise) nur zwei oder drei Partitionen für Linux durchgeführt werden, wobei das Stammdatei-System ' /', /Start und der Tausch. Vorteile einer solchen Konfiguration sind Einfachheit halber. Hauptproblem ist, dass dieses Layout weder flexibel noch leistungsfähig ist.
Mangel an Flexibilität
Mangel an Flexibilität ist aus vielen Gründen offensichtlich. Erstens, wenn der Endbenutzer ein anderes Layout möchte (z. B. die Größe des Stammdateisystems oder er möchte ein separates /TMP-Dateisystem verwenden), muss er das System neu starten und eine Partitionierungssoftware verwenden (Zum Beispiel aus einer Livecd). Er wird sich um seine Daten kümmern müssen.
Wenn der Endbenutzer einen Speicher hinzufügen möchte (z. B. eine neue Festplatte), wird er am Ende das Systemlayout (/etc/fstab) ändern, und nach einigen Zeiten hängt sein System nur vom zugrunde liegenden Speicherlayout ab (Anzahl und Ort von Festplatten, Partitionen usw.).
Wenn Sie separate Partitionen für Ihre Daten (/Home, aber auch alle Audio, Video, Datenbank,…) haben, erleichtern übrigens die Änderung des Systems erheblich (z. B. von einer Linux -Verteilung auf eine andere) erheblich. Es wird auch das Teilen von Daten zwischen Betriebssystemen (BSD, OpenSolaris, Linux und sogar Windows) einfacher und sicherer. Aber das ist eine andere Geschichte.
Eine gute Option ist die Verwendung der logischen Volumenverwaltung (LVM). LVM löst das Flexibilitätsproblem auf sehr gute Weise, wie wir sehen werden. Die gute Nachricht ist, dass die meisten modernen Verteilungen LVM unterstützen und einige standardmäßig verwenden. LVM fügt eine Abstraktionsschicht über die Hardware hinzu, die harte Abhängigkeiten zwischen dem Betriebssystem (/etc/fstab) und den zugrunde liegenden Speichergeräten (/Dev/HDA,/Dev/SDA und anderen) entfernt. Dies bedeutet, dass Sie das Layout des Speichers - Hinzufügen und Entfernen von Festplatten - ändern können, ohne Ihr System zu stören. Das Hauptproblem von LVM ist, soweit ich weiß, möglicherweise Schwierigkeiten haben, ein LVM -Volumen von anderen Betriebssystemen zu lesen.
Mangel an Leistung.
Welches Dateisystem verwendet wird (ext2/3/4, XFS, Reiserfs, JFS), ist es nicht perfekt für alle Arten von Daten und Verwendungsmustern (auch bekannt als Workload). Zum Beispiel ist bekannt, dass XFS bei der Behandlung großer Dateien wie Videodateien gut ist. Auf der anderen Seite ist bekannt, dass Reiserfs bei der Behandlung kleiner Dateien effizient ist (z. B. Konfigurationsdateien in Ihrem Home -Verzeichnis oder in /usw.). Daher ist es definitiv nicht optimal, ein Dateisystem für alle Art von Daten und Verwendung zu haben. Der einzige gute Punkt bei diesem Layout ist, dass der Kernel nicht viele verschiedene Dateisysteme unterstützen muss. Daher reduziert er die Speichermenge, die der Kernel auf sein minimales Minimum verwendet (dies gilt auch für Module). Aber wenn wir uns nicht auf eingebettete Systeme konzentrieren, betrachte ich dieses Argument als irrelevant mit heute Computern.
Wählen Sie das Richtige: Ein Ansatz von Top-Bottom
Wenn ein System entworfen wird, wird es normalerweise normalerweise im unteren bis oberen Ansatz durchgeführt: Hardware wird gemäß den Kriterien gekauft, die nicht mit ihrer Verwendung zusammenhängen. Danach wird ein Layout des Dateisystems nach dieser Hardware definiert: "Ich habe eine Festplatte, ich kann es auf diese Weise partitionieren, diese Partition wird dort erscheinen, das andere dort und so weiter.".
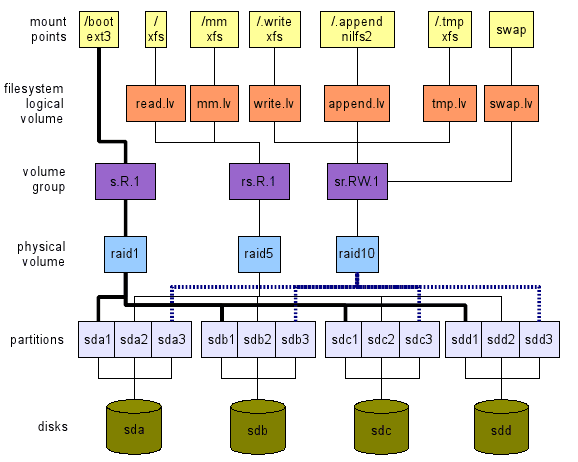
Ich schlage den umgekehrten Ansatz vor. Wir definieren, was wir auf hohem Niveau wollen. Dann reisen wir Schichten von oben nach unten, bis hin zu echten Hardware - Speichergeräten in unserem Fall - wie in Abbildung 1 gezeigt. Diese Abbildung ist nur ein Beispiel dafür, was getan werden kann. Es gibt viele Optionen, wie wir sehen werden. Die nächsten Abschnitte erklären, wie wir zu einem so globalen Layout kommen können.
Abbildung 1: Ein Beispiel für ein Dateisystemlayout. Beachten Sie, dass zwei Partitionen kostenlos bleiben (SDB3 und SDC3). Sie können für /Boot für den Tausch oder beides verwendet werden. Nicht "kopieren/einfügen" dieses Layout. Es ist nicht für Ihre Arbeitsbelastung optimiert. Es ist nur ein Beispiel.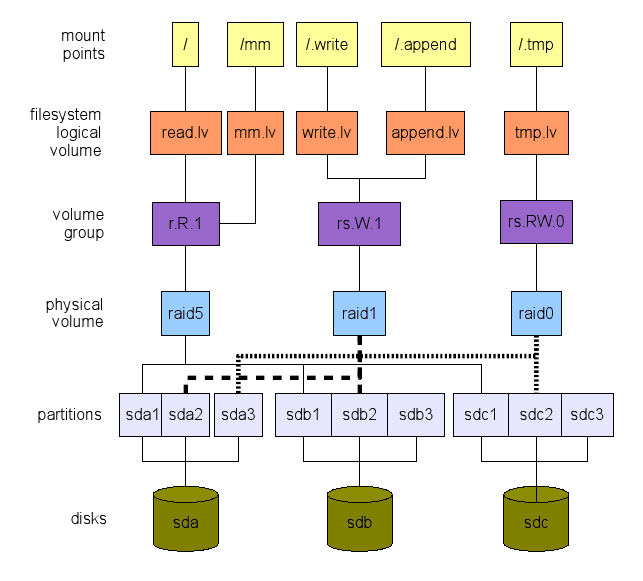
Kauf der richtigen Hardware
Vor der Installation eines neuen Systems sollte die Zielnutzung berücksichtigt werden. Zuerst aus einer Hardware -Sicht. Ist es ein eingebettetes System, ein Desktop, ein Server, ein Allzweck-Multi-Benutzer-Computer (mit TV/Audio/Video/OpenOffice/Web/Chat/P2P,…)?
Als Beispiel empfehle ich den Endbenutzern immer mit einfachen Desktop-Anforderungen (Web, Mail, Chat, wenige Medienbeobachtungen), um einen kostengünstigen Prozessor (der billigste), viel RAM (maximal) und mindestens zwei Festplatten zu kaufen.
Heutzutage ist selbst der billigste Prozessor weit genug für das Surfen und Film ansehen. Viel RAM gibt einen guten Cache (Linux verwendet kostenlosen Speicher zum Zwischenspeichern - reduziert die Menge an teurer Eingabe/Ausgabe auf Speichergeräte). Übrigens ist der Kauf der maximalen Menge an RAM, die Ihr Motherboard unterstützen kann, aus zwei Gründen eine Investition:
- Anwendungen erfordern in der Regel immer mehr Speicher. Daher verhindern Sie, dass Sie die maximale Speichermenge bereits für eine Weile später hinzufügen
- Die Technologie ändert sich so schnell, dass Ihr System den Speicher in 5 Jahren möglicherweise nicht unterstützt. Zu dieser Zeit wird der Kauf des alten Speichers wahrscheinlich ziemlich teuer sein.
Wenn Sie zwei Festplatten haben, können sie im Spiegel verwendet werden. Wenn man fehlschlägt, funktioniert das System daher weiterhin normal und Sie haben Zeit, eine neue Festplatte zu erhalten. Auf diese Weise bleibt Ihr System verfügbar und Ihre Daten sind ziemlich sicher (dies ist nicht ausreichend, um Ihre Daten auch zu sichern).
Verwendungsmuster definieren
Bei der Auswahl von Hardware und insbesondere beim Layout des Dateisystems sollten Sie Anwendungen in Betracht ziehen, die es verwenden. Unterschiedliche Anwendungen haben unterschiedliche Eingangs-/Ausgangs -Workloads. Betrachten Sie die folgenden Anwendungen: Logger (Syslog), Mail -Leser (Thunderbird, Kmail), Suchmaschine (Beagle), Datenbank (MySQL, PostgreSQL), P2P (Emule, Gnutella, Vuze), Shells (Bash)… Können Sie ihre Eingabe sehen /Ausgangsmuster und wie sehr sie sich unterscheiden?
Daher definiere ich den folgenden abstrakten Speicherort, der als logisches Volumen - LV - in der LVM -Terminologie bekannt ist:
- TMP.LV:
- Für temporäre Daten wie die in/tmp,/var/tmp und auch im Heimverzeichnis der einzelnen Benutzer $ Home/TMP (Beachten Sie, dass Müllverzeichnisse wie $ Home/Trash, $ home/.Müll kann auch hier zugeordnet werden. Bitte beachten Sie die Auswirkungen auf die Freedesktop -Müllspezifikation. Ein anderer Kandidat ist /var /cache. Die Idee für dieses logische Volumen ist, dass wir sie möglicherweise für die Leistung übergeben und etwas Datenverlust akzeptieren, da diese Daten für das System nicht unerlässlich sind (siehe LINUX-Dateisystem-Hierarchiestandard (FHS) für diese Positionen).
- lesen.LV:
- Für Daten, die meist gelesen werden, wie für die meisten Binärdateien in /bin /usr /bin /lib, /usr /lib, Konfigurationsdateien in /etc und die meisten Konfigurationsdateien in jedem Benutzerverzeichnis $ HOME /.bashrc und so weiter. Dieser Speicherort kann für Lesedurchführungen abgestimmt werden. Wir können schlechte Schreibleistung akzeptieren, da sie in seltenen Fällen auftreten (e.G: Beim Upgrade des Systems). Daten hier zu verlieren ist eindeutig inakzeptabel.
- schreiben.LV:
- Für Daten, die hauptsächlich zufällig geschrieben werden, z. B. Daten, die von P2P -Anwendungen oder Datenbanken verfasst wurden. Wir können es für Schreibleistung einstellen. Beachten Sie, dass die Leseleistung nicht zu niedrig sein kann: Sowohl P2P- als auch Datenbankanwendungen lesen zufällig und oft die von ihnen geschriebenen Daten. Wir können diesen Ort als den Ort „Allzweck“ betrachten: Wenn Sie das Verwendungsmuster einer bestimmten Anwendung nicht wirklich kennen, konfigurieren Sie ihn, damit diese logische Lautstärke verwendet wird. Daten hier zu verlieren ist auch inakzeptabel.
- anhängen.LV:
- Für Daten, die meist auf sequentielle Weise geschrieben sind, wie für die meisten Dateien in/var/log und auch $ home/.Xsession-Errors unter anderem. Wir können es für die Anhängenleistung einstellen, die sich möglicherweise von der zufälligen Schreibleistung unterscheiden. Dort ist die Leseleistung normalerweise nicht so wichtig (es sei denn, Sie haben natürlich spezifische Anforderungen). Daten zu verlieren, ist hier inakzeptabel für normale Verwendungen (Protokoll gibt Informationen zu Problemen. Wenn Sie Ihre Protokolle verlieren, wie können Sie wissen, was das Problem war??).
- mm.LV:
- für Multimedia -Dateien; Ihr Fall ist insofern etwas Besonderes, als sie normalerweise groß sind (Video) und nacheinander lesen. Das Tuning für sequentielle Lesen kann hier durchgeführt werden. Multimedia -Dateien werden einmal geschrieben (zum Beispiel aus dem Schreiben.LV, bei dem P2P -Anwendungen in die MM schreiben.LV) und viele Male nacheinander gelesen.
Sie können hier alle anderen Kategorien mit unterschiedlichen Mustern wie sequentiell hinzufügen/vorschlagen.lesen.LV zum Beispiel.
Definieren von Mountspunkten
Nehmen wir an, wir haben bereits all diese abstrakten Speicherorte in Form/Dev/TBD/LV, wobei:
- TBD ist eine Volumengruppe, die später definiert werden soll (siehe 3.5);
- LV ist eines der logischen Volumen, die wir gerade im vorhergehenden Abschnitt definiert haben (lesen Sie.LV, TMP.lv,…).
Wir nehmen also an, wir haben bereits/dev/tbd/tmp.lv,/dev/tbd/read.lv,/dev/tbd/write.lv und so weiter.
Übrigens sind wir der Meinung, dass jede Volumengruppe für ihr Nutzungsmuster optimiert ist (ein Kompromiss wurde zwischen Leistung und Flexibilität festgestellt).
Temporäre Daten: TMP.lv
Wir möchten/tmp,/var/tmp und alle $ home/tmp alle zu/dev/tbd/tmp zugeordnet sind.lv.
Was ich vorschlage, ist Folgendes:
- montage/dev/tbd/tmp.lv zu a /.TMP verstecktes Verzeichnis auf der Wurzelebene; In /etc /fstab werden Sie so etwas haben (natürlich, da die Volumengruppe unbekannt ist, wird dies nicht funktionieren. Der Punkt ist, den Prozess hier zu erklären.):
# Automatisch durch das reale Dateisystem ersetzen, wenn Sie möchten # Standardeinstellungen 0 2 durch Ihre eigenen Bedürfnisse (Man fstab)/dev/tbd/tmp ersetzen.lv /.TMP Auto Standards 0 2
- Binden Sie andere Orte an das Verzeichnis in /.TMP. Angenommen, es ist Ihnen nicht wichtig, separate Verzeichnisse für /tmp und /var /tmp zu haben (siehe FHS für Auswirkungen), können Sie einfach ein All_TMP -Verzeichnis in /dev /tbd /tmp erstellen.LV und binden Sie es sowohl an /tmp als auch an /var /tmp. In /etc /fstab fügen Sie diese Zeilen hinzu:
/.tmp /all_tmp /tmp keine bindend 0 0 / /.TMP/All_tmp/var/tmp keine bindend 0 0
Natürlich, wenn Sie es vorziehen, sich FHS anzupassen, kein Problem. Erstellen Sie zwei verschiedene Verzeichnisse FHS_TMP und FHS_VAR_TMP in die TMP.LV Volumen und fügen Sie diese Zeilen hinzu:
/.tmp /fhs_tmp /tmp keine bindend 0 0 /.tmp/fhs_var_tmp/var/tmp keine bindend 0 0
- Machen Sie einen Symlink für das Benutzer -TMP -Verzeichnis für das Benutzer mit /tmp /user. Zum Beispiel ist $ home/tmp ein symbolischer Link zu/tmp/$ user_name/tmp (ich verwende die KDE Verwenden Sie die gleiche LV). Sie können diesen Vorgang mit einigen Zeilen in Ihre automatisieren .bash_profile (oder sogar im/etc/skel/.Bash_profile, so dass jeder neue Benutzer es hat). Zum Beispiel:
Wenn Test ! -e $ home/tmp -a ! -E /TMP /KDE- $ User; dann MKDIR /TMP /KDE- $ User; LN -S/TMP/KDE- $ User $ HOME/TMP; fi
(Dieses Skript ist ziemlich einfach und funktioniert nur für den Fall, in dem sowohl $ home/tmp als auch/tmp/kde- $ user noch nicht vorhanden sind. Sie können es an Ihr eigenes Bedürfnis anpassen.)
Meistens lesen Daten: Lesen Sie.lv
Da das Stammdateisystem /etc, /bin, /usr /bin /so weiter enthält, sind sie perfekt zum Lesen perfekt.lv. Daher würde ich in /etc /fstab Folgendes platzieren:
/dev/tbd/read.LV / Auto -Standardeinstellungen 0 1
Für Konfigurationsdateien in User Home -Verzeichnis sind die Dinge nicht so einfach, wie Sie vielleicht erraten haben. Man kann versuchen, die Umgebungsvariable XDG_CONFIG_HOME zu verwenden (siehe FreedSktop)
Aber ich würde diese Lösung aus zwei Gründen nicht empfehlen. Erstens entspricht heutzutage nur wenige Anwendungen (Standardstandort ist $ home/.Konfiguration, wenn nicht explizit festgelegt). Zweitens, wenn Sie XDG_CONFIG_HOME auf eine Lektüre setzen.Das LV-Unter-Verzeichnis, Endbenutzer haben Schwierigkeiten, ihre Konfigurationsdateien zu finden. Daher habe ich für diesen Fall keine gute Lösung und werde Home -Verzeichnisse und alle Konfigurationsdateien erstellen, die an das allgemeine Schreiben gespeichert sind.LV -Standort.
Meistens schriftliche Daten: schreiben.lv
In diesem Fall werde ich das für TMP verwendete Muster reproduzieren.lv. Ich werde verschiedene Verzeichnisse für verschiedene Anwendungen binden. Zum Beispiel werde ich im Fstab etwas Ähnliches haben:
/dev/tbd/write.lv /.Schreiben Sie automatische Standardeinstellungen 0 2 /.Schreiben /db /db keine bindend 0 0 /.Schreiben Sie /p2p /p2p keine bindend 0 0 /.Schreiben /Zuhause /Zuhause keine binden 0 0
Dies nimmt natürlich voraus, dass DB- und P2P -Verzeichnisse in Write erstellt wurden.lv.
Beachten Sie, dass Sie sich möglicherweise über den Zugang des Rechte bewusst sein müssen. Eine Möglichkeit besteht darin, die gleichen Rechte zu liefern wie für /TMP, wo jeder seine eigenen Daten schreiben /lesen kann. Dies wird durch den folgenden Linux -Befehl erreicht, zum Beispiel: CHMOD 1777 /P2P.
Meistens Daten anhängen: Anhängen.lv
Dieses Volumen wurde für Logger -Style -Anwendungen wie Syslog (und beispielsweise seine Varianten syslog_ng) und alle anderen Logger (zum Beispiel Java -Logger) abgestimmt. Die /etc /fstab sollte dem ähnlich sein:
/dev/tbd/append.lv /.Anhängen automatische Standardeinstellungen 0 2 /.append /syslog /var /log keine bindend 0 0 /.append/uog/var/uog keine binden 0 0
Auch hier sind Syslog und ULOG -Verzeichnisse, die zuvor in Anhang erstellt wurden.lv.
Multimedia -Daten: MM.lv
Für Multimedia -Dateien füge ich einfach die folgende Zeile hinzu:
/dev/tbd/mm.LV /MM Auto Standards 0 2
In /MM erstelle ich Fotos, Audios und Videos Verzeichnisse. Als Desktop -Benutzer teile ich normalerweise meine Multimedia -Dateien mit anderen Familienmitgliedern. Daher sollten die Zugriffsrechte korrekt gestaltet werden.
Möglicherweise bevorzugen Sie unterschiedliche Bände für Foto-, Audio- und Videodateien. Fühlen Sie sich frei, logische Bände entsprechend zu erstellen: Fotos.LV, Audios.LV und Videos.lv.
Andere
Sie können Ihre eigenen logischen Volumes entsprechend Ihrem Bedarf hinzufügen. Logische Bände sind ziemlich frei zu bewältigen. Sie fügen keinen großen Overhead hinzu und bieten viel Flexibilität, um das Beste aus Ihrem System herauszuholen, insbesondere bei der Auswahl des richtigen Dateisystems für Ihre Arbeitsbelastung.
Definieren von Dateisystemen für logische Bände
Nachdem unsere Mountspunkte und unsere logischen Volumina nach unseren Anwendungsnutzungsmustern definiert wurden, können wir das Dateisystem für jedes logische Volumes auswählen. Und hier haben wir viele Möglichkeiten, wie wir bereits gesehen haben. Zuallererst haben Sie das Dateisystem selbst (e.G: ext2, ext3, ext4, Reiserfs, XFS, JFS usw.). Für jeden von ihnen haben Sie auch ihre Tuning -Parameter (z. B. Stimmblockgröße, Anzahl der Inodes, Protokolloptionen (XFS) usw.). Schließlich können Sie bei der Montage auch verschiedene Optionen gemäß einem Verwendungsmuster (Noatime, Data = Recordback (Ext3), Barriere (XFS) usw. angeben. Die Dokumentation des Dateisystems sollte gelesen und verstanden werden, damit Sie Optionen auf das richtige Verwendungsmuster zuordnen können. Wenn Sie keine Idee haben, welche FS für welchen Zweck zu verwenden ist, finden Sie hier meine Vorschläge:
- TMP.LV:
- Dieser Band enthält viele Arten von Daten, die von Anwendungen und Benutzern geschrieben/gelesen wurden, klein und groß. Ohne definierte Verwendungsmuster (meistens lesen, meistens schreiben) würde ich ein generisches Dateisystem wie XFS oder EXT4 verwenden.
- lesen.LV:
- Dieses Volumen enthält das Stammdateisystem mit vielen Binärdateien (/bin,/usr/bin), Bibliotheken (/lib,/usr/lib), vielen Konfigurationsdateien (/etc)… da die meisten seiner Daten gelesen werden, die Datei -System ist möglicherweise diejenige mit der besten Lesevorstellung, auch wenn die Schreibleistung schlecht ist. Xfs oder ext4 sind hier Optionen.
- schreiben.LV:
- Dies ist ziemlich schwierig, da dieser Ort der ist “passen alle”Ort, es sollte sowohl gelesen als auch korrekt geschrieben werden. Auch hier sind XFS oder EXT4 auch Optionen.
- anhängen.LV:
- Dort können wir ein reines strukturiertes Dateisystem wie das neue NILFS2-System, das seit 2 von Linux unterstützt wird, auswählen.6.30, die eine sehr gute Schreibleistung liefern sollte (aber hüten Sie sich vor seinen Einschränkungen (insbesondere vor der Unterstützung für Älter, erweiterte Attribute und ACL).
- mm.LV:
- Enthält Audio-/Videodateien, die ziemlich groß sein können. Dies ist eine perfekte Wahl für XFS. Beachten Sie, dass XFS auf IRIX einen Echtzeitabschnitt für Multimedia-Anwendungen unterstützt. Dies wird (noch nicht unterstützt?) unter Linux, soweit ich weiß.
- Sie können mit XFS -Tuning -Parametern spielen (siehe Man XFS), aber es erfordert einige gute Kenntnisse über Ihr Verwendungsmuster und auf XFS -Interna.
Auf dieser hohen Ebene können Sie auch entscheiden, ob Sie Verschlüsselungs- oder Komprimierungsunterstützung benötigen. Dies kann bei der Auswahl des Dateisystems helfen. Zum Beispiel für MM.LV, Komprimierung ist nutzlos (wie Multimedia -Daten bereits komprimiert sind), während sie für /zu Hause nützlich klingen kann. Überlegen Sie auch, ob Sie Verschlüsselung benötigen.
In diesem Schritt haben wir die Dateisysteme für alle unsere logischen Bände ausgewählt. Es ist jetzt Zeit, in die nächste Schicht zu gehen und unsere Volumengruppen zu definieren.
Definieren der Volumengruppe (VG)
Der nächste Schritt besteht darin, Volumengruppen zu definieren. Auf dieser Ebene werden wir unsere Bedürfnisse in Bezug auf die Leistungsstimmung und die Fehlertoleranz definieren. Ich schlage vor, VGS nach dem folgenden Schema zu definieren: [r | s].[R | w].[n] wo:
- 'R' - steht für Random;
- 'S' - steht für sequentiell;
- 'R' - steht für Read;
- 'W' - steht für Schreiben;
- 'N' - ist eine positive Ganzzahl, Null inklusive.
Buchstaben bestimmen die Art der Optimierung, auf die das benannte Volumen abgestimmt wurde. Die Zahl gibt eine abstrakte Darstellung der Fehlertoleranzstufe an. Zum Beispiel:
- R.R.0 bedeutet für zufällige Lesen mit einer Fehlertoleranzniveau von 0: Datenverlust treten auf, sobald ein Speichergerät ausfällt (ansonsten ist das System tolerant gegenüber 0 Speichergerätausfall).
- S.W.2 bedeutet optimiert für sequentielle Schreiben mit einer Fehlertoleranzniveau von 2: Datenverlust treten auf, sobald drei Speichergerät ausfallen (ansonsten ist das System tolerant gegenüber 2 Speichergeräten fehlerhaft).
Wir müssen dann jedes logische Volumen einer bestimmten Volumengruppe zuordnen. Ich schlage Folgendes vor:
- TMP.LV:
- kann einem Rs zugeordnet werden.Rw.0 Volumengruppe oder Rs.Rw.1 Abhängig von Ihren Anforderungen an Fehlertoleranz. Wenn Ihr Wunsch ist, dass Ihr System 24/24 Stunden und 365 Tage/Jahr weiterhin online bleibt, sollte die zweite Option auf jeden Fall berücksichtigt werden. Leider hat die Fehlertoleranz sowohl in Bezug auf Speicherplatz als auch die Leistung kosten. Daher sollten Sie nicht das gleiche Leistungsniveau von einem Rs erwarten.Rw.0 Vg und ein Rs.Rw.1 VG mit der gleichen Anzahl von Speichergeräten. Wenn Sie sich jedoch die Preise leisten können, gibt es Lösungen für ziemlich leistungsstarke Rs.Rw.1 und sogar Rs.Rw.2, 3 und mehr! Mehr dazu auf dem nächsten Wert.
- lesen.LV:
- kann einem r zugeordnet werden.R.1 VG (Erhöhen Sie die tolerante Zahl der Fehler, wenn Sie benötigen);
- schreiben.LV:
- kann einem r zugeordnet werden.W.1 Vg (gleiche Sache);
- anhängen.LV:
- kann einem s zugeordnet werden.W.1 Vg;
- mm.LV:
- kann einem s zugeordnet werden.R.1 Vg.
Natürlich haben wir eine "Mai" und keine "Muss" -Anweisung, da es von der Anzahl der Speichergeräte abhängt, die Sie in die Gleichung einfügen können. Das Definieren von VG ist eigentlich ziemlich schwierig, da Sie die zugrunde liegende Hardware nicht immer vollständig abstrahieren können. Ich glaube jedoch, dass die erste Definition Ihrer Anforderungen dazu beitragen kann.
Wir werden auf der nächsten Ebene sehen, wie diese Volumengruppen implementiert werden können.
DEFINIEREN SIE DEN PHYSICAL BUMES (PV)
In diesem Level implementiert Sie tatsächlich einen bestimmten Volumengruppenanforderungen (definiert unter Verwendung der Notation Rs.Rw.n oben beschrieben). Hoffentlich gibt es - soweit ich weiß - viele Möglichkeiten bei der Implementierung einer VG -Anforderung. Sie können einige LVM -Funktionen (Spiegelung, Stripping), Software -RAID (mit Linux MD) oder Hardware -RAID verwenden. Die Wahl hängt von Ihren Anforderungen und Ihrer Hardware ab. Ich würde jedoch aus zwei Gründen keine Hardware -RAID (heutzutage) für einen Desktop -Computer oder sogar einen kleinen Dateiserver empfehlen:
- Sehr oft (meiste Zeit) ist das, was als Hardware -RAID bezeichnet wird. Auf jeden Fall ist Linux Raid (MD) sowohl in Bezug auf die Leistung als auch in Bezug auf Flexibilität weitaus besser (sicher) und sicher).
- Sofern Sie keine sehr alte CPU (Pentium II -Klasse) haben, ist weicher Überfall nicht so kostspielig (dies gilt nicht so für RAID5, sondern für RAID0, RAID1 und RAID10 ist es wahr).
Wenn Sie also keine Ahnung haben, wie Sie eine bestimmte Spezifikation mit RAID implementieren sollen, finden Sie bitte eine RAID -Dokumentation.
Einige wenige Hinweise jedoch:
- alles mit a .0 kann RAID0 zugeordnet werden, was die leistungsstärkste RAID -Kombination ist (aber wenn ein Speichergerät ausfällt, verlieren Sie alles).
- S.R.1, r.R.1 und sr.R.1 kann in der Reihenfolge der Vorlieben auf RAID10 (mindestens 4 Speichergeräte (SD)), RAID5 (3 SD erforderlich), RAID1 (2 SD) abgebildet werden.
- S.W.1 kann in Reihenfolge der Vorlieben auf RAID10, RAID1 und RAID5 abgebildet werden.
- R.W.1, kann in der Reihenfolge der Vorlieben auf RAID10 und RAID1 abgebildet werden (RAID5 hat eine sehr schlechte Leistung in zufälligem Schreiben).
- sr.R.2 kann RAID10 (einige Möglichkeiten) und Raid6 zugeordnet werden.
Wenn Sie den Speicherplatz auf ein bestimmtes physisches Volumen abbilden, fügen Sie nicht zwei Speicherplätze aus demselben Speichergerät an (i.e. Partitionen). Sie verlieren sowohl Vorteile von Leistung als auch Fehlertoleranz! Zum Beispiel ist es ziemlich nutzlos, ein Teil des gleichen RAID1 -physikalischen Volumens zu machen /dev /sda1 und /dev /sda2 Teil desselben RAID1.
Wenn Sie sich nicht sicher sind, was Sie zwischen LVM und MDADM wählen möchten, würde ich vorschlagen, dass MDADM etwas flexibler ist (es unterstützt RAID0, 1, 5 und 10, während LVM nur Striping (ähnlich wie RAID0) und Spiegelung unterstützt (Ähnlich wie RAID1)).
Auch wenn Sie MDADM ausschließlich erforderlich sind, erhalten Sie wahrscheinlich eine Eins-zu-Eins-Zuordnung zwischen VGS und PVS. Ansonsten können Sie viele PVs einem VG abbilden. Aber das ist meiner bescheidenen Meinung nach ein bisschen nutzlos. MDADM bietet alle Flexibilität, die bei der Zuordnung von Partitionen/Speichergeräten in VG -Implementierungen erforderlich ist.
Partitionen definieren
Schließlich möchten Sie möglicherweise einige Partitionen aus Ihren verschiedenen Speichergeräten machen, um Ihre PV -Anforderungen zu erfüllen (z. B. erfordert RAID5 mindestens 3 verschiedene Speicherplätze). Beachten Sie, dass Ihre Partitionen in den meisten Fällen gleich groß sein müssen.
Wenn Sie können, würde ich vorschlagen, direkt Speichergeräte zu verwenden (oder nur eine einzige Partition aus einer Festplatte herauszuarbeiten). Es kann jedoch schwierig sein, wenn Sie kurz in Speichergeräten sind. Wenn Sie Speichergeräte in verschiedenen Größen haben, müssen Sie außerdem mindestens einen von ihnen aufteilt.
Möglicherweise müssen Sie einen Kompromiss zwischen Ihren PV-Anforderungen und Ihren verfügbaren Speichergeräten finden. Wenn Sie beispielsweise nur zwei Festplatten haben, können Sie auf jeden Fall einen RAID5 PV implementieren. Sie müssen sich nur auf eine RAID1 -Implementierung verlassen.
Beachte! 😉
/Stiefel
Wir haben in unserem Studium das /Startdateisystem nicht erwähnt, in dem der Startlader gespeichert ist. Einige würden es vorziehen, nur ein einzelnes / wo / der Start zu haben, nur ein Unterverzeichnis ist. Andere ziehen es vor, sich zu trennen / und / booten. In unserem Fall würde ich die folgende Idee vorschlagen, wenn wir LVM und MDADM verwenden:
- /boot ist ein separates Dateisystem, da einige Startlader möglicherweise Probleme mit LVM-Volumes haben
- /boot ist ein ext2- oder ext3-Dateisystem, da dieses Format von jedem Startlader gut unterstützt wird
- /Startgröße wäre eine Größe von 100 MB, da Initramfs ziemlich schwer sein können und Sie möglicherweise mehrere Kernel mit eigenen Initramfs haben
- /Boot ist kein LVM -Volumen;
- /Boot ist ein RAID1 -Volumen (erstellt mit MDADM). Dies stellt sicher, dass mindestens zwei Speichergeräte genau den gleichen Inhalt aus Kernel, Initramfs, System haben.Karte und andere Dinge, die zum Booten erforderlich sind;
- Das /Boot RAID1 -Volumen besteht aus zwei primären Partitionen, die die erste Partition auf ihren jeweiligen Festplatten sind. Dies verhindert, dass einige alte BIOs aufgrund der alten Einschränkungen von 1 GB den Startlader nicht finden.
- Der Bootloader wurde auf beiden Partitionen (Disks) installiert, sodass das System von beiden Festplatten starten kann.
- Das BIOS wurde ordnungsgemäß so konfiguriert, dass sie von jeder Festplatte aus starten.
Tausch
Swap ist auch ein Zeug, das wir bisher nicht besprochen haben. Sie haben hier viele Optionen:
- Leistung:
- Wenn Sie um jeden Preis Leistung benötigen, erstellen Sie auf jeden Fall eine Partition auf jedem Ihres Speichergeräts und verwenden Sie sie als Swap -Partition. Der Kernel wird Eingabe/Ausgabe für jede Partition gemäß seinem eigenen Bedarf ausbalancieren, was zu der besten Leistung führt. Beachten Sie, dass Sie mit Priorität spielen können, um gegebene Festplatten einige Vorlieben zu geben (z. B. kann ein schnelles Laufwerk eine höhere Priorität erhalten).
- Fehlertoleranz:
- Wenn Sie eine Fehlertoleranz benötigen, sollten Sie auf jeden Fall die Schaffung eines LVM -Swap -Volumes von einem R betrachten.Rw.1 Volumengruppe (beispielsweise durch einen RAID1- oder RAID10 PV implementiert).
- Flexibilität:
- Wenn Sie aus einigen Gründen Ihren Tausch ändern müssen, schlage ich vor, ein oder viele LVM -Swap -Volumes zu verwenden.
Zukünftige und/oder exotische Dateisysteme
Mit LVM ist es ziemlich einfach, ein neues logisches Volumen einzurichten, das aus einer Volumengruppe erstellt wurde (abhängig von dem, was Sie testen möchten und Ihre Hardware testen möchten) und sie in einigen Dateisystemen zu formatieren. LVM ist in dieser Hinsicht sehr flexibel. Fühlen Sie sich frei, Dateisysteme nach Belieben zu erstellen und zu entfernen.
In gewisser Weise werden zukünftige Dateisysteme wie ZFS, BTRFS und NILFS2 jedoch nicht perfekt zu LVM passen. Der Grund dafür ist, dass LVM zu einer klaren Trennung zwischen Anwendungs-/Benutzeranforderungen und Implementierungen dieser Anforderungen führt, wie wir gesehen haben. Auf der anderen Seite integrieren ZFS und BTRFS sowohl Anforderungen als auch Implementierung in ein Zeug. Zum Beispiel unterstützt sowohl ZFS als auch BTRFS die RAID -Ebene direkt. Das Gute ist, dass es das Erstellen des Datei-System-Layouts erleichtert. Das Schlechte ist, dass es gegen die Strategie der Trennung von Bedenken verstößt.
Daher können Sie sowohl ein XFS/LV/VG/MD1/SD A, B 1 und BTRFS/SD A, B 2 innerhalb desselben Systems. Ich würde ein solches Layout nicht empfehlen und empfehlen, ZFS oder BTRFS für alles oder gar nicht zu verwenden.
Ein weiteres Dateisystem, das interessant sein kann, ist NILFS2. Dieses strukturierte strukturierte Dateisysteme haben eine sehr gute Schreibleistung (aber vielleicht schlechte Leseleistung). Daher kann ein solches Dateisystem ein sehr guter Kandidat für das logische Volumen des Anhangs oder auf jedem logischen Volumen sein, das aus einem Rs erstellt wurde.W.n Volumengruppe.
USB -Laufwerke
Wenn Sie eine oder mehrere USB -Laufwerke in Ihrem Layout verwenden möchten, sollten Sie Folgendes finden:
- Die Bandbreite des USB V2 -Busses beträgt 480 Mbit/s (60 mbytes/s), was für die überwiegende Mehrheit der Desktop -Anwendungen ausreicht (außer vielleicht HD -Video)
- Soweit ich weiß, werden Sie kein USB -Gerät finden, das die USB V2 -Bandbreite erfüllen kann.
Daher kann es interessant sein, mehrere USB -Laufwerke (oder sogar zu kleben), um sie zu einem RAID -System zu machen, insbesondere eines RAID1 -Systems. Mit einem solchen Layout können Sie ein USB-Laufwerk eines RAID1-Arrays herausziehen und an anderer Stelle (im schreibgeschützten Modus) verwenden. Dann ziehen Sie es in Ihrem ursprünglichen RAID1 -Array und mit einem magischen MDADM -Befehl wie:
mdadm /dev /md0 -add /dev /sda1
Das Array rekonstruiert automatisch und kehrt in seinen ursprünglichen Zustand zurück. Ich würde jedoch nicht empfehlen, ein anderes RAID -Array aus dem USB -Laufwerk zu machen. Für RAID0 ist es offensichtlich: Wenn Sie ein USB -Laufwerk entfernen, verlieren Sie alle Ihre Daten! Für RAID5 bietet das USB-Laufwerk und somit die Hot-Plug-Funktion keinen Vorteil: Das USB-Laufwerk, das Sie herausgezogen haben, ist in einem RAID5-Modus nutzlos! (Gleiche Bemerkung für RAID10).
Solid State Drives
Schließlich können neue SSD -Laufwerke berücksichtigt werden, wenn Sie physische Volumina definieren. Ihre Eigenschaften sollten berücksichtigt werden:
- Sie haben eine sehr geringe Latenz (sowohl lesen als auch schreiben);
- Sie haben sehr gute zufällige Leseleistung und Fragmentierung hat keinen Einfluss auf ihre Leistung (deterministische Leistung)
- Die Anzahl der Schreibvorgänge ist begrenzt.
Daher eignen sich SSD -Laufwerke für die Implementierung von RSR#n Volumengruppen. Als Beispiel MM.LV und lesen.LV -Volumina können auf SSDs gespeichert werden, da Daten normalerweise einmal geschrieben und mehrmals gelesen werden. Dieses Verwendungsmuster ist perfekt für SSD.
Abschluss
Beim Entwerfen eines Dateisystemlayouts beginnt der Top-Bottom-Ansatz mit hohen Anforderungen. Diese Methode hat den Vorteil, dass Sie sich auf zuvor gemachte Anforderungen für ähnliche Systeme verlassen können. Nur die Implementierung wird sich ändern. Wenn Sie beispielsweise ein Desktop -System entwerfen: Sie können ein bestimmtes Layout haben (wie das in Abbildung 1). Wenn Sie ein anderes Desktop -System mit verschiedenen Speichergeräten installieren, können Sie sich auf Ihre ersten Anforderungen verlassen. Sie müssen nur die unteren Schichten anpassen: PVs und Partitionen. Daher kann die große Arbeit, das Verwendungsmuster oder die Arbeitsbelastung, die Analyse natürlich nur einmal pro System durchgeführt werden.
Im nächsten und letzten Abschnitt werde ich einige Layout -Beispiele angeben, die grob auf einige bekannte Computerverwendungen abgestimmt sind.
Layout -Beispiele
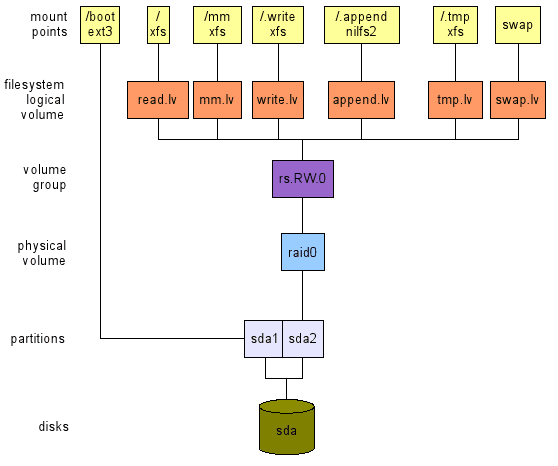
Jede Verwendung, 1 Festplatte.
Dies (siehe das obere Layout von Figur 2) ist meiner Meinung nach eine ziemlich seltsame Situation. Wie bereits gesagt, denke ich, dass ein Computer gemäß einem Verwendungsmuster dimensioniert werden sollte. Und nur eine Festplatte an Ihr System zu haben bedeutet, dass Sie einen vollständigen Ausfall von ihm annehmen. Aber ich weiß, dass die überwiegende Mehrheit der Computer heute - insbesondere Laptops und Netbooks - mit nur einer einzigen Festplatte verkauft (und entworfen) wird. Daher schlage ich das folgende Layout vor, das sich auf Flexibilität und Leistung konzentriert (so weit wie möglich):
- Flexibilität:
- Da das Layout es Ihnen ermöglicht, die Größe des Volumens nach Belieben zu ändern;
- Leistung:
- Wie Sie ein Dateisystem (ext2/3, xfs usw.) nach Datenzugriffsmustern auswählen können.
- Figur 2: Ein Layout mit einer Festplatte (oben) und einer für die Desktop -Verwendung mit zwei Scheiben (unten).
-
-
- Flexibilität:
- Da das Layout es Ihnen ermöglicht, die Größe des Volumens nach Belieben zu ändern;
- Leistung:
- Wie Sie ein Dateisystem (ext2/3, xfs usw.) nach Datenzugriffsmustern und da ein r auswählen können.R.1 VG kann von einem Raid1 -PV für eine gute zufällige Leseleistung bereitgestellt werden (im Durchschnitt). Beachten Sie jedoch, dass beide s.R.N und Rs.W.N kann nicht nur 2 Festplatten für einen Wert von n bereitgestellt werden.
- Hohe Verfügbarkeit:
- Wenn eine Festplatte ausfällt, arbeitet das System weiterhin in einem verschlechterten Modus.
- Flexibilität:
- Da das Layout es Ihnen ermöglicht, die Größe des Volumens nach Belieben zu ändern;
- Leistung:
- Wie Sie ein Dateisystem (ext2/3, xfs usw.) nach Datenzugriffsmustern auswählen können, und seit R.R.1 und Rs.Rw.0 kann dank RAID1 und RAID0 mit 2 Scheiben versehen werden.
- Mittlere Verfügbarkeit:
- Wenn eine Festplatte ausfällt, bleiben wichtige Daten zugänglich, aber das System kann nicht korrekt funktionieren, es sei denn.TMP und tauschen Sie ein anderes LV aus, der einem sicheren VG zugeordnet ist.
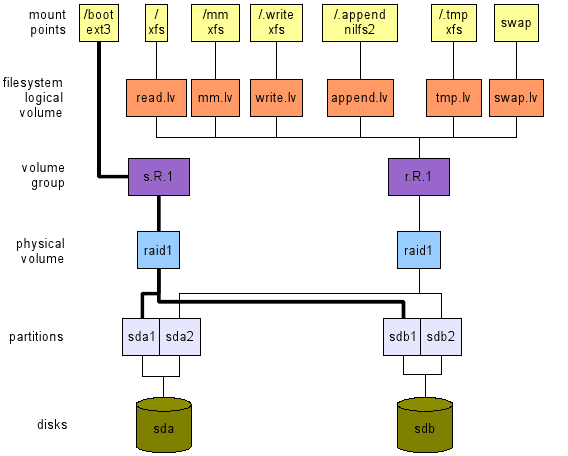
Desktop -Nutzung, hohe Verfügbarkeit, 2 Scheiben.
Hier (siehe das untere Layout von Abbildung 2) ist unser Anliegen eine hohe Verfügbarkeit. Da wir nur zwei Scheiben haben, kann nur RAID1 verwendet werden. Diese Konfiguration enthält:
Notiz: Die Swap -Region sollte sich auf dem RAID1 -PV befinden, um eine hohe Verfügbarkeit zu gewährleisten.
Desktop -Nutzung, hohe Leistung, 2 Scheiben
Hier (siehe das obere Layout von Abbildung 3) ist unser Anliegen eine hohe Leistung. Beachten Sie jedoch, dass ich immer noch für inakzeptabel halte, einige Daten zu verlieren. Dieses Layout enthält Folgendes:
- Notiz: Die Tauschregion wird aus dem Rs hergestellt.Rw.0 VG implementiert von der RAID0 PV, um Flexibilität zu gewährleisten (die Größe der Größe der Swap -Regionen ist schmerzlos). Eine weitere Option besteht darin, direkt eine vierte Partition von beiden Festplatten zu verwenden.
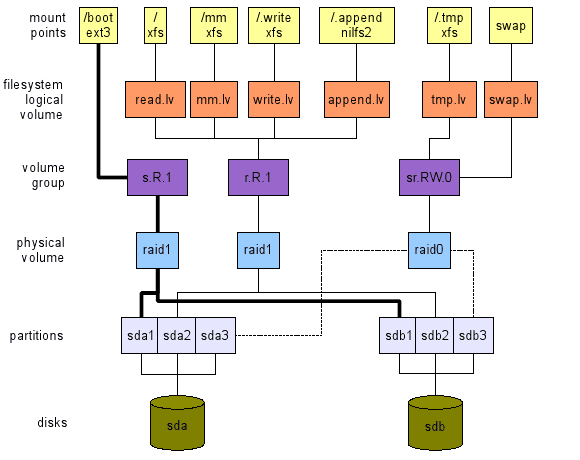
Figur 3: Oben: Layout für Hochleistungs -Desktop -Nutzung mit zwei Scheiben. Unten: Layout für Dateiserver mit vier Festplatten.
- Flexibilität:
- Da das Layout es Ihnen ermöglicht, die Größe des Volumens nach Belieben zu ändern;
- Leistung:
- Wie Sie ein Dateisystem (ext2/3, xfs usw.) nach Datenzugriffsmustern und da beide Rs auswählen können.R.1 und Rs.Rw.1 kann dank RAID5 und RAID10 mit 4 Scheiben versehen werden.
- Hohe Verfügbarkeit:
- Wenn eine Festplatte ausfällt, bleiben alle Daten zugänglich und das System kann korrekt funktionieren.
- Entweder haben Sie genügend Speicher oder/und Ihre Benutzer haben hohe zufällige/sequentielle Schreibzugriffsanforderungen. Der Raid10 PV ist die gute Option
- Oder Sie haben nicht genügend Speicherplatz oder/und Ihre Benutzer haben keine hohen zufälligen/sequentiellen Schreibzugriffsanforderungen. Der Raid5 PV ist die gute Option.
Dateiserver, 4 Festplatten.
Hier (siehe das untere Layout von Abbildung 3) ist unser Anliegen sowohl eine hohe Leistung als auch die hohe Verfügbarkeit. Dieses Layout enthält Folgendes:
Anmerkung 1:
Möglicherweise haben wir Raid10 für das gesamte System verwendet, da es eine sehr gute Implementierung von Rs bietet.Rw.1 Vg (und irgendwie auch Rs.Rw.2). Leider ist dies mit Kosten verbunden: 4 Speichergeräte sind erforderlich (hier Partitionen), jeweils die gleiche Kapazität (lass es an S = 500 Gigabyte) ist). Das physikalische Volumen von RAID10 bietet jedoch keine 4*Kapazität (2 Terabyte), wie Sie es erwarten können. Es liefert nur die Hälfte davon, 2*s (1 Terabyte). Die anderen 2*S (1 Terabyte) werden für die hohe Verfügbarkeit (Spiegel) verwendet. Einzelheiten finden Sie unter RAID -Dokumentation. Daher verwende ich RAID5 für die Implementierung von Rs.R.1. RAID5 liefert eine Kapazität von 3*(1.5 Gigabyte), die restlichen S (500 Gigabyte) werden für eine hohe Verfügbarkeit verwendet. Die mm.LV benötigt normalerweise eine große Menge Speicherplatz, da es Multimedia -Dateien enthält.
Anmerkung 2:
Wenn Sie durch NFS- oder SMB -Home -Verzeichnisse exportieren, können Sie ihren Standort sorgfältig in Betracht ziehen. Wenn Ihre Benutzer viel Platz benötigen, um Häuser auf dem Schreiben zu machen.LV (der Standort von 'Fit-All') kann speicherisch ausgerichtet sein, da er von einem Raid10-PV unterstützt wird, in dem die Hälfte des Speicherplatzes zum Spiegelung (und der Leistung) verwendet wird. Hier haben Sie zwei Optionen:
Fragen, Kommentare und Vorschläge
Wenn Sie in diesem Dokument Fragen, Kommentare und/oder Vorschläge haben, können Sie mich unter der folgenden Adresse kontaktieren: [email protected].
Urheberrechte
Dieses Dokument ist unter einem lizenziert Creative Commons Attribution-Share gleich 2.0 Frankreich Lizenz.
Haftungsausschluss
Die in diesem Dokument enthaltenen Informationen dienen nur für allgemeine Informationszwecke. Die Informationen werden von Pierre Vignéras bereitgestellt und während ich mich bemühe, die Informationen auf dem neuesten Stand zu halten und korrekt zu halten, mache ich keine Zusicherungen oder Gewährleistung jeglicher Art, ausdrücklich oder impliziert, über die Vollständigkeit, Richtigkeit, Zuverlässigkeit, Eignung oder Verfügbarkeit in Bezug Dokument oder die Informationen, Produkte, Dienstleistungen oder verwandte Grafiken, die im Dokument für einen beliebigen Zweck enthalten sind.
Jegliches Vertrauen, das Sie zu solchen Informationen stellen. In keinem Fall haften wir für Verluste oder Schäden, einschließlich ohne Einschränkung, indirekter oder Folgeverlust oder -schaden oder einem Verlust oder Schaden, der sich aus dem Verlust von Daten oder Gewinnen aus oder im Zusammenhang mit dieser Verwendung ergibt dokumentieren.
Über dieses Dokument können Sie mit anderen Dokumenten verlinken, die nicht unter der Kontrolle von Pierre Vignéras stehen. Ich habe keine Kontrolle über die Art, den Inhalt und die Verfügbarkeit dieser Websites. Die Einbeziehung von Links bedeutet nicht unbedingt eine Empfehlung oder unterstützt die in ihnen ausgedrückten Ansichten.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Linux -Konfigurationsdateien: Top 30 am wichtigsten
- Dinge zu tun nach der Installation Ubuntu 22.04 Jammy Quallen…
- So überprüfen Sie eine Festplattengesundheit aus der Befehlszeile…
- Mint 20: Besser als Ubuntu und Microsoft Windows?
- Linux -Download
- Ubuntu 20.04 Leitfaden
- Manjaro Linux Windows 10 Dual Start
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- « 101 Howto Beginnen Sie mit OpenCV und Computer Vision unter Ubuntu Linux
- VMware -Pfeilschlüsselproblem auf Ubuntu »