

Einführung in Python Web Scraping und die schöne Suppenbibliothek
- 4095
- 1167
- Aileen Dylus
Zielsetzung
Lernen, wie man Informationen aus einer HTML -Seite mit Python und der schönen Suppenbibliothek extrahiert.
Anforderungen
- Verständnis der Grundlagen von Python und objektorientiertem Programmieren
Konventionen
- # - Erfordert, dass der Befehl gegebener Linux entweder mit Root -Berechtigungen ausgeführt werden muss
direkt als Stammbenutzer oder durch Verwendung vonsudoBefehl - $ - Der Befehl Linux wird als regelmäßiger nicht privilegierter Benutzer ausgeführt
Einführung
Web Scraping ist eine Technik, die in der Extraktion von Daten von einer Website mithilfe dedizierter Software bestehen. In diesem Tutorial sehen wir, wie Sie mit Python und der schönen Suppenbibliothek ein einfaches Web -Scraping durchführen können. Wir werden verwenden Python3 Targeting auf die Homepage von Rotten Tomaten, dem berühmten Aggregator für Rezensionen und Nachrichten für Filme und Fernsehsendungen, als Informationsquelle für unsere Übung.
Installation der schönen Suppenbibliothek
Um unser Scraping durchzuführen, werden wir die schöne Suppe Python Library verwenden, deshalb müssen wir sie als erstes tun, um sie zu installieren. Die Bibliothek ist in den Repositorys aller wichtigen GNU \ Linux -Verteilungen erhältlich. Daher können wir sie mit unserem bevorzugten Paketmanager oder mithilfe verwenden Pip, Die python native Way zum Installieren von Paketen.
Wenn die Verwendung des Verteilungspaketmanagers bevorzugt wird und wir Fedora verwenden:
$ sudo dnf Installieren Sie Python3-BeautifulSoup4
Auf Debian und seinen Derivaten heißt das Paket BeautifulSoup4:
$ sudo apt-Get Installieren Sie BeautifulSoup4
Auf Archilinux können wir es über Pacman installieren:
$ sudo pacman -S Python -BeatufiluSoup4
Wenn wir verwenden wollen Pip, Stattdessen können wir einfach rennen:
$ pip3 Install -Benutzer schönerSoup4
Durch Ausführen des Befehls oben mit dem --Benutzer Flag, wir werden die neueste Version der schönen Suppenbibliothek nur für unseren Benutzer installieren, daher werden keine Root -Berechtigungen erforderlich. Natürlich können Sie sich entscheiden, PIP zu verwenden, um das Paket weltweit zu installieren, aber persönlich bevorzuge ich die Installationen pro Benutzer, wenn ich den Distributionspaket-Manager nicht benutze.
Das schöne Objekt
Beginnen wir: Das erste, was wir tun möchten, ist, ein wunderschönes Objekt zu erstellen. Der BeautifulSoup Constructor akzeptiert entweder a Saite oder ein Dateihandle als erstes Argument. Letzteres interessiert uns: Wir haben die URL der Seite, die wir kratzen möchten, deshalb werden wir die verwenden urlopen Methode der Urlib.Anfrage Bibliothek (standardmäßig installiert): Diese Methode gibt ein Datei-ähnliches Objekt zurück:
von BS4 importieren Sie BeautifulSoup aus Urllib.anfordern Sie urlopen importieren mit urlopen ('http: // www.verrottete Tomaten.com ') als Homepage: Suppe = BeautifulSoup (Homepage) Zu diesem Zeitpunkt ist unsere Suppe fertig: die Suppe Objekt repräsentiert das Dokument in seiner Gesamtheit. Wir können damit beginnen, das Navigieren zu navigieren und die Daten zu extrahieren, die wir mit den eingebauten Methoden und Eigenschaften mithilfe von Daten extrahieren möchten. Angenommen, wir möchten alle auf der Seite enthaltenen Links extrahieren: Wir wissen, dass Links durch die dargestellt werden A Tag in HTML und der tatsächliche Link ist in der enthalten href Attribut des Tags, damit wir die verwenden können finde alle Methode des Objekts, das wir gerade erstellt haben, um unsere Aufgabe zu erfüllen:
Für Link in Suppe.find_all ('a'): print (link.Get ('href')) Durch Verwendung der finde alle Methode und Angabe A Als erstes Argument, das der Name des Tags ist, haben wir nach allen Links auf der Seite gesucht. Für jeden Link haben wir dann den Wert des Werts abgerufen und gedruckt href Attribut. In BeautifulSoup werden die Attribute eines Elements in ein Wörterbuch gespeichert, weshalb es sehr einfach ist, sie abzurufen. In diesem Fall haben wir die verwendet erhalten Methode, aber wir hätten auch mit der folgenden Syntax auf den Wert des HREF -Attributs zugreifen können: Link ['href']. Das vollständige Attribute Dictionary selbst ist in der enthalten Attrs Eigenschaft des Elements. Der obige Code erzeugt das folgende Ergebnis:
[…] Https: // redaktionell.verrottete Tomaten.com/https: // redaktionell.verrottete Tomaten.com/24-frames/https: // redaktionell.verrottete Tomaten.com/binge-guide/https: // redaktionell.verrottete Tomaten.Com/Box-Office-Guru/https: // redaktionell.verrottete Tomaten.com/critics-consensus/https: // redaktionell.verrottete Tomaten.Com/Fünf-Favoriten-films/https: // redaktionell.verrottete Tomaten.com/now-streaming/https: // redaktionell.verrottete Tomaten.com/Eltern-Guidance/https: // redaktionell.verrottete Tomaten.com/rot-Carpet-Roundup/https: // redaktionell.verrottete Tomaten.com/rt-on-dvd/https: // redaktionell.verrottete Tomaten.com/thesimpsons-decade/https: // redaktionell.verrottete Tomaten.com/sub-cult/https: // redaktionell.verrottete Tomaten.com/tech-talk/https: // redaktionell.verrottete Tomaten.com/ Total-Recall/ […]
Die Liste ist viel länger: Das obige ist nur ein Auszug aus der Ausgabe, gibt Ihnen aber eine Idee. Der finde alle Methode gibt alle zurück Schild Objekte, die dem angegebenen Filter entsprechen. In unserem Fall haben wir gerade den Namen des Tags angegeben, der übereinstimmen sollte, und keine anderen Kriterien, sodass alle Links zurückgegeben werden: Wir werden in einem Moment sehen, wie wir unsere Suche weiter einschränken können.
Ein Testfall: Alle Titel "Top Box Office" abrufen
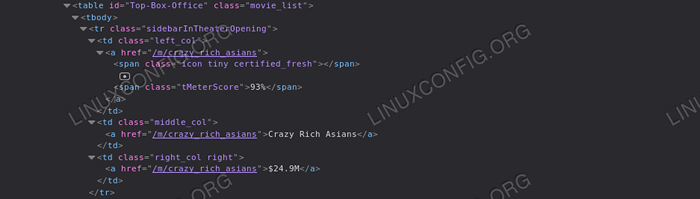
Lassen Sie uns ein eingeschränkteres Kratzen durchführen. Sagen Sie, wir möchten alle Titel der Filme abrufen, die im Abschnitt "Top Box Office" von Rotten Tomatoes Homepage erscheinen. Das erste, was wir tun möchten, ist, die Seite HTML für diesen Abschnitt zu analysieren: Wir können beobachten, dass das Element, das wir benötigen, alle in einem enthalten sind Tisch Element mit dem "Top-Box-Office" Ausweis:
Obere Abendkasse Wir können auch beobachten, dass jede Zeile der Tabelle Informationen über einen Film enthält: Die Punktzahlen des Titels sind als Text in a enthalten Spanne Element mit der Klasse „tmeterScore“ in der ersten Zelle der Zeile, während die Zeichenfolge, die den Titel des Films darstellt A Schild. Schließlich enthält die letzte Zelle einen Link mit dem Text, der die Kassenergebnisse des Films darstellt. Mit diesen Referenzen können wir problemlos alle gewünschten Daten abrufen:
von BS4 importieren Sie BeautifulSoup aus Urllib.anfordern Sie urlopen importieren mit urlopen ('https: // www.verrottete Tomaten.com ') als Homepage: Suppe = BeautifulSoup (Homepage.read (), 'html.Parser ') # Zuerst verwenden wir die Find-Methode, um die Tabelle mit' Top-Box-Office 'ID top_box_office_table = Suppe abzurufen.find ('table', 'id': 'top-box-office') # als wir über jede Zeile iterieren und Filmeinformationen für Zeile in top_box_office_table extrahieren.find_all ('tr'): cells = row.find_all ('td') title = cells [1].finde einen').get_text () endenmeld = Zellen [2].finde einen').get_text () Score = row.find ('span', 'class': 'tmetercore').get_text () print ('0 - 1 (Tomatometer: 2)'.Format (Titel, Geld, Punktzahl)) Der obige Code erzeugt das folgende Ergebnis:
Verrückte reiche Asiaten - $ 24.9m (Tomatometer: 93%) The Meg - $ 12.9m (Tomatometer: 46%) Die Happytime Morde - \ $ 9.6 m (Tomatometer: 22%) Mission: Unmöglich - Fallout - $ 8.2m (Tomatometer: 97%) Meile 22 - $ 6.5m (Tomatometer: 20%) Christopher Robin - $ 6.4m (Tomatometer: 70%) Alpha - $ 6.1m (Tomatometer: 83%) Blackkklansman - $ 5.2 m (Tomatometer: 95%) schlanker Mann - $ 2.9m (Tomatometer: 7%) a.X.L. -- $ 2.8m (Tomatometer: 29%)
Wir haben nur wenige neue Elemente eingeführt, lassen Sie uns sie sehen. Das erste, was wir getan haben, ist, die abzurufen Tisch mit der ID der Top-Box-Office-ID mit der ID finden Methode. Diese Methode funktioniert ähnlich wie finde alle, Aber während der letztere eine Liste zurückgibt, die die gefundenen Übereinstimmungen enthält, oder leer ist, wenn es keine Korrespondenz gibt, gibt die ersteren immer das erste Ergebnis oder das erste Ergebnis oder immer Keiner Wenn ein Element mit den angegebenen Kriterien nicht gefunden wird.
Das erste Element, das dem zur Verfügung gestellt wurde finden Die Methode ist der Name des Tags, der in der Suche in diesem Fall berücksichtigt werden soll Tisch. Als zweites Argument haben wir ein Wörterbuch bestanden, in dem jeder Schlüssel ein Attribut des Tags mit seinem entsprechenden Wert darstellt. Die im Wörterbuch bereitgestellten Schlüsselwertepaare stellen die Kriterien dar, die für unsere Suche nach einer Übereinstimmung erfüllt werden müssen. In diesem Fall haben wir nach dem gesucht Ausweis Attribut mit dem Wert "Top-Box-Office". Beachten Sie das seit jedem Ausweis Muss auf einer HTML -Seite eindeutig sein. Wir hätten nur den Tag -Namen weggelassen und diese alternative Syntax verwenden können:
TOP_BOX_OFFICE_TABLE = Suppe.find (id = 'Top-Box-Office') Sobald wir unseren Tisch abgerufen haben Schild Objekt haben wir die verwendet finde alle Methode, um alle Zeilen zu finden und über sie zu iterieren. Um die anderen Elemente abzurufen, haben wir dieselben Prinzipien verwendet. Wir haben auch eine neue Methode verwendet, get_text: Es gibt nur den in einem Tag enthaltenen Textteil zurück oder wenn keiner angegeben ist, auf der gesamten Seite. Zum Beispiel zu wissen, dass der Prozentsatz des Films durch den in der enthaltenen Text dargestellt wird Spanne Element mit dem tmetercore Klasse, wir haben die benutzt get_text Methode auf dem Element, um es abzurufen.
In diesem Beispiel haben wir gerade die abgerufenen Daten mit einer sehr einfachen Formatierung angezeigt, aber in einem realen Szenario wollten wir möglicherweise weitere Manipulationen ausführen oder in einer Datenbank speichern.
Schlussfolgerungen
In diesem Tutorial haben wir uns gerade an der Oberfläche dessen, was wir tun können. Die Bibliothek enthält viele Methoden, die Sie für eine raffiniertere Suche verwenden oder besser auf der Seite navigieren können: dafür empfehle ich dringend, die sehr gut geschriebenen offiziellen Dokumente zu konsultieren.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Mastering -Bash -Skriptschleifen beherrschen
- Mint 20: Besser als Ubuntu und Microsoft Windows?
- Linux -Befehle: Top 20 wichtigste Befehle, die Sie benötigen, um…
- Grundlegende Linux -Befehle
- So erstellen Sie eine Tkinter -Anwendung mithilfe eines objektorientierten…
- Ubuntu 20.04 WordPress mit Apache -Installation
- So montieren Sie das ISO -Bild unter Linux
- « Verwenden des Perl -Dolmetschers
- So verwenden Sie NCurses -Widgets in Shell -Skripten unter Linux »