

LFCS So verwenden Sie den Befehl GNU SED zum Erstellen, Bearbeiten und Manipulieren von Dateien unter Linux - Teil 1

- 2747
- 129
- Tamina Liebach
Die Linux Foundation kündigte die an LFCS (Linux Foundation Certified Sysadmin) Zertifizierung, ein neues Programm, das Einzelpersonen auf der ganzen Welt helfen soll, in Basic -to -Intermediate -System -Verwaltungsaufgaben für Linux -Systeme zertifiziert zu werden. Dies beinhaltet die Unterstützung von laufenden Systemen und Diensten sowie die Fehlerbehebung und -analyse aus erster Hand sowie intelligente Entscheidungsfindung, um Probleme zu Ingenieurteams zu Eskalieren.
 Linux Foundation Certified Sysadmin - Teil 1
Linux Foundation Certified Sysadmin - Teil 1 Bitte sehen Sie sich das folgende Video an, das das Linux Foundation -Zertifizierungsprogramm zeigt.
Die Serie trägt den Titel Vorbereitung für die LFCS (Linux Foundation Certified Sysadmin) Teile 1 durch 10 und decken Sie die folgenden Themen für Ubuntu, Centos und OpenSuse ab:
Teil 1: So verwenden Sie den Befehl "GNU" SED ", um Dateien unter Linux zu erstellen, zu bearbeiten und zu manipulieren Teil 2: So installieren und verwenden Sie VI/M als Volltexteditor Teil 3: Archivierungsdateien/Verzeichnisse und Finden von Dateien im Dateisystem Teil 4: Partitionierungspeichergeräte, Formatieren von Dateisystemen und Konfigurieren der Swap -Partition Teil 5: Mount/Unmount Local and Network (SAMBA & NFS) -Dateisysteme unter Linux Teil 6: Zusammenstellen von Partitionen als RAID -Geräte - Erstellen und Verwalten von Systemsicherungen Teil 7: Verwaltung des Systems für Systemstarts und -dienste (Sysvinit, Systemd und Upstart Teil 8: Verwalten von Benutzern und Gruppen, Dateiberechtigungen und -attributen und Aktivieren von Sudo -Zugriff auf Konten Teil 9: Linux -Paketverwaltung mit yum, rpm, apt, dpkg, fähig und zypper Teil 10: Lernen grundlegender Shell -Skript- und Dateisystem -FehlerbehebungWichtig: Aufgrund von Änderungen der LFCS -Zertifizierungsanforderungen wirksam Feb. 2, 2016, Wir geben die folgenden notwendigen Themen in die hier veröffentlichte LFCS -Serie ein. Um sich auf diese Prüfung vorzubereiten, sind Sie sehr empfohlen, auch die LFCE -Serie zu verwenden.
Teil 11: So verwalten und erstellen Teil 12: So erkunden Sie Linux mit installierten Hilfsdokumentationen und Tools Teil 13: So konfigurieren und Fehlerbehebung Grand Unified Bootloader (GRUB) Teil 14: Überwachen Sie Linux-Prozesse Ressourcennutzung und festlegen Prozessgrenzen pro Benutzerbasis Teil 15: So setzen oder modifizieren Sie Kernel -Laufzeitparameter in Linux -Systemen Teil 16: So setzen Sie Zugriffskontrolllisten (ACLs) und Festplattenquoten für Benutzer und Gruppen Teil 17: So installieren Sie Cygwin, eine Linux-ähnliche Befehlszeilenumgebung für Windows Teil 18: Eine ultimative Anleitung zum Einrichten des FTP -Servers für anonyme Anmeldungen Teil 19: Richten Sie einen grundlegenden rekursiven Caching -DNS -Server ein und konfigurieren Sie Zonen für die Domäne Teil 20: Implementierung der obligatorischen Zugriffskontrolle mit Selinux oder Apparmor unter LinuxDieser Beitrag ist Teil 1 von a 20-Tutorial-Serie, die die erforderlichen Domains und Kompetenzen abdecken, die für die benötigt werden LFCS Zertifizierungsprüfung. Abgesehen davon starten Sie Ihr Terminal und beginnen wir an.
Verarbeitungstextströme unter Linux
Linux behandelt die Eingabe und die Ausgabe aus Programmen als Streams (oder Sequenzen) von Zeichen. Um die Umleitung und Rohre zu verstehen, müssen wir zunächst die drei wichtigsten Arten von E/O -Streams (Eingabe und Ausgabe) verstehen, die tatsächlich spezielle Dateien sind (nach Konvention in UNIX und Linux, Datenströmen und Peripheriegeräte oder Gerätedateien. werden auch als gewöhnliche Dateien behandelt).
Der Unterschied zwischen > (Umleitungsoperator) und | (Pipeline -Operator) ist, dass der erste einen Befehl mit einer Datei verbindet, letztere die Ausgabe eines Befehls mit einem anderen Befehl verbindet.
# Befehl> Datei # Befehl1 | Kommando2
Da der Umleitungsoperator Dateien stillschweigend erstellt oder überschreibt, müssen wir sie mit äußerster Vorsicht verwenden und sie niemals mit einer Pipeline verwechseln. Ein Vorteil von Rohren auf Linux- und UNIX -Systemen besteht darin, dass keine Zwischendatei mit einem Rohr vorhanden ist. Der STDOut des ersten Befehls wird nicht in eine Datei geschrieben und dann durch den zweiten Befehl gelesen.
Für die folgenden Übungsübungen werden wir das Gedicht verwenden “Ein glückliches Kind”(Anonymer Autor).
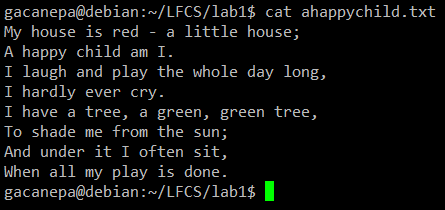 CAT -Befehlsbeispiel
CAT -Befehlsbeispiel Mit SED
Der Name sed ist kurz für den Stream -Editor. Für diejenigen, die mit dem Begriff nicht vertraut sind, wird ein Stream -Editor verwendet, um grundlegende Texttransformationen in einem Eingabestream auszuführen (eine Datei oder Eingabe aus einer Pipeline).
Die grundlegendste (und beliebteste) Verwendung von SED ist die Substitution von Charakteren. Wir werden zunächst jedes Auftreten des Kleinbuchstabens ändern y in Großbuchstaben Y und die Ausgabe an umleiten zu Ahappychild2.txt. Der G Flag zeigt an, dass SED die Substitution für alle Laufzeitfälle in jeder Dateilinie ausführen sollte. Wenn diese Flagge weggelassen wird, ersetzt SED nur das erste Ereignis der Begriff in jeder Zeile.
Grundlegende Syntax:
# sed 's/term/ersatz/flag' Datei
Unser Beispiel:
# sed 's/y/y/g' Ahappychild.txt> ahappychild2.txt
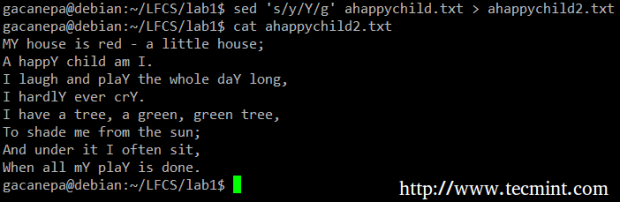 SED -Befehlsbeispiel
SED -Befehlsbeispiel Sollten Sie nach einem speziellen Charakter suchen oder ersetzen (wie z /, \, &) Sie müssen ihm in den Laufzeiten oder in den Ersatzketten mit einem rückwärts gerichteten Schrägstrich entkommen.
Zum Beispiel werden wir das Wort und für einen Verstärker ersetzen. Gleichzeitig werden wir das Wort ersetzen ICH mit Du Wenn der erste zu Beginn einer Linie gefunden wird.
# sed 's/und/\ &/g; s/^i/du/g' AhappyChild.txt
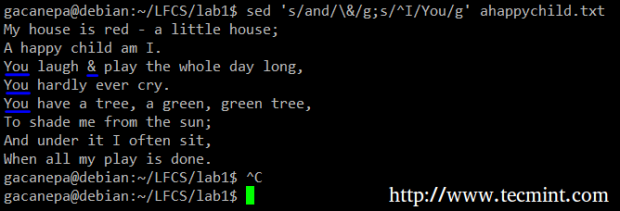 SED Ersetzen Sie die Schnur
SED Ersetzen Sie die Schnur Im obigen Befehl a ^ (Caret-Zeichen) ist ein bekannter regulärer Ausdruck, der verwendet wird, um den Beginn einer Linie darzustellen.
Wie Sie sehen können, können wir zwei oder mehr Substitutionsbefehle (und regelmäßige Ausdrücke in sich verwenden) kombinieren, indem wir sie mit einem Semikolon trennen und das Set in Einzelzitaten einschließen.
Eine weitere Verwendung von SED zeigt (oder löscht) einen ausgewählten Teil einer Datei. Im folgenden Beispiel zeigen wir die ersten 5 Zeilen von an /var/log/messages ab 8. Juni.
# sed -n '/^Jun 8/p'/var/log/message | sed -n 1,5p
Beachten Sie, dass SED standardmäßig jede Zeile druckt. Wir können dieses Verhalten mit dem überschreiben -N Option und dann SED, das drucken (angezeigt von angezeigt P) Nur der Teil der Datei (oder das Rohr), der dem Muster entspricht (8. Juni am Anfang der Linie im ersten Fall und die Zeilen 1 bis 5 im zweiten Fall).
Schließlich kann es nützlich sein, um Skripte oder Konfigurationsdateien zu inspizieren, um den Code selbst zu inspizieren und Kommentare auszulassen. Die folgenden SED-Einzeiler löscht (D) leere Zeilen oder solche, die mit beginnen # (Die | Der Charakter zeigt einen Booleschen oder zwischen den beiden regulären Ausdrücken an).
# sed '/^# \ |^$/d' Apache2.Conf
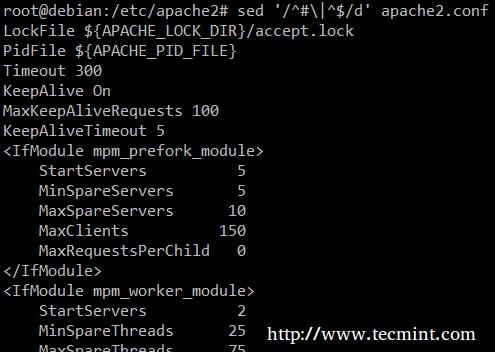 Sed Match String
Sed Match String UNIQ -Befehl
Der Uniq Mit dem Befehl können wir doppelte Zeilen in einer Datei melden oder entfernen, wobei wir standardmäßig in STDOut schreiben können. Wir müssen das beachten Uniq erkennt keine wiederholten Linien, es sei denn, sie sind benachbart. Daher, Uniq wird üblicherweise zusammen mit einem vorhergehenden verwendet Sortieren (mit der verwendet wird, um Zeilen von Textdateien zu sortieren). Standardmäßig, Sortieren Nimmt das erste Feld (durch Leerzeichen getrennt) als Schlüsselfeld. Um ein anderes Schlüsselfeld anzugeben, müssen wir die verwenden -k Möglichkeit.
Beispiele
Der du -sch/path/to/verzeichnis/* Der Befehl gibt die Nutzung des Festplattenraums pro Unterverzeichnis und Dateien innerhalb des angegebenen Verzeichnisses im menschlich-lesbaren Format zurück (zeigt auch eine Gesamtzahl pro Verzeichnis) und bestellt die Ausgabe nicht nach Größe, sondern nach Subdirektorie und Dateinamen. Wir können den folgenden Befehl verwenden, um nach Größe zu sortieren.
# du -sch /var /* | sortieren -h
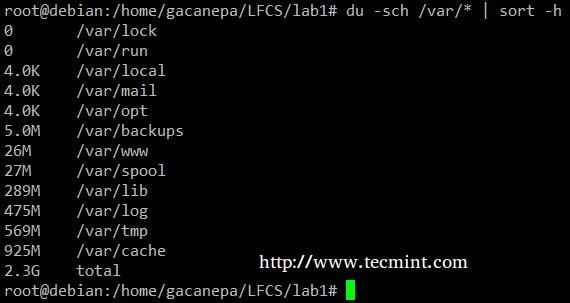 Sortieren Sie den Befehlsbeispiel
Sortieren Sie den Befehlsbeispiel Sie können die Anzahl der Ereignisse in einem Protokoll nach Erklärung zählen Uniq Um den Vergleich unter Verwendung der ersten 6 Zeichen (-W 6) jeder Zeile (wobei das Datum angegeben ist) durchzuführen, und jede Ausgangszeile durch die Anzahl der Vorkommen vorfixieren (Vorkommen-C) mit dem folgenden Befehl.
# Cat/var/log/mail.Protokoll | Uniq -c -W 6
 Zählen Sie Nummern in der Datei
Zählen Sie Nummern in der Datei Schließlich können Sie kombinieren Sortieren Und Uniq (wie normalerweise). Betrachten Sie die folgende Datei mit einer Liste von Spendern, Spendendatum und Betrag. Angenommen, wir wollen wissen, wie viele einzigartige Spender es gibt. Wir werden den folgenden Befehl verwenden, um das erste Feld zu schneiden (Felder werden durch einen Dickdarm abgegrenzt), nach Namen sortieren und doppelte Linien entfernen.
# Cat sortuniq.txt | Cut -d: -f1 | sortieren | Uniq
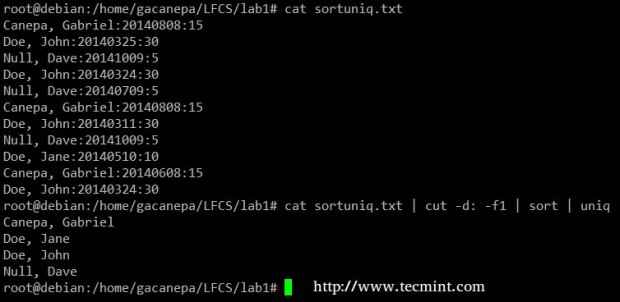 Finden Sie eindeutige Datensätze in der Datei
Finden Sie eindeutige Datensätze in der Datei Lesen Sie auch: 13 Befehlsbeispiele „Katzen“
GREP -Befehl
Grep Sucht Textdateien oder (Befehlsausgabe) zum Auftreten eines bestimmten regulären Ausdrucks und gibt jede Zeile aus, die eine Übereinstimmung mit der Standardausgabe enthält.
Beispiele
Zeigen Sie die Informationen von an /etc/passwd Für den Benutzer Gacanepa ignorieren Sie den Fall.
# Grep -i Gacanepa /etc /passwd
 Grep -Befehlsbeispiel
Grep -Befehlsbeispiel Alle Inhalte zeigen /usw deren Name beginnt mit RC gefolgt von einer einzelnen Zahl.
# ls -l /etc | Grep RC [0-9]
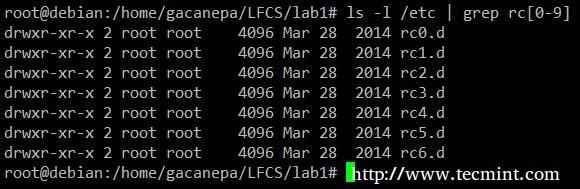 Listen Sie den Inhalt mit Grep auf
Listen Sie den Inhalt mit Grep auf Lesen Sie auch: 12 "Grep" -Befehlsbeispiele
TR -Befehlsnutzung
Der tr Der Befehl kann verwendet werden, um Zeichen aus Stdin zu übersetzen oder zu löschen und das Ergebnis an stdout zu schreiben.
Beispiele
Ändern Sie alle Kleinbuchstaben in Sortuniq in Großbuchstaben.TXT -Datei.
# Cat sortuniq.txt | TR [: unter:] [: obere:]
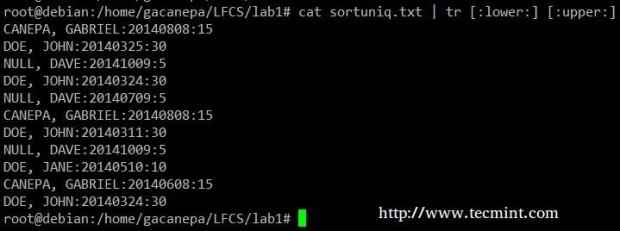 Sortieren in der Datei
Sortieren in der Datei Drücken Sie den Trennzeichen in die Ausgabe von ls -l zu nur einen Raum.
# ls -l | tr -s "
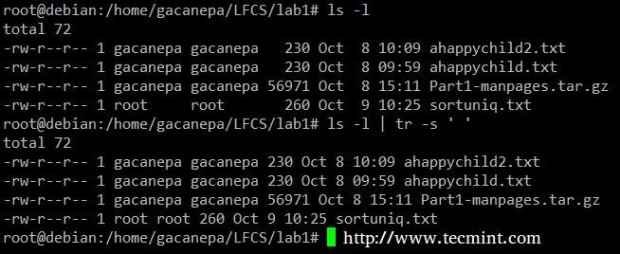 Grenzwerter drücken
Grenzwerter drücken Befehlsnutzung schneiden
Der schneiden Befehl extrahiert Teile von Eingabestellen (aus STDIN oder Dateien) und zeigt das Ergebnis in der Standardausgabe an, basierend auf der Anzahl der Bytes (-B Option), Zeichen (-C) oder Felder (-F). In diesem letzten Fall (basierend auf Feldern) ist das Standardfeldabscheider eine Registerkarte, aber ein anderer Trennzeichen kann durch die Verwendung der verwendet werden -D Möglichkeit.
Beispiele
Extrahieren Sie die Benutzerkonten und die ihnen zugewiesenen Standardschalen aus /etc/passwd (Die -D Die Option ermöglicht es uns, den Feld Grenzwert anzugeben, und die -F Der Schalter gibt an, welche Feld (en) extrahiert werden.
# CAT /ETC /PASSWD | schneiden -d: -f1,7
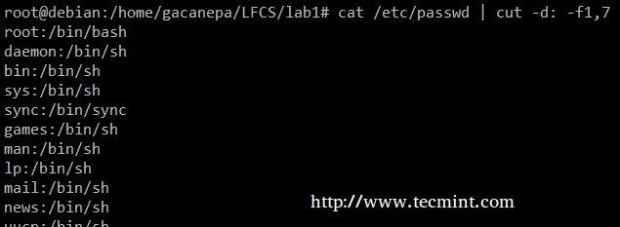 Benutzerkonten extrahieren
Benutzerkonten extrahieren Wenn wir zusammenfassen, werden wir einen Textstrom erstellen, der aus den ersten und dritten Nicht-Blank-Dateien der Ausgabe der Ausgabe besteht zuletzt Befehl. Wir werden verwenden Grep Als erster Filter, der nach Sitzungen des Benutzers prüft Gacanepa, Dann drücken Sie Graben auf nur einen Raum (tr -s")). Als nächstes extrahieren wir die ersten und dritten Felder mit schneiden, und schließlich nach dem zweiten Feld (in diesem Fall IP -Adressen) sortieren, die eindeutig angezeigt werden.
# zuletzt | Grep Gacanepa | tr -s "| cut -d" -f1,3 | sortieren -k2 | Uniq
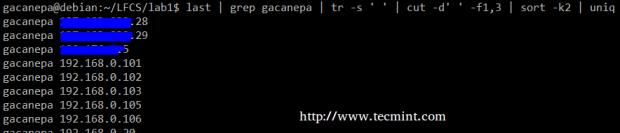 Letzter Befehlsbeispiel
Letzter Befehlsbeispiel Der obige Befehl zeigt, wie mehrere Befehle und Rohre kombiniert werden können, um gefilterte Daten gemäß unseren Wünschen zu erhalten. Fühlen Sie sich frei, es auch nach Teilen auszuführen, um Ihnen zu helfen!).
Zusammenfassung
Obwohl dieses Beispiel (zusammen mit den übrigen Beispielen im aktuellen Tutorial) auf den ersten Blick nicht sehr nützlich erscheint, sind sie ein schöner Ausgangspunkt, um mit Befehlen zu experimentieren, die zum Erstellen, Bearbeiten und Manipulieren von Dateien vom Linux verwendet werden Befehlszeile. Fühlen Sie sich frei, Ihre Fragen und Kommentare unten zu hinterlassen - sie werden sehr geschätzt sein!
Referenzlinks
- Über die LFCs
- Warum erhalten Sie eine Linux Foundation -Zertifizierung??
- Registrieren Sie sich für die LFCS -Prüfung
- « LFCS So installieren und verwenden Sie VI/VIM als Volltext -Editor - Teil 2
- WPSCAN - Ein schwarzer Box WordPress Schwachstellenscanner »