

LFCS -Überwachung Linux -Prozesse Ressourcenverbrauch und festgelegte Prozessgrenzen pro Benutzerbasis - Teil 14

- 3602
- 403
- Hr. Moritz Bozsik
Aufgrund der jüngsten Änderungen in den LFCS 2. Februar 2016, Wir fügen den hier veröffentlichten LFCS -Serie die benötigten Artikel hinzu. Um sich auf diese Prüfung vorzubereiten, werden Sie dringend ermutigt, auch die LFCE -Serie zu durchlaufen.
Überwachen Sie Linux -Prozesse und setzen Sie Prozesslimits pro Benutzer - Teil 14 Jeder Linux -Systemadministrator muss wissen, wie die Integrität und Verfügbarkeit von Hardware, Ressourcen und Schlüsselprozessen überprüft werden kann. Darüber hinaus muss das Festlegen von Ressourcenlimits auf einer Basis von Proben auch ein Teil seiner Fähigkeiten sein.
In diesem Artikel werden wir einige Möglichkeiten untersuchen, um sicherzustellen, dass das System sowohl Hardware als auch die Software korrekt verhalten, um potenzielle Probleme zu vermeiden, die unerwartete Ausfallzeiten und Geldverlust verursachen können.
Linux -Berichtsprozessoren Statistiken
Mit mpstat Sie können die Aktivitäten für jeden Prozessor einzeln oder das System als Ganzes ansehen, sowohl als einmalige Schnappschuss als auch dynamisch.
Um dieses Tool zu verwenden, müssen Sie installieren sysstat:
# yum update && yum install sysstat [on Centos basierte Systeme] # aptitutde update && aptitude install sysstat [on Ubuntu basierte Systeme] # Zypper Update && Zypper installieren sysstat [on OpenSuse Systeme]
Lesen Sie mehr über sysstat Und es sind Dienstprogramme bei Learn Sysstat und seine Dienstprogramme MPStat, Pidstat, Iostat und SAR unter Linux
Sobald Sie installiert haben mpstat, Verwenden Sie es, um Berichte von Prozessorenstatistiken zu generieren.
Zu zeigen 3 Globale Berichte der CPU -Nutzung (-u) für alle CPUs (wie angegeben von -P Alle) in einem 2-Sekunden-Intervall tun:
# MPSTAT -P All -U 2 3
Probenausgabe
Linux 3.19.0-32-generisch (Tecmint.com) Mittwoch, 30. März 2016 _X86_64_ (4 CPU) 11:41:07 IST CPU %usr %Nizza %Sys %Iowait %IRQ %Soft %stehlen %gast %gnice %idle 11:41:09 IST alle 5 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91 11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53 11:41:09 ist 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00 11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57 11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56 11:41:09 IST CPU %usr %Nizza %Sys %Iowait %IRQ %Soft %stehlen %gäste %gnice %idle.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66 11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50 11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68 11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50 11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60 11:41:11 IST CPU %usr %Nizza %Sys %Iowait %IRQ %Soft %stehlen %gäste %gnice %idle.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07 11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54 11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75 11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00 11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57 Durchschnitt: cpu %usr %nice %sys %iowait %IRQ %Soft %Steal %Gäste %IT Idle Durchschnitt: alle 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89 Durchschnitt: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87 Durchschnitt: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78 Durchschnitt: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35 Durchschnitt: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
So sehen Sie dieselben Statistiken für eine bestimmte Zentralprozessor (CPU 0 Verwenden Sie im folgenden Beispiel):
# MPSTAT -P 0 -U 2 3
Probenausgabe
Linux 3.19.0-32-generisch (Tecmint.com) Mittwoch, 30. März 2016 _X86_64_ (4 CPU) 11:42:08 IST CPU %usr %Nizza %Sys %Iowait %IRQ %Soft %stehlen %gäste %gnice %idle 11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50 11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37 11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74 Durchschnitt: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
Die Ausgabe der obigen Befehle zeigt diese Spalten an:
Zentralprozessor: Prozessornummer als Ganzzahl oder das Wort alle als Durchschnitt für alle Prozessoren.%USR: Prozentsatz der CPU -Auslastung beim Ausführen von Anwendungen auf Benutzerebene.%Hübsch: Gleich wie%USR, Aber mit einer schönen Priorität.%sys: Prozentsatz der CPU -Auslastung, die beim Ausführen von Kernelanwendungen aufgetreten ist. Dies beinhaltet keine Zeit, die mit Interrupts oder Handhabungshardware aufgewendet wird.%iowait: Prozentsatz der Zeit, in der die angegebene CPU (oder alle) im Leerlauf war, in dem eine ressourcenintensive E/A-Operation auf dieser CPU geplant war. Eine detailliertere Erklärung (mit Beispielen) finden Sie hier.%IRQ: Prozentsatz der Zeit, die für die Wartung von Hardware -Interrupts aufgewendet wurde.%weich: Gleich wie%IRQ, Aber mit Software -Interrupts.%stehlen: Prozentsatz der Zeit, die in unfreiwilligem Warten aufgewendet wird (stehlen oder gestohlen), wenn eine virtuelle Maschine als Gast die Aufmerksamkeit des Hypervisors „gewinnt“, während er um die CPU (en) kämpft. Dieser Wert sollte so klein wie möglich gehalten werden. Ein hoher Wert in diesem Bereich bedeutet, dass die virtuelle Maschine zum Stillstand kommt - oder bald wird es sein.%Gast: Prozentsatz der Zeit, die ein virtueller Prozessor ausgeführt hat.%Leerlauf: Prozentsatz der Zeit, in der CPU (en) keine Aufgaben ausführte. Wenn Sie in dieser Spalte einen niedrigen Wert beobachten, ist dies ein Hinweis darauf, dass das System unter eine schwere Belastung gelegt wird. In diesem Fall müssen Sie sich die Prozessliste genauer ansehen, wie wir in einer Minute diskutieren werden, um festzustellen, was sie verursacht.
Führen Sie die folgenden Befehle aus und führen Sie MPStat (wie angegeben) in einem separaten Terminal aus:
# dd if =/dev/null von = test.ISO BS = 1G COUNT = 1 # MPSTAT -U -P 0 2 3 # PING -F LOCALHOST # Interrupt mit Strg + C nach MPStat unten vervollständigt # mpStat -u -p 0 2 3
Schließlich vergleichen Sie mit der Ausgabe von mpstat unter normalen Umständen:
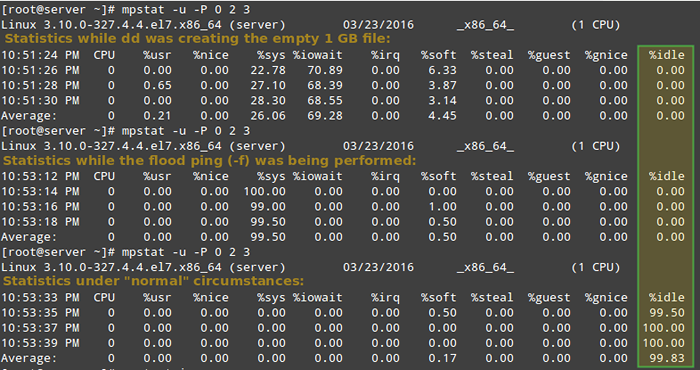 Melden Sie Linux -Prozessoren im Zusammenhang mit Statistiken
Melden Sie Linux -Prozessoren im Zusammenhang mit Statistiken Wie Sie im Bild oben sehen können, CPU 0 stand während der ersten beiden Beispiele unter einer schweren Belastung, wie durch die angegeben %Leerlauf Spalte.
Im nächsten Abschnitt werden wir erörtert, wie diese ressourcenhungrigen Prozesse identifiziert werden können, wie weitere Informationen zu ihnen erhalten werden und wie geeignete Maßnahmen ergriffen werden können.
Berichterstattung über Linux -Prozesse
Um Prozesse aufzulisten, die sie nach CPU -Nutzung sortieren, werden wir das bekannte verwenden ps Befehl mit dem -eo (Um alle Prozesse mit benutzerdefiniertem Format auszuwählen) und --Sortieren (Um eine benutzerdefinierte Sortierreihenfolge anzugeben) Optionen wie SO:
# ps -eo pid, ppid, cmd,%cpu,%mem - -sort = -%cpu
Der obige Befehl zeigt nur die an PID, Ppid, Der mit dem Prozess verbundene Befehl und den Prozentsatz der CPU- und RAM -Nutzung sortiert nach dem Prozentsatz der CPU -Verwendung in absteigender Reihenfolge. Bei der Ausführung während der Erstellung der .ISO Datei, hier sind die ersten Zeilen der Ausgabe:
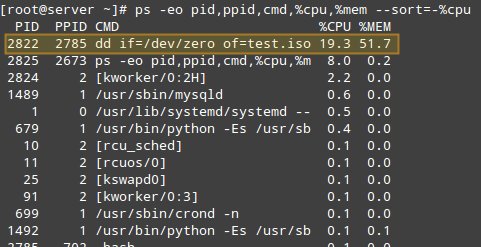 Finden Sie Linux -Prozesse nach CPU -Verwendung
Finden Sie Linux -Prozesse nach CPU -Verwendung Sobald wir einen Interessesprozess identifiziert haben (z. B. den mit PID = 2822), wir können navigieren zu /proc/pid (/proc/2822 in diesem Fall) und eine Verzeichnisauflistung durchführen.
In diesem Verzeichnis werden mehrere Dateien und Unterverzeichnisse mit detaillierten Informationen zu diesem speziellen Prozess während des Laufens aufbewahrt.
Zum Beispiel:
/proc/2822/ioEnthält IO -Statistiken für den Prozess (Anzahl der Zeichen und Bytes, die unter anderem während der IO -Operationen gelesen und geschrieben wurden)./proc/2822/attr/currentZeigt die aktuellen Selinux -Sicherheitsattribute des Prozesses an./proc/2822/cgroupBeschreibt die Kontrollgruppen (kurz CGroups), zu denen der Prozess gehört, wenn die Option config_cGroups Kernel -Konfiguration aktiviert ist, mit der Sie verifizieren können:
# Cat /Boot /Konfiguration -$ (uname -r) | grep -i cgroups
Wenn die Option aktiviert ist, sollten Sie sehen:
Config_cgroups = y
Verwendung CGROUPS Sie können die Menge an zulässigen Ressourcenverbrauch pro Prozessbasis verwalten, wie in den Kapiteln 1 bis 4 des Red Hat Enterprise Linux 7 Ressourcenmanagementhandbuchs, in Kapitel 9 des OpenSuse-Systemanalyse- und Tuning-Handbuchs sowie in den Kontrollgruppen erläutert Abschnitt der Ubuntu 14.04 Serverdokumentation.
Der /proc/2822/fd ist ein Verzeichnis, das einen symbolischen Link für jeden Dateideskriptor enthält, den der Prozess geöffnet hat. Das folgende Bild zeigt diese Informationen für den Prozess, der in TTY1 (dem ersten Terminal) gestartet wurde, um die zu erstellen .ISO Bild:
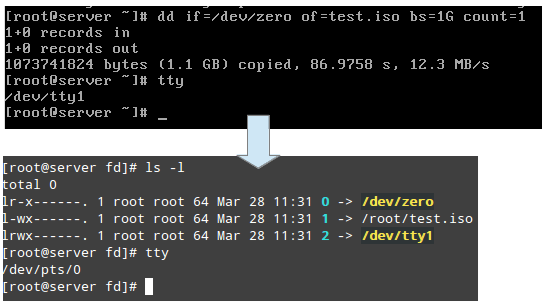 Finden Sie Linux -Prozessinformationen
Finden Sie Linux -Prozessinformationen Das obige Bild zeigt das Stdin (Dateideskriptor 0), Stdout (Dateideskriptor 1), Und Stderr (Dateideskriptor 2) werden zu kartiert /dev/null, /root/test.ISO, Und /dev/tty1, bzw.
Weitere Informationen zu /proc kann in „The gefunden werden /proc Dateisystem “Dokument, das vom Kernel aufbewahrt und gepflegt wird.Org und im Handbuch des Linux -Programmierers.
Festlegen von Ressourcenlimits auf der Basis pro Benutzer unter Linux
Wenn Sie nicht vorsichtig sind und einem Benutzer erlauben, eine unbegrenzte Anzahl von Prozessen auszuführen, können Sie irgendwann eine unerwartete Systemstillstellung erleben oder sich ausschließen, wenn das System in einen unbrauchbaren Zustand eingeht. Um dies zu verhindern, sollten Sie eine Grenze für die Anzahl der Prozesse festlegen, die Benutzer beginnen können.
Bearbeiten Sie dazu /etc/Sicherheit/Grenzen.Conf Fügen Sie die folgende Zeile am Ende der Datei hinzu, um die Grenze festzulegen:
* Hard nProc 10
Das erste Feld kann verwendet werden, um entweder einen Benutzer, eine Gruppe oder alle anzuzeigen (*), Während das zweite Feld eine harte Begrenzung der Anzahl der Prozesse (NPROC) an erzwingt 10. Um Änderungen anzuwenden, reichen Sie aus und zurück in die Anmeldung.
Lassen Sie uns also sehen, was passiert, wenn ein bestimmter Benutzer als Root (entweder ein legitimer oder nicht) versucht, eine Muschelgabelbombe zu starten. Wenn wir keine Grenzen implementiert hätten, würde dies zunächst zwei Fälle einer Funktion starten und dann jeden von ihnen in einer unendlichen Schleife duplizieren. So würde es schließlich Ihr System zu einem Kriechen bringen.
Mit der oben genannten Einschränkung ist die Gabelbombe jedoch nicht erfolgreich, aber der Benutzer wird weiterhin gesperrt, bis der Systemadministrator den damit verbundenen Prozess abtötet:
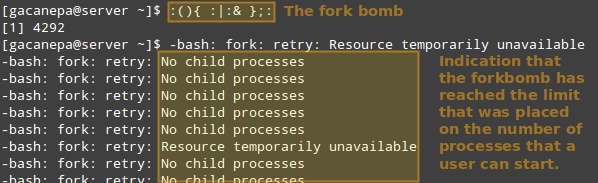 Run Shell Fork Bombe
Run Shell Fork Bombe SPITZE: Andere mögliche Einschränkungen, die durch möglich sind durch Ulimit sind in der dokumentiert Grenzen.Conf Datei.
Linux andere Prozessmanagement -Tools
Zusätzlich zu den zuvor besprochenen Tools muss ein Systemadministrator möglicherweise auch:
A) Ändern Sie die Ausführungspriorität (Verwendung von Systemressourcen) eines Prozesses mithilfe Renice. Dies bedeutet, dass der Kernel dem Prozess mehr oder weniger Systemressourcen basierend auf der zugewiesenen Priorität zuteilt (eine Zahl, die allgemein bekannt als “Nettigkeit”In einer Reichweite von -20 Zu 19).
Je niedriger der Wert ist, desto größer ist die Ausführungspriorität. Regelmäßige Benutzer (außer Root) können nur die Feinheit der Prozesse ändern, die sie zu einem höheren Wert besitzen (was eine niedrigere Ausführungspriorität), während Root diesen Wert für jeden Prozess ändern und ihn erhöhen oder verringern kann.
Die grundlegende Syntax von Renice lautet wie folgt:
# Renice [-n] Kennung
Wenn das Argument nach dem neuen Prioritätswert nicht vorhanden ist (leer), wird es standardmäßig auf PID eingestellt. In diesem Fall die Schönheit des Prozesses mit Pid = identifier ist eingestellt auf .
B) Unterbrechen Sie die normale Ausführung eines Prozesses bei Bedarf. Dies wird allgemein als „töten“ den Prozess bekannt. Dies bedeutet, dass das Verfahren ein Signal sendet.
Um einen Prozess abzutöten, verwenden Sie die töten Befehl wie folgt:
# Kill Pid
Alternativ können Sie PKILL verwenden, um alle Prozesse eines bestimmten Eigentümers zu beenden (-U), oder ein Gruppenbesitzer (-G), oder sogar die Prozesse, die einen PPID gemeinsam haben (-P). Auf diesen Optionen kann die numerische Darstellung oder der tatsächliche Name als Bezeichner folgen:
# PKILL [Optionen] Kennung
Zum Beispiel,
# PKILL -G 1000
wird alle Prozesse, die Gruppen gehören, mit töten Gid = 1000.
Und,
# PKILL -P 4993
wird alle Prozesse töten, deren PPID ist 4993.
Vor dem Laufen a Pkill, Es ist eine gute Idee, die Ergebnisse mit zu testen PGREP Erstens vielleicht die Verwendung der -l Option auch, um die Namen der Prozesse aufzulisten. Es dauert die gleichen Optionen, gibt jedoch nur die Pids von Prozessen zurück (ohne weitere Maßnahmen zu ergreifen), die getötet werden würden Pkill wird eingesetzt.
# pGrep -l -u Gacanepa
Dies ist im nächsten Bild dargestellt:
 Suchen Sie Benutzerausgangsprozesse unter Linux
Suchen Sie Benutzerausgangsprozesse unter Linux Zusammenfassung
In diesem Artikel haben wir einige Möglichkeiten zur Überwachung der Ressourcennutzung untersucht, um die Integrität und Verfügbarkeit kritischer Hardware- und Softwarekomponenten in einem Linux -System zu überprüfen.
Wir haben auch gelernt, wie man angemessene Maßnahmen ergriffen (entweder durch Anpassung der Ausführungspriorität eines bestimmten Prozesses oder durch Beendet) unter ungewöhnlichen Umständen.
Wir hoffen, dass die in diesem Tutorial erläuterten Konzepte hilfreich waren. Wenn Sie Fragen oder Kommentare haben, können Sie uns gerne mit dem folgenden Kontaktformular mit dem Kontaktformular erreichen.
Werden Sie ein Linux -zertifizierter Systemadministrator- « So ändern Sie Kernel-Laufzeitparameter auf persistente und nicht-persistente Weise
- LFCS So erkunden Sie Linux mit installierten Hilfsdokumentationen und Tools - Teil 12 »