

Linux Shell entfernen Sie doppelte Zeilen aus der Datei
- 4683
- 476
- Aileen Dylus
Bash ist eine der beliebtesten Shells und wird von vielen Linux -Benutzern verwendet. Eines der großartigen Dinge, die Sie mit Bash machen können. Es ist eine großartige Möglichkeit, eine Datei zu deklarnen und sie sauberer und organisierter aussehen zu lassen. Dies kann mit einem einfachen Befehl in der Bash -Shell erfolgen.
Alles was Sie tun müssen, ist in den Befehl einzugeben "Sortieren -u" gefolgt vom Namen der Datei. Dadurch wird die Datei erfasst und den Inhalt sortiert und dann den Befehl verwendet "Uniq" Alle Duplikate entfernen. Dies ist eine einfache und effiziente Möglichkeit, doppelte Zeilen aus Ihren Dateien zu entfernen. Wenn Sie ein Linux -Benutzer sind, ist dies ein großartiges Werkzeug in Ihrem Arsenal. Wenn Sie also das nächste Mal eine Datei aufräumen müssen, geben Sie diesen Bash -Befehl aus und sehen Sie, wie sie für Sie funktioniert!
Entfernen Sie doppelte Zeilen aus der Datei
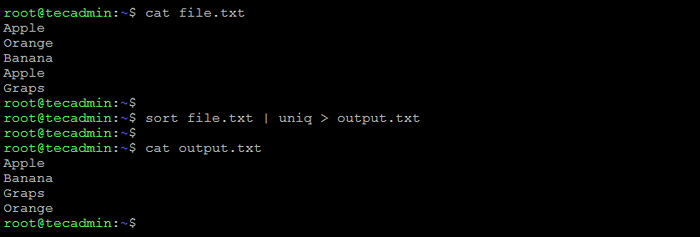
Um doppelte Zeilen aus einer Datei in Bash zu entfernen.
Hier ist ein Beispiel dafür, wie es geht:
Datei sortieren.txt | Uniq> Ausgabe.txt Dadurch wird die Zeilen sortiert in Datei.txt, Entfernen Sie die Duplikate und speichern Sie das Ergebnis in einer neuen Datei namens Output.txt.
Entfernen Sie doppelte Zeilen aus der DateiSie können auch die verwenden -u Option des Sortierbefehls, um dasselbe Ergebnis zu erzielen:
Sortieren Sie -u -Datei.txt> Ausgabe.txt Wenn Sie die Duplikate an Ort und Stelle entfernen möchten, ohne eine neue Datei zu erstellen, können Sie den Befehl tee verwenden, um die Ausgabe wieder in die Originaldatei umzuleiten:
Datei sortieren.txt | Uniq | Teedatei.txt[ODER]Sortieren Sie -u -Datei.txt | Teedatei.txt
Denken Sie daran, dass diese Befehle nur Duplikate entfernen, wenn die Zeilen genau gleich sind. Wenn Sie den führenden oder nachlaufenden weißen Raum oder Fallunterschiede ignorieren möchten, können Sie die verwenden -ich, -B, Und -F Optionen jeweils. Zum Beispiel:
Sortieren Sie -f -u -Datei.txt> Ausgabe.txt Dadurch werden Duplikate entfernt und Fallunterschiede ignoriert.
Sortieren Sie -f -b -u -Datei.txt> Ausgabe.txt Dadurch werden Duplikate entfernt, Fallunterschiede ignoriert und den weißen Raum führend/nachverfolgt.
- « So öffnen Sie den Port für ein bestimmtes Netzwerk in der Firewalld
- Konfigurieren des Nginx Reverse Proxy vor Apache »