

Entfernen Sie doppelte Zeilen aus einer Textdatei mit der Linux -Befehlszeile
- 3269
- 295
- Susanne Stoutjesdijk
Das Entfernen von doppelten Zeilen aus einer Textdatei kann aus der Befehlszeile der Linux erfolgen. Eine solche Aufgabe kann häufiger und notwendiger sein als Sie denken. Das häufigste Szenario, in dem dies hilfreich sein kann, ist bei Protokolldateien. Oft wiederholen Protokolldateien die gleichen Informationen immer wieder, wodurch die Datei fast unmöglich ist.
In diesem Handbuch werden verschiedene Befehlszeilenbeispiele angezeigt, mit denen Sie doppelte Zeilen aus einer Textdatei löschen können. Probieren Sie einige der Befehle in Ihrem eigenen System aus und verwenden Sie das, was auch immer für Ihr Szenario am bequemsten ist.
In diesem Tutorial lernen Sie:
- So entfernen Sie bei der Sortierung doppelte Zeilen aus der Datei
- So zählen Sie die Anzahl der doppelten Zeilen in einer Datei
- So entfernen Sie doppelte Zeilen, ohne die Datei zu sortieren
Verschiedene Beispiele zum Entfernen von doppelten Zeilen aus einer Textdatei unter Linux | Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Jede Linux -Distribution |
| Software | Bash Shell |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
Entfernen Sie doppelte Zeilen aus der Textdatei
Diese Beispiele funktionieren für jede Linux -Verteilung, sofern Sie die Bash -Shell verwenden.
Für unser Beispielszenario arbeiten wir mit der folgenden Datei zusammen, die nur die Namen verschiedener Linux -Verteilungen enthält. Dies ist eine sehr einfache Textdatei zum Beispiel, aber in Wirklichkeit können Sie diese Methoden für Dokumente verwenden, die sogar Tausende von Wiederholungszeilen enthalten. Wir werden sehen, wie Sie alle Duplikate aus dieser Datei mit den folgenden Beispielen entfernen können.
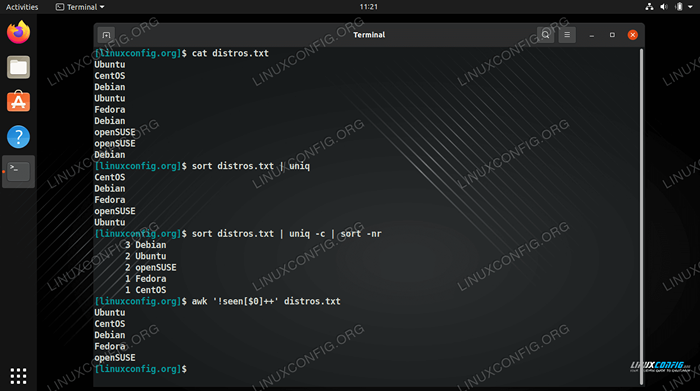
$ Cat Distribos.Txt Ubuntu Centos Debian Ubuntu Fedora Debian OpenSuse OpenSuse Debian
- Der
UniqDer Befehl ist in der Lage, alle eindeutigen Zeilen aus unserer Datei zu isolieren, dies funktioniert jedoch nur, wenn die doppelten Linien nebeneinander liegen. Damit die Linien nebeneinander sind, müssten sie zunächst in alphabetische Reihenfolge sortiert werden. Der folgende Befehl würde mit Verwendung funktionierenSortierenUndUniq.$ sortieren Distribos.txt | Uniq Centos Debian Fedora OpenSuse Ubuntu
Um die Dinge zu erleichtern, können wir das einfach verwenden
-umit Sortier, um das gleiche genaue Ergebnis zu erzielen, anstatt zu Uniq zu flächen.
$ sort -u Distribos.txt centos debian fedora opensensuse ubuntu
- Um zu sehen, wie viele Ereignisse jeder Zeile in der Datei enthalten sind, können wir die verwenden
-C(Graf) Option mit UNIQ.$ sortieren Distribos.txt | Uniq -C 1 Centos 3 Debian 1 Fedora 2 OpenSuse 2 Ubuntu
- Um die Zeilen zu sehen, die am häufigsten wiederholen, können wir mit dem einen weiteren Sortierbefehl leiten
-N(numerische Sortierung) und-RUmgekehrte Optionen. Auf diese Weise können wir schnell feststellen, welche Zeilen in der Datei am meisten dupliziert sind - eine weitere praktische Option zum Durchsuchen von Protokollen.$ sortieren Distribos.txt | Uniq -c | Sortieren -nr 3 Debian 2 Ubuntu 2 OpenSuse 1 Fedora 1 CentOS
- Ein Problem bei der Verwendung der vorherigen Befehle ist, dass wir uns darauf verlassen
Sortieren. Dies bedeutet, dass unsere endgültige Ausgabe alphabetisch sortiert oder nach Wiederholungen sortiert wird wie im vorherigen Beispiel. Dies mag manchmal eine gute Sache sein, aber was ist, wenn wir die Textdatei brauchen, um ihre vorherige Bestellung beizubehalten? Wir können doppelte Zeilen beseitigen, ohne die Datei mit der Datei zu sortierenawkBefehl in der folgenden Syntax.$ awk '!gesehen [$ 0] ++ 'Distributieren.Txt Ubuntu Centos Debian Fedora OpenSuse
Mit diesem Befehl wird das erste Ereignis einer Linie aufbewahrt, und zukünftige doppelte Linien werden aus der Ausgabe verschrottet.
- In den vorherigen Beispielen wird die Ausgabe direkt an Ihr Terminal gesendet. Wenn Sie eine neue Textdatei mit Ihren doppelten Zeilen wünschen, können Sie eines dieser Beispiele anpassen, indem Sie einfach die verwenden
>Bash -Operator wie im folgenden Befehl.$ awk '!gesehen [$ 0] ++ 'Distributieren.TXT> Distro-New.txt
Dies sollten alle Befehle sein, die Sie benötigen, um doppelte Zeilen aus einer Datei abzugeben, während Sie die Zeilen optional sortieren oder zählen. Es gibt mehr Methoden, aber diese sind am einfachsten zu verwenden und sich zu erinnern.
Gedanken schließen
In diesem Handbuch sahen wir verschiedene Befehlsbeispiele, um doppelte Zeilen aus einer Textdatei unter Linux zu entfernen. Sie können diese Befehle auf Protokolldateien oder andere Typen der Klartextdatei anwenden, die doppelte Zeilen enthält. Wir haben auch gelernt, wie man Zeilen einer Textdatei sortiert oder die Anzahl der Duplikate zahl.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- So verbessern Sie die Firefox -Schriftart unter Linux
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- Mastering -Bash -Skriptschleifen beherrschen
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Linux -Befehle: Top 20 wichtigste Befehle, die Sie benötigen, um…
- Grundlegende Linux -Befehle
- So montieren Sie das ISO -Bild unter Linux
- Linux -Konfigurationsdateien: Top 30 am wichtigsten
- RSYNC -Beispiele unter Linux
- « Grundlegende Networking -Beispiele zum Verbinden von Docker -Containern
- So konfigurieren Sie NFS unter Linux »