

Ubuntu 20.04 Hadoop

- 1337
- 294
- Miriam Bauschke
Apache Hadoop besteht aus mehreren Open -Source -Softwarepaketen, die zusammen für den verteilten Speicher und die verteilte Verarbeitung von Big Data zusammenarbeiten. Hadoop gibt vier Hauptkomponenten:
- Hadoop Common - Die verschiedenen Software -Bibliotheken, von denen Hadoop zum Laufen abhängt
- Hadoop Distributed Dateisystem (HDFS) - Ein Dateisystem, das eine effiziente Verteilung und Speicherung von Big -Data über einen Cluster von Computern ermöglicht
- Hadoop MapReduce - Wird zur Verarbeitung der Daten verwendet
- Hadoop -Garn - Eine API, die die Zuweisung von Rechenressourcen für den gesamten Cluster verwaltet
In diesem Tutorial werden wir die Schritte zur Installation von Hadoop Version 3 auf Ubuntu 20 durchlaufen.04. Auf diese Weise werden HDFs (Namenode und Datanode), Garn und MapReduce in einem im Pseudo verteilten Modus konfiguriert, der Simulation auf einem einzelnen Computer verteilt ist. Jede Komponente von Hadoop (HDFs, Garn, MapReduce) wird auf unserem Knoten als separater Java -Prozess ausgeführt.
In diesem Tutorial lernen Sie:
- So fügen Sie Benutzer für die Hadoop -Umgebung hinzu
- So installieren Sie die Java -Voraussetzung
- So konfigurieren Sie passwortlos SSH
- So installieren Sie Hadoop und konfigurieren die erforderlichen zugehörigen XML -Dateien
- So starten Sie den Hadoop -Cluster
- So greifen Sie auf Namenode und ResourceManager Web UI zu
Apache Hadoop auf Ubuntu 20.04 FOSSA FOSSA | Kategorie | Anforderungen, Konventionen oder Softwareversion verwendet |
|---|---|
| System | Installierte Ubuntu 20.04 oder verbessert Ubuntu 20.04 FOSSA FOSSA |
| Software | Apache Hadoop, Java |
| Andere | Privilegierter Zugriff auf Ihr Linux -System als Root oder über die sudo Befehl. |
| Konventionen | # - erfordert, dass gegebene Linux -Befehle mit Root -Berechtigungen entweder direkt als Stammbenutzer oder mit Verwendung von ausgeführt werden können sudo Befehl$ - Erfordert, dass die angegebenen Linux-Befehle als regelmäßiger nicht privilegierter Benutzer ausgeführt werden können |
Benutzer für Hadoop -Umgebung erstellen
Hadoop sollte ein eigenes Benutzerkonto in Ihrem System haben. Öffnen Sie zum Erstellen eines ein Terminal und geben Sie den folgenden Befehl ein. Sie werden auch aufgefordert, ein Passwort für das Konto zu erstellen.
$ sudo adduser hadoop
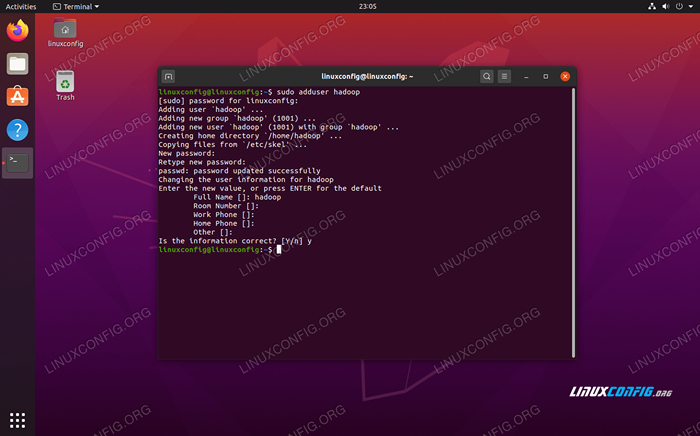 Erstellen Sie einen neuen Hadoop -Benutzer
Erstellen Sie einen neuen Hadoop -Benutzer Installieren Sie die Java -Voraussetzung
Hadoop basiert auf Java, daher müssen Sie es auf Ihrem System installieren, bevor Sie Hadoop verwenden können. Zum Zeitpunkt dieses Schreibens die aktuelle Hadoop -Version 3.1.3 erfordert Java 8, also werden wir das in unserem System installieren.
Verwenden Sie die folgenden zwei Befehle, um die neuesten Paketlisten in abzurufen geeignet und installieren Sie Java 8:
$ sudo apt update $ sudo apt install OpenJDK-8-JDK OpenJDK-8-JRE
Konfigurieren Sie passwortlos SSH
Hadoop ist auf SSH angewiesen, um auf seine Knoten zuzugreifen. Es wird über SSH und Ihre lokale Maschine eine Verbindung zu Fernmaschinen herstellen, wenn Sie Hadoop darauf laufen lassen. Obwohl wir in diesem Tutorial nur Hadoop auf unserer lokalen Maschine einrichten, müssen wir trotzdem SSH installieren lassen. Wir müssen auch passwortlose SSH konfigurieren
so dass Hadoop stillschweigend Verbindungen im Hintergrund herstellen kann.
- Wir benötigen sowohl den OpenSSH -Server als auch das OpenSSH -Clientpaket. Installieren Sie sie mit diesem Befehl:
$ sudo APT Installation OpenSSH-Server OpenSSH-Client
- Bevor Sie weiter fortgesetzt werden, ist es am besten, sich in die anzumelden
HadoopBenutzerkonto, das wir früher erstellt haben. Verwenden Sie den folgenden Befehl, um Benutzer in Ihrem aktuellen Terminal zu ändern:$ Su Hadoop
- Mit den installierten Paketen ist es an der Zeit, öffentliche und private Schlüsselpaare mit dem folgenden Befehl zu generieren. Beachten Sie, dass das Terminal Sie mehrmals auffordert, aber Sie müssen ledig
EINGEBENfortfahren.$ ssh -keygen -t RSA
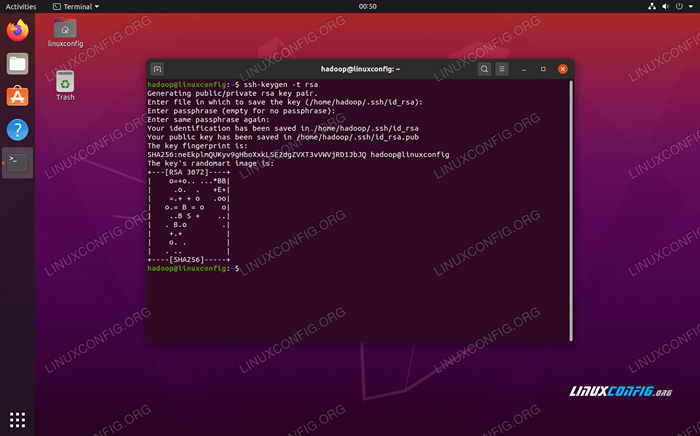 Generieren von RSA -Tasten für passwortlos SSH
Generieren von RSA -Tasten für passwortlos SSH - Kopieren Sie als nächstes den neu erzeugten RSA -Schlüssel in
id_rsa.PubnachAutorisierte_Keys:$ cat ~/.ssh/id_rsa.Pub >> ~//.ssh/autorized_keys
- Sie können sicherstellen, dass die Konfiguration durch Sshing in Localhost erfolgreich war. Wenn Sie es tun können, ohne für ein Passwort aufgefordert zu werden, können Sie loslegen.
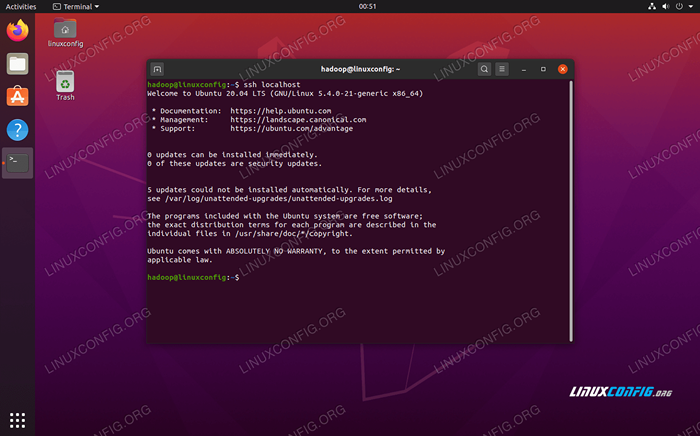 Sshing in das System, ohne auf Passwort aufgefordert zu werden, bedeutet, dass es funktioniert hat
Sshing in das System, ohne auf Passwort aufgefordert zu werden, bedeutet, dass es funktioniert hat
Installieren Sie Hadoop und konfigurieren verwandte XML -Dateien
Besuchen Sie die Website von Apache, um Hadoop herunterzuladen. Sie können diesen Befehl auch verwenden, wenn Sie die Hadoop -Version 3 herunterladen möchten.1.3 Binär direkt:
$ wget https: // downloads.Apache.org/hadoop/Common/Hadoop-3.1.3/Hadoop-3.1.3.Teer.gz
Extrahieren Sie den Download in die Hadoop Home -Verzeichnis des Benutzers mit diesem Befehl:
$ tar -xzvf hadoop -3.1.3.Teer.gz -c /home /hadoop
Einrichten der Umgebungsvariablen
Die folgende Export Befehle konfigurieren die erforderlichen Hadoop -Umgebungsvariablen in unserem System. Sie können alle diese in Ihr Terminal kopieren und einfügen (möglicherweise müssen Sie Zeile 1 ändern, wenn Sie eine andere Version von Hadoop haben):
Export hadoop_home =/home/hadoop/hadoop-3.1.3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin Exportieren Sie Hadoop_opts = "-Djava.Bibliothek.path = $ hadoop_home/lib/native "Quellen Sie die .bashrc Datei in der aktuellen Anmeldesitzung:
$ source ~/.bashrc
Als nächstes werden wir einige Änderungen an der vornehmen Hadoop-Env.Sch Datei, die im Hadoop -Installationsverzeichnis unter gefunden werden kann /etc/hadoop. Verwenden Sie Nano oder Ihren bevorzugten Texteditor, um es zu öffnen:
$ nano ~/hadoop-3.1.3/etc/hadoop/hadoop-env.Sch
Ändere das Java_Home Variable zu dem Ort, an dem Java installiert ist. In unserem System (und wahrscheinlich auch Ihre, wenn Sie Ubuntu 20 ausführen.04 und haben uns bisher mit uns verfolgt), wir ändern diese Linie in:
Exportieren Sie java_home =/usr/lib/jvm/java-8-openjdk-amd64
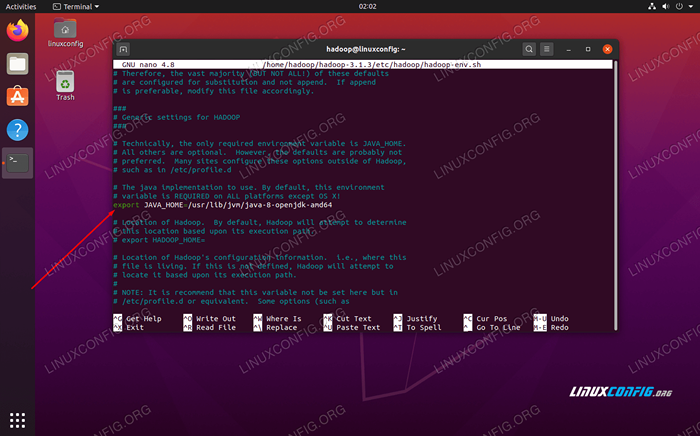 Ändern Sie die Umgebungsvariable java_home
Ändern Sie die Umgebungsvariable java_home Das wird die einzige Änderung sein, die wir hier vornehmen müssen. Sie können Ihre Änderungen in der Datei speichern und sie schließen.
Konfigurationsänderungen in der Kernseite.XML -Datei
Die nächste Änderung, die wir vornehmen müssen, liegt in der Kernstelle.xml Datei. Öffnen Sie es mit diesem Befehl:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Core-Site.xml
Geben Sie die folgende Konfiguration ein, die HDFs anweist, auf Localhost Port 9000 auszuführen und ein Verzeichnis für temporäre Daten einzurichten.
fs.defaultfs hdfs: // localhost: 9000 hadoop.TMP.Dir/Home/Hadoop/Hadooptmpdata 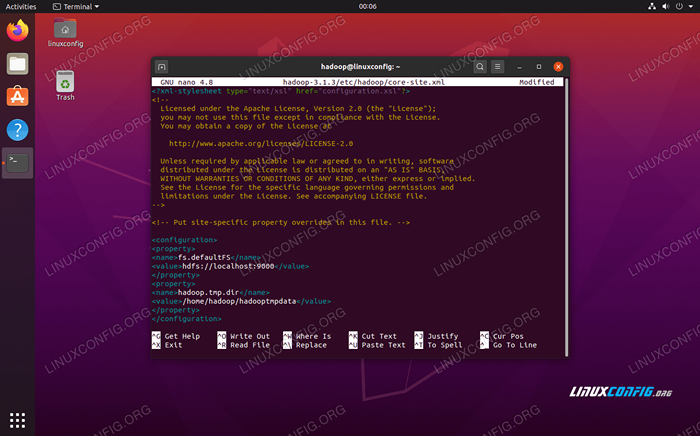 Kernstelle.XML -Konfigurationsdatei ändert sich
Kernstelle.XML -Konfigurationsdatei ändert sich Speichern Sie Ihre Änderungen und schließen Sie diese Datei. Erstellen Sie dann das Verzeichnis, in dem temporäre Daten gespeichert werden:
$ mkdir ~/hadooptmpdata
Konfigurationsänderungen in der HDFS-Site.XML -Datei
Erstellen Sie zwei neue Verzeichnisse für Hadoop, um die Informationen von Namenode und Datanode zu speichern.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datanode
Bearbeiten Sie dann die folgende Datei, um Hadoop mitzuteilen, wo diese Verzeichnisse finden sollen:
$ nano ~/hadoop-3.1.3/etc/Hadoop/HDFS-Site.xml
Nehmen Sie die folgenden Änderungen an der HDFS-Site.xml Datei, bevor Sie sie speichern und schließen:
DFS.Replikation 1 DFS.Name.DIR -Datei: /// Home/Hadoop/HDFS/NAMENODE DFS.Daten.DIR -Datei: /// home/hadoop/hdfs/datanode 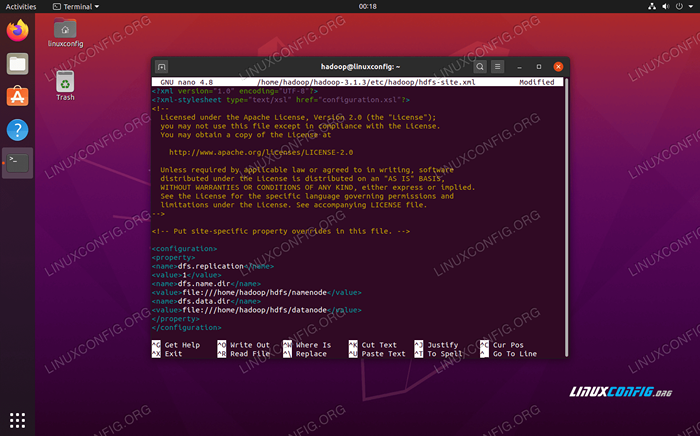 HDFS-Site.XML -Konfigurationsdatei ändert sich
HDFS-Site.XML -Konfigurationsdatei ändert sich Konfigurationsänderungen in Mapred-Site.XML -Datei
Öffnen Sie die MapReduce XML -Konfigurationsdatei mit dem folgenden Befehl:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Mapred-Site.xml
Und vor dem Speichern und Schließen der Datei die folgenden Änderungen vornehmen:
Karte verkleinern.Rahmen.Nennen Sie Garn 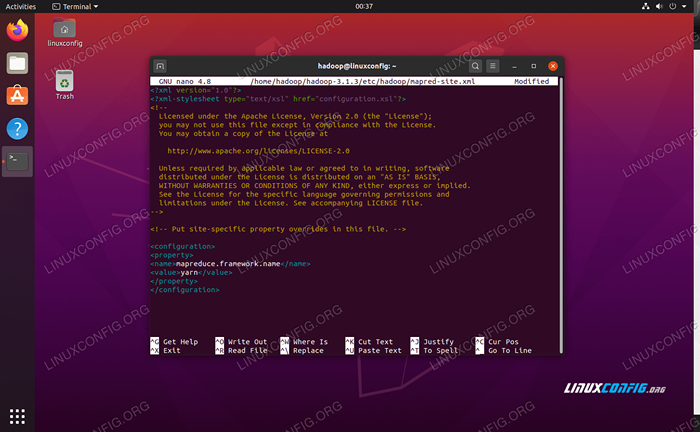 Mapred-Site.XML -Konfigurationsdatei ändert sich
Mapred-Site.XML -Konfigurationsdatei ändert sich Konfigurationsänderungen in der Garnstelle.XML -Datei
Öffnen Sie die Garnkonfigurationsdatei mit dem folgenden Befehl:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Garnstelle.xml
Fügen Sie die folgenden Einträge in diese Datei hinzu, bevor Sie die Änderungen speichern und schließen:
MAPREDUCEYARN.NodeManager.AUX-Service MapReduce_Shuffle 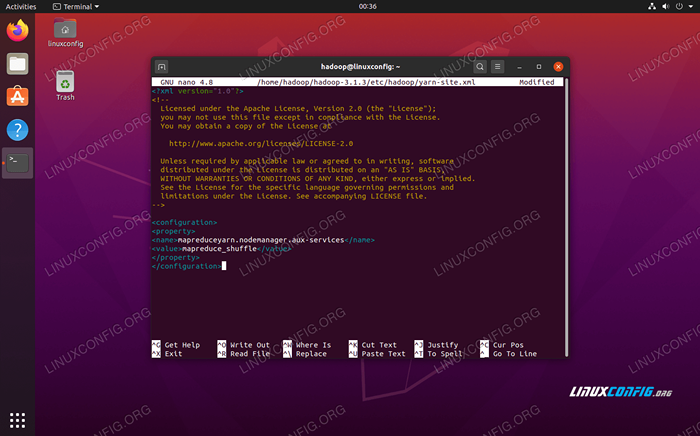 Konfigurationsdatei ändert sich
Konfigurationsdatei ändert sich Starten Sie den Hadoop -Cluster
Bevor wir den Cluster zum ersten Mal verwenden, müssen wir den Namenode formatieren. Sie können dies mit dem folgenden Befehl tun:
$ hdfs namenode -format
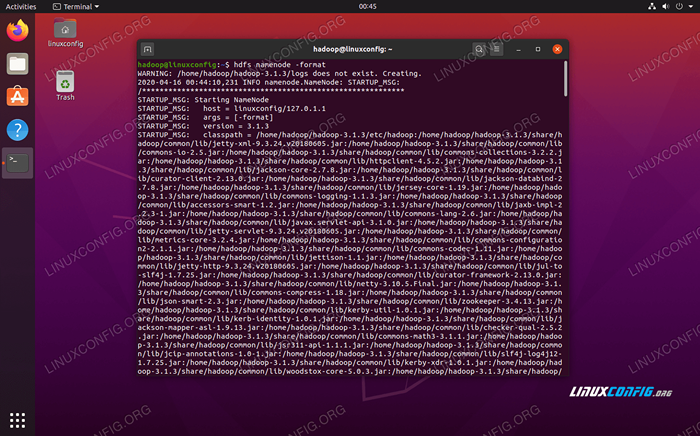 Formatieren des HDFS -Namenode
Formatieren des HDFS -Namenode Ihr Terminal spuckt viele Informationen aus. Solange Sie keine Fehlermeldungen sehen, können Sie annehmen, dass es funktioniert hat.
Starten Sie als nächstes die HDFs mit dem Start-dfs.Sch Skript:
$ start-dfs.Sch
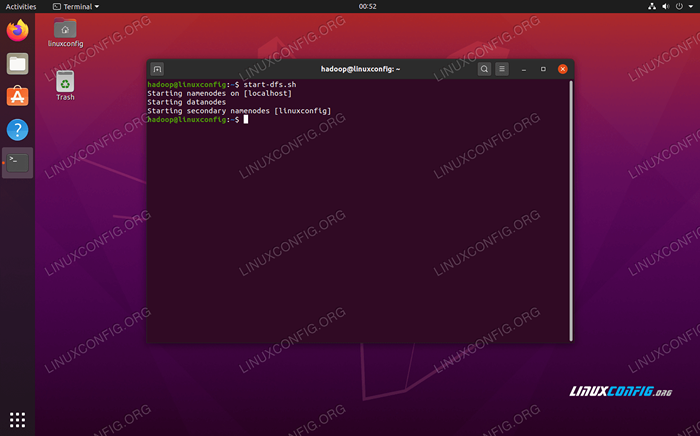 Führen Sie die Start-DFs aus.sh script
Führen Sie die Start-DFs aus.sh script Beginnen Sie nun die Garndienste über die Start marnt.Sch Skript:
$ start marn.Sch
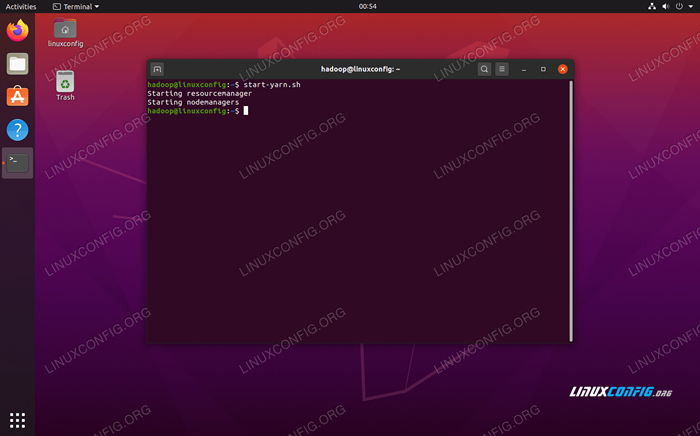 Führen Sie das Startgarn aus.sh script
Führen Sie das Startgarn aus.sh script Um alle Hadoop -Dienste/Dämonen erfolgreich zu überprüfen, können Sie die verwenden JPS Befehl. Dadurch werden alle Prozesse angezeigt, die derzeit Java verwenden, die auf Ihrem System ausgeführt werden.
$ JPS
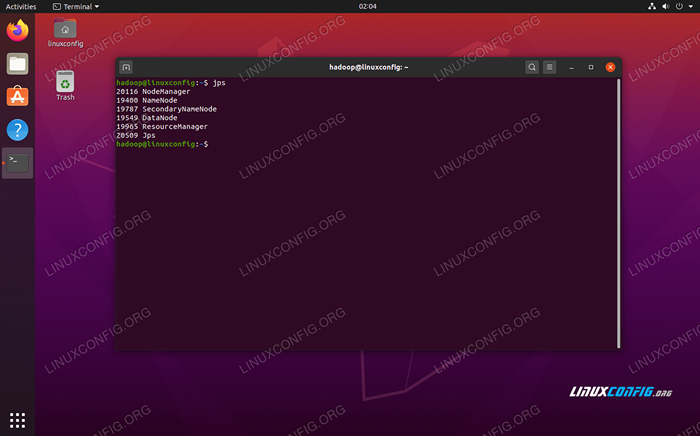 Führen Sie JPS aus, um alle Java -abhängigen Prozesse anzusehen und zu überprüfen, ob die Hadoop -Komponenten ausgeführt werden
Führen Sie JPS aus, um alle Java -abhängigen Prozesse anzusehen und zu überprüfen, ob die Hadoop -Komponenten ausgeführt werden Jetzt können wir die aktuelle Hadoop -Version mit einem der folgenden Befehle überprüfen:
$ hadoop Version
oder
$ HDFS -Version
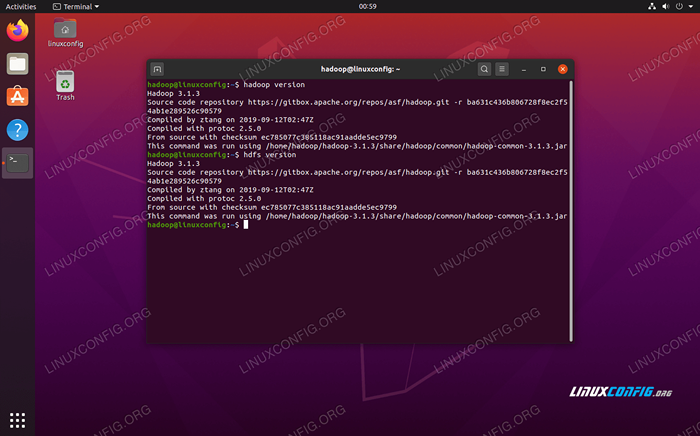 Überprüfen Sie die Hadoop -Installation und die aktuelle Version
Überprüfen Sie die Hadoop -Installation und die aktuelle Version HDFS -Befehlszeilenschnittstelle
Die HDFS -Befehlszeile wird verwendet, um auf HDFs zuzugreifen und Verzeichnisse zu erstellen oder andere Befehle auszugeben, um Dateien und Verzeichnisse zu manipulieren. Verwenden Sie die folgende Befehlssyntax, um einige Verzeichnisse zu erstellen und diese aufzulisten:
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
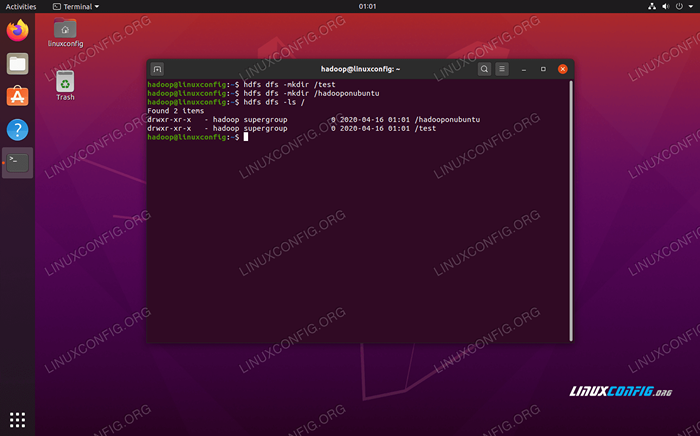 Interaktion mit der HDFS -Befehlszeile
Interaktion mit der HDFS -Befehlszeile Greifen Sie vom Browser auf den Namenode und Garn zuzugreifen
Sie können über einen beliebigen Browser Ihrer Wahl sowohl auf die Web -Benutzeroberfläche für Namenode als auch Garnressourcenmanager wie Mozilla Firefox oder Google Chrome zugreifen.
Navigieren Sie für die namenode Web -Benutzeroberfläche zu http: // hadoop-hostname-or-ip: 50070
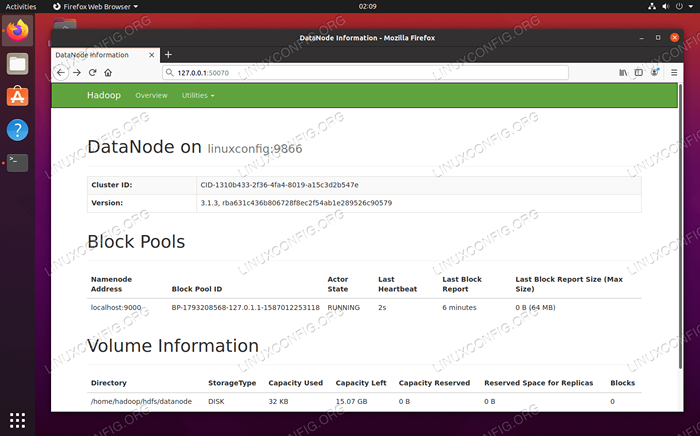 Datanode -Weboberfläche für Hadoop
Datanode -Weboberfläche für Hadoop So navigieren Sie auf die Weboberfläche des Yarn Resource Manager -Weboberfläche, auf der alle derzeit ausgeführten Jobs auf dem Hadoop -Cluster angezeigt werden http: // hadoop-hostname-or-ip: 8088
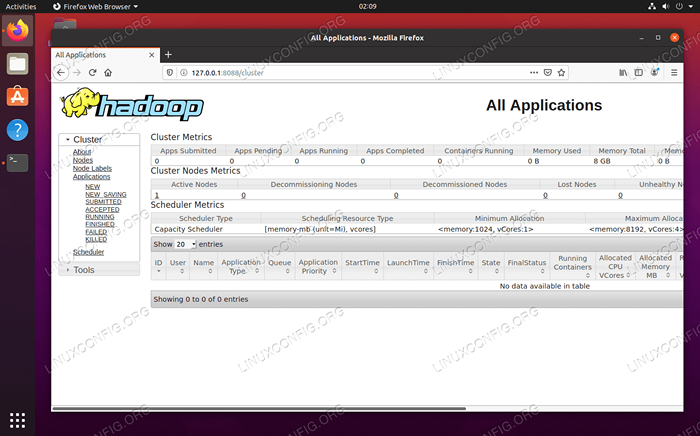 Garnressourcenmanager -Weboberfläche für Hadoop
Garnressourcenmanager -Weboberfläche für Hadoop Abschluss
In diesem Artikel haben wir gesehen, wie Hadoop auf einem einzigen Knotencluster in Ubuntu 20 installiert werden kann.04 FOSSA FOSSA. Hadoop bietet uns eine wirksame Lösung für den Umgang mit Big Data, sodass wir Cluster für die Speicherung und Verarbeitung unserer Daten verwenden können. Es erleichtert unser Leben, wenn wir mit großen Datensätzen mit seiner flexiblen Konfiguration und einer bequemen Weboberfläche arbeiten.
Verwandte Linux -Tutorials:
- Dinge zu installieren auf Ubuntu 20.04
- So erstellen Sie einen Kubernetes -Cluster
- Ubuntu 20.04 WordPress mit Apache -Installation
- So installieren Sie Kubernetes auf Ubuntu 20.04 fokale Fossa Linux
- Wie man mit der Woocommerce -REST -API mit Python arbeitet
- Verschachtelte Schleifen in Bash -Skripten
- Dinge zu tun nach der Installation Ubuntu 20.04 fokale Fossa Linux
- Mastering -Bash -Skriptschleifen beherrschen
- So installieren Sie Kubernetes auf Ubuntu 22.04 Jammy Quallen…
- Eine Einführung in Linux -Automatisierung, Tools und Techniken
- « Erstellen Sie ein bootfähiges Ubuntu 20.04 USB -Stick auf MS Windows 10
- Ubuntu 20.04 Systemanforderungen »